(六)6.12 Neurons Networks from self-taught learning to deep network
self-taught learning 在特征提取方面完全是用的无监督的方法,对于有标记的数据,可以结合有监督学习来对上述方法得到的参数进行微调,从而得到一个更加准确的参数a。
在self-taught learning中,首先用 无标记数据训练一个sparse autoencoder,这样用对于原始输入x,经过sparse autoencoder得到隐层特征a:
这样对于分类问题,目标是预测样本的类别标号  。现在的标注数据集
。现在的标注数据集 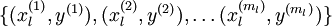 ,包含
,包含 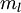 个标注样本。此前已经说明,可以利用稀疏自编码器获得的特征
个标注样本。此前已经说明,可以利用稀疏自编码器获得的特征 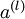 来替代原始特征。这样就可获得训练数据集
来替代原始特征。这样就可获得训练数据集 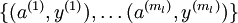 。最终,训练出一个从特征
。最终,训练出一个从特征 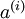 到类标号
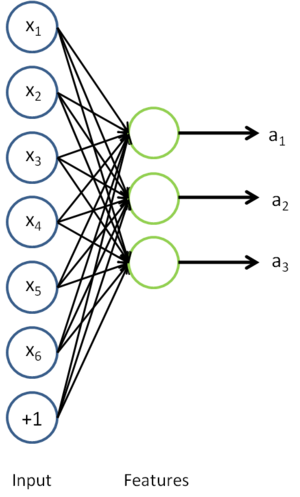
到类标号 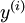 的 logistic 分类器。为说明这一过程,用下图描述 logistic 回归单元(橘黄色)。
的 logistic 分类器。为说明这一过程,用下图描述 logistic 回归单元(橘黄色)。
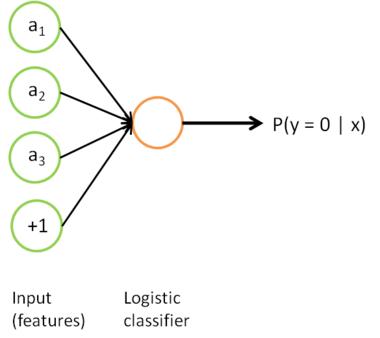
把上述两个步骤结合结合起来,便得到:
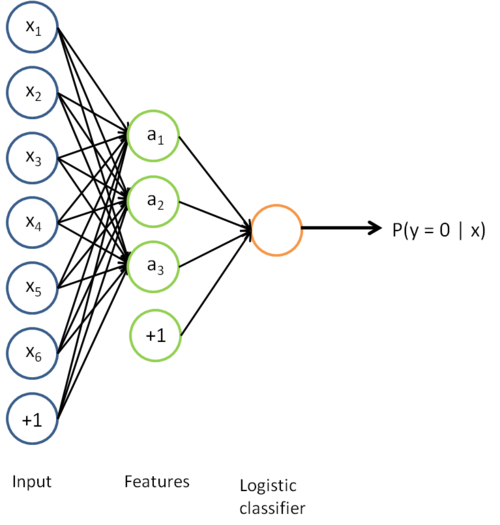
该模型的参数通过两个步骤训练获得:在该网络的第一层,将输入  映射至隐藏单元激活量
映射至隐藏单元激活量 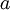 的权值
的权值 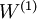 可以通过稀疏自编码器训练过程获得。在第二层,将隐藏单元 映射至输出 的权值
可以通过稀疏自编码器训练过程获得。在第二层,将隐藏单元 映射至输出 的权值 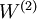 可以通过 logistic 回归或 softmax 回归训练获得。
可以通过 logistic 回归或 softmax 回归训练获得。
这个最终分类器整体上显然是一个大的神经网络。因此,在训练获得模型最初参数(利用自动编码器训练第一层,利用 logistic/softmax 回归训练第二层)之后,我们可以进一步修正模型参数,进而降低训练误差。具体来说,我们可以对参数进行微调(fun-tuning),在现有参数的基础上采用梯度下降或者 L-BFGS 来降低已标注样本集 上的训练误差。
使用微调时,初始的非监督特征学习步骤(也就是自动编码器和logistic分类器训练)有时候被称为预训练。微调的作用在于,已标注数据集也可以用来修正权值 ,这样可以对隐藏单元所提取的特征 做进一步调整。
需要注意的是:通常仅在有大量已标注训练数据的情况下使用微调。在这样的情况下,微调能显著提升分类器性能。然而,如果有大量未标注数据集(用于非监督特征学习/预训练),却只有相对较少的已标注训练集,微调的作用非常有限。
之前所提到的network一般是三层,下面讲逐渐考虑多层的网络,通过加深网络层数,我们可以计算更多复杂的输入特征。因为每一个隐藏层可以对上一层的输出进行非线性变换,因此深度神经网络拥有比“浅层”网络更加优异的表达能力(例如可以学习到更加复杂的函数关系)。
