RasaGPT对话系统的工作原理
RasaGPT 结合了 Rasa 和 Langchain 这 2 个开源项目,当超出 Rasa 现有意图(out_of_scope)的时候,就会执行 ActionGPTFallback,本质上就是利用 Langchain 做了一个 RAG,调用 LLM API。RasaGPT 涉及的技术栈比较多而复杂,包括 Rasa、Langchain、LlamaIndex、Telegram、PostgresSQL、PGVector、Ngrok、FastAPI、Docker、docker-compose、Dozzle 等。尽管对项目做了简化[3],删除了不容易实现的部分,但仍是一次失败的实践,各种原因没有完整运行起来。不过 RasaGPT 为结合 Rasa 和 Langchain 提供了一种思路,接下来重点是把 Rasa 和 Langchain-Chatchat 进行对接。
一.RasaGPT 及特点

RasaGPT 是一个建立在 Rasa 和 Langchain 之上的无头 LLM chatbot 平台(无头简单理解就是没有界面)。它是 Rasa 和 Telegram 的样板文件(Boilerplate)和参考实现,利用 LLM 库(如 Langchain)进行索引、检索和上下文注入。RasaGPT 可以直接投入使用,很多实施上的麻烦事都已经被解决了,这样就不必亲自处理,包括:
使用FastAPI创建自己的专有机器人端点,包括文档上传和"训练"管道的设置。 如何集成Langchain/LlamaIndex和Rasa。 与LLM库的库冲突以及传递metadata。 在MacOS上使用Docker支持运行Rasa。 通过ngrok进行与聊天机器人的反向代理。 使用自定义模式而非使用Langchain的高度倾向的PGVector类来实现pgvector。 添加多租户支持(Rasa原生并不支持此功能),在Rasa和后端/应用程序之间进行会话和metadata的传递。
Rasa 是一个开源 (Python) 机器学习框架,用于自动执行基于文本和语音的对话:NLU、对话管理、连接到 Slack、Facebook 等,创建聊天机器人和语音助手。LangChain 主要功能是围绕 LLM 快速构建应用程序和管道,通过与外部数据和知识源的结合,可以提高 LLM 的应用效率和范围。
1.完整应用程序和 API
使用Langchain,LLM在任意语料库上学习 通过FastAPI上传文档并进行训练 支持文档版本控制,上传时自动进行重新训练 通过FastAPI和SQLModel自定义自己的异步端点和数据库模型 机器人确定是否需要进行人工接管 机器人根据用户问题和自动响应自动生成标签 通过Swagger和Redoc提供完整的API文档 包含PGAdmin,以便浏览数据库 在启动时自动生成Ngrok端点,以便机器人始终可以通过https://t.me/yourbotname访问 通过pgvector和Postgres函数嵌入相似性搜索构建到Postgres中 包含虚拟数据供测试和实验 无限的用例,从帮助台、客户支持、测验、e-learning、角色扮演游戏等
