源码方式本地化部署deepseek和量化
前置条件
1.python环境,安装教程:https://www.python.org/downloads/
2.wsl环境(Windows系统),安装教程:https://learn.microsoft.com/zh-cn/windows/wsl/install
第一步下载大模型
模型仓库:https://huggingface.co/collections/deepseek-ai/deepseek-r1-678e1e131c0169c0bc89728d

第二步配置环境
1.安装cuda
https://www.cnblogs.com/zijie1024/articles/18375637
2.安装pytorch
使用命令nvidia-smi,查看cuda版本
在官网选择对应版本下载
官网:https://pytorch.org/get-started/locally/

得到命令:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu12
如果pip3安装失败就改为pip
3.安装依赖包


pip install bitsandbytes
pip install transformers
pip install accelerate
如果提示:ModuleNotFoundError: No module named 'torch'
执行:pip install --upgrade pip setuptools wheel
第三步运行
1.直接运行
try:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
except ImportError as e:
print(f"导入库时发生错误: {e},请确保 transformers 和 torch 库已正确安装。")
else:
try:
# 模型和分词器的本地路径
model_path = "."
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path) # 加载模型
model = AutoModelForCausalLM.from_pretrained(model_path) # 检查是否可以使用 GPU 并设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cuda":
print("Using GPU for inference.")
else:
print("Using CPU for inference.")
model.to(device) # 示例输入
input_text = "你是哪个模型?"
inputs = tokenizer(input_text, return_tensors="pt").to(device) # 模型推理
with torch.no_grad(): # 禁用梯度计算,减少内存占用
outputs = model.generate(**inputs, max_length=2000, num_return_sequences=1,
