Flink CDC同步MySQL数据到Iceberg实践
介绍
Flink CDC: 捕获数据库完整的变更日志记录增、删、改等所有数据. Flink在1.11版本开始引入了Flink CDC功能,并且同时支持Table & SQL两种形式。Flink SQL CDC是以SQL的形式编写实时任务,并对CDC数据进行实时解析同步。相比于传统的数据同步方案,该方案在实时性、易用性等方面有了极大的改善。
Flink CDC 同步优势:
业务解耦:无需入侵业务,和业务完全解耦,也就是业务端无感知数据同步的存在。
性能消耗:业务数据库性能消耗小,数据同步延迟低。
同步易用:使用SQL方式执行CDC同步任务,极大的降低使用维护门槛。
数据完整:完整的数据库变更记录,不会丢失任何记录,Flink 自身支持 Exactly Once。
数据湖: 支持存储多种原始数据格式、多种计算引擎、高效的元数据统一管理和海量统一数据存储。
Apache Iceberg: 是一个大规模数据分析的开放表格式, 是数据湖的一种解决方案.
Iceberg 设计特点:
- ACID:不会读到不完整的commit数据,基于乐观锁实现,支持并发commit,支持Row-level delete,支持upsert操作。
- 增量快照:Commit后的数据即可见,在Flink实时入湖场景下,数据可见根据checkpoint的时间间隔来确定的,增量形式也可回溯历史快照。
- 开放的表格式:对于一个真正的开放表格式,支持多种数据存储格式,如:parquet、orc、avro等,支持多种计算引擎,如:Spark、Flink、Hive、Trino/Presto。
- 流批接口支持:支持流式写入、批量写入,支持流式读取、批量读取
环境准备
准备Flink 、mysql docker镜像 测试环境:
docker-compose.yml:
version: '2.1'
services:
sql-client:
user: flink:flink
image: yuxialuo/flink-sql-client:1.13.2.v1
depends_on:
- jobmanager
- mysql
environment:
FLINK_JOBMANAGER_HOST: jobmanager
MYSQL_HOST: mysql
volumes:
- shared-tmpfs:/tmp/iceberg
jobmanager:
user: flink:flink
image: flink:1.13.2-scala_2.11
ports:
- "8081:8081"
command: jobmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
volumes:
- shared-tmpfs:/tmp/iceberg
taskmanager:
user: flink:flink
image: flink:1.13.2-scala_2.11
depends_on:
- jobmanager
command: taskmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager.numberOfTaskSlots: 2
volumes:
- shared-tmpfs:/tmp/iceberg
mysql:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
volumes:
shared-tmpfs:
driver: local
driver_opts:
type: "tmpfs"
device: "tmpfs"
在docker-compose.yml文件同目录下启动flink 组件:
docker-compose up -d
该命令将以 detached 模式自动启动 Docker Compose 配置中定义的所有容器。
可以通过访问 http://localhost:8081/ 来查看 Flink 是否运行正常
本教程需要的 jar 包都已经被打包进 SQL-Client 容器中了,
如果你想要在自己的 Flink 环境运行本教程,需要下载下面列出的包并且把它们放在 Flink 所在目录的 lib 目录下,即 FLINK_HOME/lib/。
flink-sql-connector-mysql-cdc-2.1.0.jar
flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
iceberg-flink-1.13-runtime-0.13.0-SNAPSHOT.jar
当 Iceberg 0.13.0 版本发布后,你也可以在 apache official repository 下载到支持 Flink 1.13 的 iceberg-flink-runtime jar 包。
准备测试数据
进入 MySQL 容器中:
docker-compose exec mysql mysql -uroot -p123456
创建数据和表,并填充数据:
创建两个不同的数据库,并在每个数据库中创建两个表,作为 user 表分库分表下拆分出的表。
CREATE DATABASE db_1;
USE db_1;
CREATE TABLE user_1 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234","user_110@foo.com");
CREATE TABLE user_2 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_2 VALUES (120,"user_120","Shanghai","123567891234","user_120@foo.com");
CREATE DATABASE db_2;
USE db_2;
CREATE TABLE user_1 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234", NULL);
CREATE TABLE user_2 (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