注意神经网络应该使用非线性的激活函数,因为线性激活函数的表达能力有限,多层线性函数的组合得到的仍然是线性的表达能力,因此激活函数是线性情况下,加深网络层数然并卵,并不会增加表达能力。
加深网络的优点:
一、网络每加深一层得到的表达能力将是之前的指数倍,比如说用k层神经网络能学习到的函数(且每层网络节点个数时多项式的)如果要用k-1层神经网络来学习,则这k-1层神经网络节点的个数必须是k的指数倍的庞大数字。
二、不同层的网络学习到的特征是由最底层到最高层慢慢上升的。比如在图像的学习中,第一个隐含层层网络可能学习的是边缘特征,第二隐含层就学习到的是轮廓,后面的就会更高级有可能是图像目标中的一个部位,也就是是底层隐含层学习底层特征,高层隐含层学习高层特征。
之前研究者们主要使用的学习算法是:随机初始化深度网络的权重,然后使用有监督的目标函数在有标签的训练集 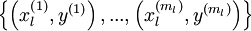 上进行训练。
上进行训练。
这样有一些缺点:
一、数据获取问题,使用上面提到的方法,我们需要依赖于有标签的数据才能进行训练。然而有标签的数据通常是稀缺的,因此对于许多问题,我们很难获得足够多的样本来拟合一个复杂模型的参数。例如,考虑到深度网络具有强大的表达能力,在不充足的数据上进行训练将会导致过拟合
二、使用监督学习方法来对浅层网络(只有一个隐藏层)进行训练通常能够使参数收敛到合理的范围内。但是当用这种方法来训练深度网络的时候,并不能取得很好的效果。比如使用监督学习方法训练神经网络时,通常会涉及到求解一个高度非凸的优化问题(例如最小化训练误差 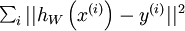 ,其中参数
,其中参数 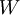 是要优化的参数。对深度网络而言,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。
是要优化的参数。对深度网络而言,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。
三、梯度扩散(gradient diffuse),梯度下降法(以及相关的L-BFGS算法等)在使用随机初始化权重的深度网络上效果不好的技术原因是:梯度会变得非常小,当使用反向传播方法计算导数的时候,随着网络的深度的增加,反向传播的梯度(从输出层到网络的最初几层)的幅度值会急剧地减小。结果就造成了整体的损失函数相对于最初几层的权重的导数非常小。这样,当使用梯度下降法的时候,最初几层的权重变化非常缓慢,以至于它们不能够从样本中进行有效的学习。这种问题通常被称为“gradient diffuse”.
梯度扩散导致的问题是:当神经网络中的最后几层含有足够数量神经元的时候,可能单独这几层就足以对有标签数据进行建模,而不用最初几层的帮助。因此,对所有层都使用随机初始化的方法训练得到的整个网络的性能将会与训练得到的浅层网络(仅由深度网络的最后几层组成的浅层网络)的性能相似。
最后补充下,现在随着深度学习的发展,pre-training 变得不再那么重要,因为学者们发现只要数据量足够多,最后深度学习都能给出一个较优的解,并且一些非全连接网络比如LSTM或者CNN等也很难进行pre-training。
(六)6.12 Neurons Networks from self-taught learning to deep network的更多相关文章
- (六) 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
- (六) 6.2 Neurons Networks Backpropagation Algorithm
今天得主题是BP算法.大规模的神经网络可以使用batch gradient descent算法求解,也可以使用 stochastic gradient descent 算法,求解的关键问题在于求得每层 ...