no_repeat_ngram_size=2, temperature=1.0, top_k=50, top_p=0.95) generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Generated text:", generated_text) except FileNotFoundError:
print(f"模型文件未找到,请检查路径: {model_path}")
except Exception as e:
print(f"发生错误: {e}")
finally:
# 如果是在 GPU 上运行,尝试清理缓存
if device == "cuda":
torch.cuda.empty_cache()
2.量化后运行
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch # 模型路径
model_name = "."
quantized_model_dir = "deepseek-1.5b-quantized" # 配置量化参数
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # 使用 4 位量化
bnb_4bit_compute_dtype=torch.float16, # 计算精度
bnb_4bit_use_double_quant=True, # 使用双量化
llm_int8_enable_fp32_cpu_offload=True # 启用 CPU 卸载
) # 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quantization_config,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name) # 保存量化后的模型
model.save_pretrained(quantized_model_dir)
tokenizer.save_pretrained(quantized_model_dir) print(f"Quantized model saved to: {quantized_model_dir}") # 执行运行模型的py,也可以手动运行,注意修改模型路径为量化后的模型路径
with open("run.py", "r") as file:
script_content = file.read() exec(script_content)
运行效果
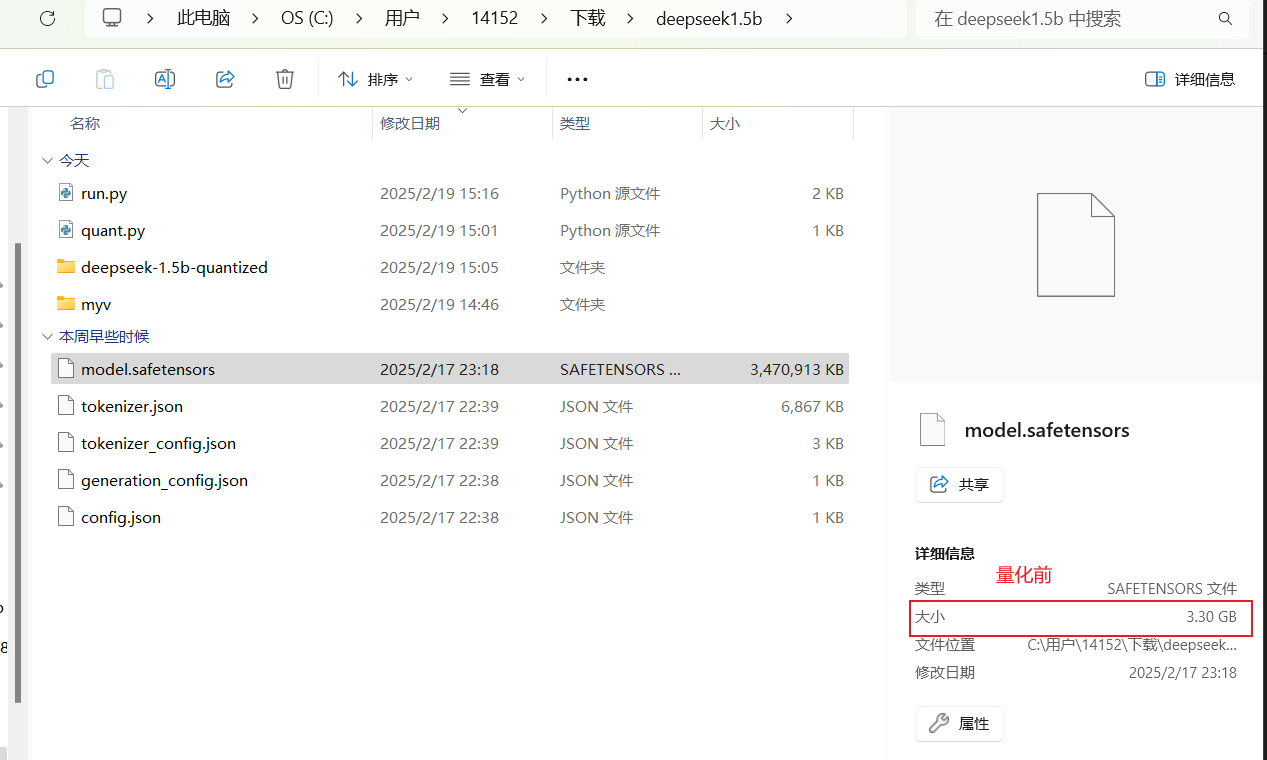
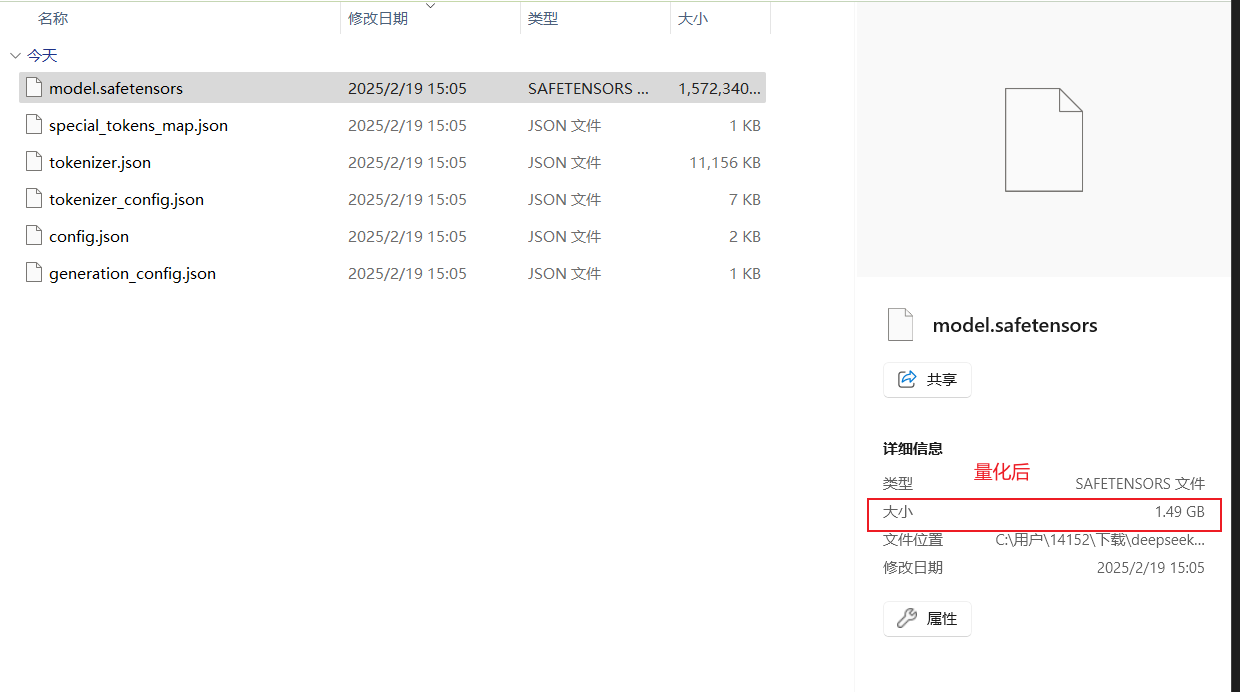
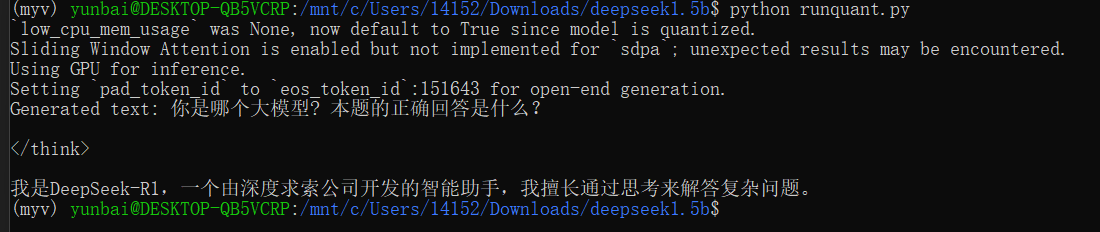
源码方式本地化部署deepseek和量化的更多相关文章
- Spark1.0.0 源码编译和部署包生成
问题导读:1.如何对Spark1.0.0源码编译?2.如何生成Spark1.0的部署包?3.如何获取包资源? Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对 ...