);
INSERT INTO user_2 VALUES (220,"user_220","Shanghai","123567891234","user_220@foo.com");
在 Flink SQL CLI 中使用 Flink DDL 创建表:
首先,使用如下的命令进入 Flink SQL CLI 容器中:
docker-compose exec sql-client ./sql-client
开启 checkpoint
Checkpoint 默认是不开启的,我们需要开启 Checkpoint 来让 Iceberg 可以提交事务。
并且,mysql-cdc 在 binlog 读取阶段开始前,需要等待一个完整的 checkpoint 来避免 binlog 记录乱序的情况。
-- Flink SQL
-- 每隔 3 秒做一次 checkpoint
Flink SQL> SET execution.checkpointing.interval = 3s;
创建 MySQL 分库分表 source 表
创建 source 表 user_source 来捕获MySQL中所有 user 表的数据,在表的配置项 database-name , table-name 使用正则表达式来匹配这些表。
并且,user_source 表也定义了 metadata 列来区分数据是来自哪个数据库和表。
CREATE TABLE user_source (
database_name STRING METADATA VIRTUAL,
table_name STRING METADATA VIRTUAL,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysql',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'db_[0-9]+',
'table-name' = 'user_[0-9]+'
);
创建 Iceberg sink 表
创建 sink 表 all_users_sink,用来将数据加载至 Iceberg 中。
在这个 sink 表,考虑到不同的 MySQL 数据库表的 id 字段的值可能相同,我们定义了复合主键 (database_name, table_name, id)。
CREATE TABLE all_users_sink (
database_name STRING,
table_name STRING,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (database_name, table_name, `id`) NOT ENFORCED
) WITH (
'connector'='iceberg',
'catalog-name'='iceberg_catalog',
'catalog-type'='hadoop',
'warehouse'='file:///tmp/iceberg/warehouse',
'format-version'='2'
);
流式写入 Iceberg
使用下面的 Flink SQL 语句将数据从 MySQL 写入 Iceberg 中:
INSERT INTO all_users_sink select * from user_source;
述命令将会启动一个流式作业,源源不断将 MySQL 数据库中的全量和增量数据同步到 Iceberg 中。
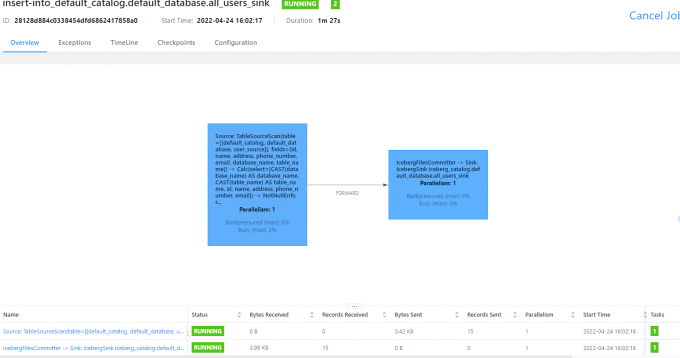
然后我们就可以使用如下的命令看到 Iceberg 中的写入的文件:
docker-compose exec sql-client tree /tmp/iceberg/warehouse/default_database/
/tmp/iceberg/warehouse/default_database/
└── all_users_sink
├── data
│ ├── 00000-0-84b83e87-0e98-48da-8871-4de54d802dc5-00009.parquet
│ ├── 00000-0-84b83e87-0e98-48da-8871-4de54d802dc5-00011.parquet
│ ├── 00000-0-84b83e87-0e98-48da-8871-4de54d802dc5-00511.parquet
│ └── 00000-0-84b83e87-0e98-48da-8871-4de54d802dc5-00512.parquet
└── metadata
├── 6785c966-67e3-43e0-876d-cfc2b77424b4-m0.avro
├── c4f04e0f-5f1d-4cd3-a5eb-4f423390011d-m0.avro
├── snap-1060385011870418792-1-df87d81d-004f-44d6-acca-1c77e5383647.avro
├── snap-1125901484026564419-1-c8e6142a-4702-4bf9-bb6c-937261910d39.avro
├── snap-1465929231731371144-1-cd480baf-a496-4f69-bb11-379299782e7a.avro
├── snap-1535675730396165219-1-eddfe40e-27bd-4a7a-97b0-191da77d4019.avro
├── snap-2621077481890393128-1-fdb33dc2-97a9-4472-bda4-fe0192a983c4.avro
├── snap-2886091127939856900-1-94d854db-2081-43b4-9bb3-11f9d0377503.avro
├── snap-3343920335928350948-1-19669bbb-7b82-4218-83ea-05c90429ff01.avro