- (六)6.11 Neurons Networks implements of self-taught learning
在machine learning领域,更多的数据往往强于更优秀的算法,然而现实中的情况是一般人无法获取大量的已标注数据,这时候可以通过无监督方法获取大量的未标注数据,自学习( self-taught ...
- (六) 6.3 Neurons Networks Gradient Checking
BP算法很难调试,一般情况下会隐隐存在一些小问题,比如(off-by-one error),即只有部分层的权重得到训练,或者忘记计算bais unit,这虽然会得到一个正确的结果,但效果差于准确BP得 ...
- CS229 6.12 Neurons Networks from self-taught learning to deep network
self-taught learning 在特征提取方面完全是用的无监督的方法,对于有标记的数据,可以结合有监督学习来对上述方法得到的参数进行微调,从而得到一个更加准确的参数a. 在self-taug ...
- CS229 6.11 Neurons Networks implements of self-taught learning
在machine learning领域,更多的数据往往强于更优秀的算法,然而现实中的情况是一般人无法获取大量的已标注数据,这时候可以通过无监督方法获取大量的未标注数据,自学习( self-taught ...
- (六)6.10 Neurons Networks implements of softmax regression
softmax可以看做只有输入和输出的Neurons Networks,如下图: 其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵. 对损失函数J(θ)的形式有: 算法 ...
- CS229 6.10 Neurons Networks implements of softmax regression
softmax可以看做只有输入和输出的Neurons Networks,如下图: 其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵. 对损失函数J(θ)的形式有: 算法 ...
- CS229 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
随机推荐
- POJ 2101
#include <iostream> #include <algorithm> #include <cmath> using namespace std; int ...
- Android 源码 判断网络数据类型
private final void updateDataNetType(int slotId) { int tempDataNetType; NetworkType tempDataNetType3 ...
- React的CSS
1.代码 <!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset="U ...
- iOS 深拷贝和浅拷贝
注意,本文只说结论不说过程 1. 对于系统的非容器类对象,我们可以认为,如果对一不可变对象复制,copy是指针复制(浅拷贝)和mutableCopy就是对象复制(深拷贝).如果是对可变对象复制,都是深 ...
- ActiveMQ简单介绍以及安装
概述 首先简单的介绍一下MQ,MQ英文名MessageQueue,中文名也就是大家用的消息队列,干嘛用的呢,说白了就是一个消息的接受和转发的容器,可用于消息推送. ActiveMQ是Apache所提供 ...
- PV UV
定义 PV: Page View 页面浏览量或点击量,用户每次刷新即被计算一次. UV: Unique Visitor 就是有多少个IP数量.就是指的有多少人在访问你的店.每个人用的电脑 ...
- Java中使用验证码和二维码
资源 需要: jelly-core-1.7.0.GA.jar 网站: http://lychie.github.io/products.html 将下载下来的 jelly-core-1.7.0 ...
- CNN卷积神经网络在自然语言处理的应用
摘要:CNN作为当今绝大多数计算机视觉系统的核心技术,在图像分类领域做出了巨大贡献.本文从计算机视觉的用例开始,介绍CNN及其在自然语言处理中的优势和发挥的作用. 当我们听到卷积神经网络(Convol ...
- 从SDE库文件手工删除SDE图层(转载)
转载自:http://gis-conquer.blog.sohu.com/164467560.html 一.前言 虽然Catalog能解决这种问题,但是在特殊情况下也许这种方法有点用途. ...
- 标准类型内建函数 str()和 repr() (及 `` 运算符) 简单介绍
内建函数 str() 和 repr() 或反引号运算符(``) 可以方便的以字符串的方式获取对象的内容.类型.数值属性等信息.str()函数得到的字符串可读性好, 而repr()函数得到的字符串通常可 ...