- 使用yum源的方式单机部署MySQL8.0.13
使用yum源的方式单机部署MySQL8.0.13 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 基本上开源的软件都支持三种安装方式,即rmp方式安装,源码安装和二进制方式安装.在 ...
- 第6章 RTX 操作系统源码方式移植
以下内容转载自安富莱电子: http://forum.armfly.com/forum.php 本章教程为大家将介绍 RTX 操作系统源码方式移植,移植工作比较简单,只需要用户添加需要的源码文件即可, ...
- centos7下源码方式安装gitlab8.9+发送邮件+ldap
CentOS7下源码方式安装gitlab 环境描述 操作系统: centos7 redis: >=2.8 mysql >=5.5.14 git >=2.7.4 架构设计 一台gitl ...
- 源码方式安装 lrzsz 库
我们都知道安装了lrzsz工具的linux系统环境: 在shell里可以非常方便的上传和下载linux里面的文件: 通常的安装方式: yum install lrzsz sudo apt-get in ...
- win10下通过编译源码方式在chrome中成功安装react-devtools开发工具插件
win10下通过编译源码方式在chrome中成功安装react-devtools开发工具插件 1.去git上下载react-devtools文件到本地,https://github.com/fac ...
- 01.LNMP架构-Nginx源码包编译部署详细步骤
操作系统:CentOS_Server_7.5_x64_1804.iso 部署组件:Pcre+Zlib+Openssl+Nginx 操作步骤: 一.创建目录 [root@localhost ~]# mk ...
- 02.LNMP架构-MySQL源码包编译部署详细步骤
操作系统:CentOS_Server_7.5_x64_1804.iso 部署组件:Cmake+Boost+MySQL 操作步骤: 一.安装依赖组件 [root@localhost ~]# yum -y ...
- 源码方式安装 lrzsz库
源码方式安装 lrzsz库:https://www.cnblogs.com/cocoajin/p/11731787.html 我们都知道安装了lrzsz工具的linux系统环境,在shell里可以非常 ...
- Linux上生产环境源码方式安装配置postgresql12
1.Linux上源码方式安装postgresql12 01.准备操作系统环境 echo "192.168.1.61 tsepg61" >> /etc/hosts mou ...
随机推荐
- 3D饼图
1.实现思路 Echarts本身没有这类图形,可以使用其扩展echarts-gl进行绘制,echarts-gl曲面图可以完成这类需求 <script src="https://cdn. ...
- openEuler欧拉部署Jenkins
一.系统优化 关闭防火墙 systemctl stop firewalld systemctl disable firewalld 二.安装Jenkins dnf -y install docker ...
- 各种各样的 Host Builder
各种各样的 Host Buider If you're building for the web or writing a distributed application, you might nee ...
- JAVA-通过大疆TSDK的API直接获取红外图片温度信息
一.前言 看过很多关于大疆红外图片用TSDK取温的方式,但是网上能搜到的大部分教程都是通过官方下载文件smple编译出来的程序来取温,如果这样做,虽然确实也能够实现目的,但不得不说,不但会降低运行速度 ...
- TB交易开拓者_趋势跟踪策略_多品种对冲_递进优化回测_A0001188020期货量化策略
如果您需要代写技术指标公式, 请联系我. 龙哥QQ:591438821 龙哥微信:Long622889 也可以把您的通达信,文华技术指标改成TB交易开拓者的自动交易量化策略. 众所周知,投资界有基本面 ...
- Qt/C++如何选择使用哪一种地图内核/不同地图的优缺点/百度高德腾讯地图/天地图/谷歌地图
一.前言说明 最近花了大半年时间,专门研究这个地图组件,几乎把各种地图的官网的手册翻了个遍,亲自写代码验证了一遍,各种API函数接口和功能全部实战一遍,然后从中提取共性,做出了基类,以及通用函数类,子 ...
- Qt编写安防视频监控系统66-子模块10网页浏览
一.前言 网页浏览模块,用于传入一个网页地址,打开对应的网页进行浏览,可用于网页展示信息,支持多个,可以自行增加,代码中演示了一个.此模块的用途属于添砖加瓦润色用的,比如有一个牛逼的3D网页,机器人. ...
- Qt编写的项目作品4-输入法V2019
一.功能特点 未采用Qt系统层输入法框架,独创输入切换机制. 纯QWidget编写,支持任何目标平台(亲测windows.linux.嵌入式linux等),支持任意Qt版本(亲测Qt4.6.0到Qt5 ...
- 关于Qt数据库相关开发的一些经验总结
一.前言 近期花了两个多月时间,将数据库相关的代码重新封装成了各种轮子(这条路必须打通,打通以后,相关项目只需要引入这个组件pri即可),测试了从Qt4.7到Qt6.1的各种版本,测试了odbc.sq ...
- 在 Ubuntu 上搭建 MinIO 服务器
在日常开发时,如果有文件上传下载的需求(比如用户头像),但是又不想使用对象存储,那么自己搭建一个 MinIO 服务器是一个比较简单的解决方案. MinIO 是一个基于 Apache License v ...