├── snap-3566691522613506207-1-59e74ad7-a32e-427f-83c1-640d98b58d24.avro
├── snap-3843624394887137001-1-fef2b9b7-b7de-4ece-951b-eb1856a2d195.avro
├── snap-4100501778549948477-1-6785c966-67e3-43e0-876d-cfc2b77424b4.avro
├── snap-4248879694079296194-1-441e1ce8-6a10-4ebc-82b4-7abf62bc385b.avro
├── snap-445137311357959788-1-4e97b44e-a626-402b-b6ca-613e5252ed15.avro
├── snap-4453685821727449894-1-a5d3ced5-9d98-419a-aeda-a89e0184aa91.avro
├── snap-4652826435458483424-1-144e1141-8da3-450d-ba4d-01858befea48.avro
├── snap-4827514150229893384-1-db19f736-209b-44b0-9a4a-a1ecb8532817.avro
├── snap-5160869656962357717-1-522bdf2b-fd9d-4c81-9995-6c598e3112a2.avro
├── snap-5328679998683573777-1-befea0d5-0312-41db-ab33-04d2f71aa29c.avro
├── snap-5468995844667874005-1-4c1db744-6eb6-4c62-a5ce-6162b64ed429.avro
├── snap-7392671775005889691-1-f0e79868-ae06-4fe8-9a8e-e0b9f2fe2c12.avro
├── snap-7448354638185933171-1-621e2364-508e-47bf-83d0-5c7d72d160c6.avro
├── snap-7449633500954413534-1-3c673f73-381e-4917-af09-ce06e75995ee.avro
├── snap-7808424372668354882-1-a874a13c-32cc-4b4b-ab45-3042cad872f8.avro
├── snap-8487607088527724113-1-86dbb914-c564-4841-a536-be834a09b09d.avro
├── snap-882048647352933559-1-c7d1058c-1d60-4624-b592-2d8c9f208946.avro
├── snap-9092189266221057431-1-c4f04e0f-5f1d-4cd3-a5eb-4f423390011d.avro
├── snap-9149158390097592825-1-fd9e8dd3-519c-4b48-b78c-181ea0fd2aaf.avro
├── v1.metadata.json
├── v10.metadata.json
├── v11.metadata.json
├── v12.metadata.json
├── v13.metadata.json
├── v14.metadata.json
├── v15.metadata.json
├── v16.metadata.json
├── v17.metadata.json
├── v18.metadata.json
├── v19.metadata.json
├── v2.metadata.json
├── v20.metadata.json
├── v21.metadata.json
├── v22.metadata.json
├── v23.metadata.json
├── v24.metadata.json
├── v25.metadata.json
├── v26.metadata.json
├── v27.metadata.json
├── v3.metadata.json
├── v4.metadata.json
├── v5.metadata.json
├── v6.metadata.json
├── v7.metadata.json
├── v8.metadata.json
├── v9.metadata.json
└── version-hint.text
使用下面的 Flink SQL 语句查询表 all_users_sink 中的数据:

修改 MySQL 中表的数据,Iceberg 中的表 all_users_sink 中的数据也将实时更新:
(3.1) 在 db_1.user_1 表中插入新的一行
--- db_1
INSERT INTO db_1.user_1 VALUES (111,"user_111","Shanghai","123567891234","user_111@foo.com");
(3.2) 更新 db_1.user_2 表的数据
--- db_1
UPDATE db_1.user_2 SET address='Beijing' WHERE id=120;
(3.3) 在 db_2.user_2 表中删除一行
--- db_2
DELETE FROM db_2.user_2 WHERE id=220;
每执行一步,在 Flink Client CLI 中使用 SELECT * FROM all_users_sink 查询表 all_users_sink 来看到数据的变化。

从 Iceberg 的最新结果中可以看到新增了(db_1, user_1, 111)的记录,(db_1, user_2, 120)的地址更新成了 Beijing,且(db_2, user_2, 220)的记录被删除了,与我们在 MySQL 做的数据更新完全一致。
最后, 关闭所有容器:
docker-compose down
接下来,将调研如何将Iceberg 与Hive、SparkSQL 整合,读取和分析Flink CDC写入Iceberg中的数据.
参考
- Iceberg 实践 | 基于 Flink CDC 打通数据实时入湖:https://jishuin.proginn.com/p/763bfbd5bdbe
- Flink CDC 系列 - 同步 MySQL 分库分表,构建 Iceberg 实时数据湖:https://developer.aliyun.com/article/841222
Flink CDC同步MySQL数据到Iceberg实践的更多相关文章
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- Logstash使用jdbc_input同步Mysql数据时遇到的空时间SQLException问题
今天在使用Logstash的jdbc_input插件同步Mysql数据时,本来应该能搜索出10条数据,结果在Elasticsearch中只看到了4条,终端中只给出了如下信息 [2017-08-25T1 ...
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- logstash增量同步mysql数据到es
本篇本章地址:https://www.cnblogs.com/Thehorse/p/11601013.html 今天我们来讲一下logstash同步mysql数据到es 我认为呢,logstash是众 ...
- 同步mysql数据到ElasticSearch的最佳实践
Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据.ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全 ...
- flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
- 快速同步mysql数据到redis中
MYSQL快速同步数据到Redis 举例场景:存储游戏玩家的任务数据,游戏服务器启动时将mysql中玩家的数据同步到redis中. 从MySQL中将数据导入到Redis的Hash结构中.当然,最直接的 ...
- logstash同步mysql数据失败
问题描述 前提: 项目采用Elasticsearch提供搜索服务,Mysql提供存储服务,通过Logstash将Mysql中数据同步到Elasticsearch. 问题: 使用logstash-j ...
随机推荐
- Meissel_Lehmer模板
复杂度 \(O(n^\frac 23)\),计算 \(1\sim n\) 的素数个数 #define div(a, b) (1.0 * (a) / (b)) #define half(x) (((x) ...
- CH01_WPF概述
第1章:WPF概述 本章目标 了解Windows图形演化 了解WPF高级API 了解分辨率无关性概念 了解WPF体系结构 了解WPF 4.5 WPF概述 欢迎使用 Windows Presenta ...
- 【牛客刷题】HJ15 求int型正整数在内存中存储时1的个数
题目链接 题倒是很简单,最开始用了这么一种解法: package main import "fmt" func main() { a := 0 fmt.Scan(&a) s ...
- diff 输出解释
diff 最原始的 diff 我们先编写两个文件: f1: 1 2 3 4 5 6 7 8 9 f2: 1 2 3 4 5 66 7 8 9 然后我们进行比较: diff f1 f2 6c6 < ...
- python get 请求接口 忽略证书验证
import requests # 请求接口 import ssl context = ssl.create_default_context() context.check_hostname = Fa ...
- 页面多次跳转加载时,window.onscroll方法失效问题解决
1. vue mounted 方法中,写有滚动监听方法,为A页面 window.scroll = function () { .... } 从A页面跳转到B页面,再从B页面跳转回A页面, window ...
- CLion 2022.2.4破解教程详细图解mac,windows,linux均适用
下载与安装 此教程为CLion 2022.2.4 破解教程,且此教程以及下面提供的破解补丁适用与2022.2以后的新版本. 2022年11月10日亲测有效,mac与windows均测试完美破解 CLi ...
- 不升级 POI 版本,如何生成符合新版标准的Excel 2007文件
开心一刻 记得小时候,家里丢了钱,是我拿的,可爸妈却一口咬定是弟弟拿的 爸爸把弟弟打的遍体鳞伤,弟弟气愤的斜视着我 我不敢直视弟弟,目光转向爸爸说到:爸爸,你看他,好像还不服 问题描述 项目基于 PO ...
- face-api.js 学习笔记
参考 Build Real Time Face Detection With JavaScript (youtube get started) face-api.js - JavaScript API ...
- opencascade源码学习之HLRAlgo包 -HLRAlgo
类 HLRAlgo 前言 在给定的投影中,为了达到工业设计.图纸需要的精度,可以删除隐藏的线条.为此,隐藏 线路移除组件提供两个算法: HLRBRep_Algo和HLRBRep_PolyAlgo. 这 ...