2.Rasa 集成
构建在Rasa之上,这是开源聊天平台的黄金标准 支持MacOS M1/M2通过Docker(标准Rasa镜像不支持MacOS架构) 支持Telegram,轻松集成Slack、Whatsapp、Line、短信等 使用Huggingface的NLU模型(如BERT)或使用Keras、Tensorflow等库/框架,备用为OpenAI GPT,建立复杂的对话管道
3.灵活性
使用Langchain扩展主体、记忆等能力 模式支持多租户、会话、数据存储 自定义智能体个性 保存所有聊天历史并从所有交互中创建embeddings,以适应未来的检索策略 从知识库语料库和客户反馈中自动生成embeddings
二.RasaGPT 安装
1.软件要求
Python 3.9 Docker和Docker compose 开放AI(API密钥) Telegram(机器人凭证) Ngrok(身份验证令牌) Make(MacOS / Windows) SQL模型
2.Docker 安装过程步骤
检查以确保有.env可用的 数据库初始化为pgvector 数据库模型创建数据库模式 训练Rasa模型,使其准备好运行 使用Rasa设置ngrok,以便Telegram有一个返回API服务器的Webhook 设置Rasa操作服务器,以便Rasa可以与RasaGPT API对话 数据库通过seed.py方式填充虚拟数据
3.docker-compose.yml 快速启动
使用 docker-compose.yml 文件快速启动,如果使用的是 Linux 或 Windows,则需要将 docker-compose.yml 文件中的 Dockerfilekhalosa/rasa-aarch64:3.5.2 名称修改为 rasa/rasa:latest。
# 获取源码
git clone https://github.com/paulpierre/RasaGPT.git
cd RasaGPT
# 根据需要配置.env文件
cp .env-example .env
# 自动安装和运行RasaGPT
make install
说明:可以输入 make 查看更多选项列表,安装完成后再次执行命令 make run 运行。完整安装日志参考: https://app.warp.dev/block/vflua6Eue29EPk8EVvW8Kd
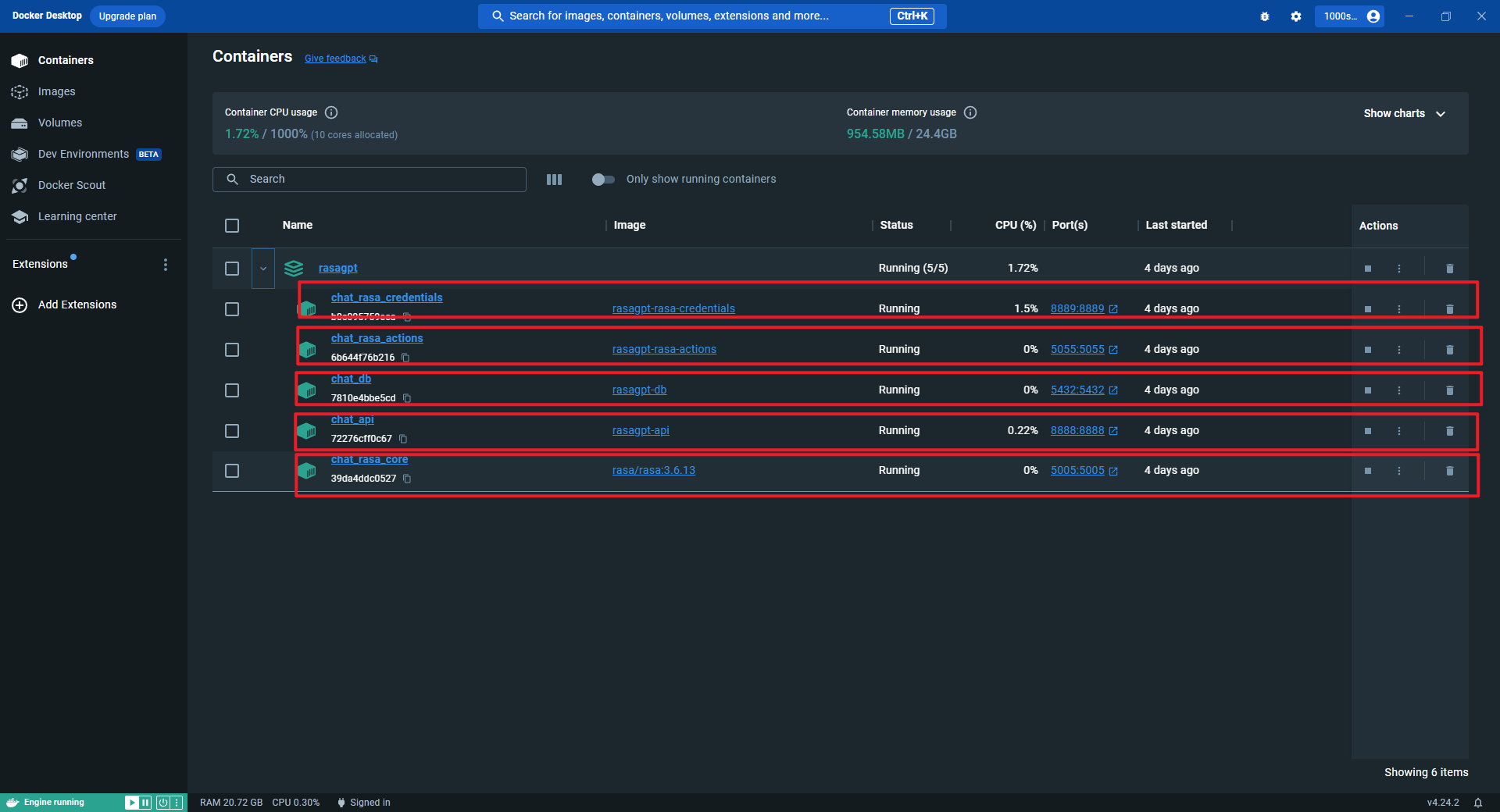
4.所有容器列表
chat_api
chat_ngrok
chat_rasa_core
chat_rasa_actions
chat_rasa_credentials
chat_db
chat_pgadmin
chat_dozzle
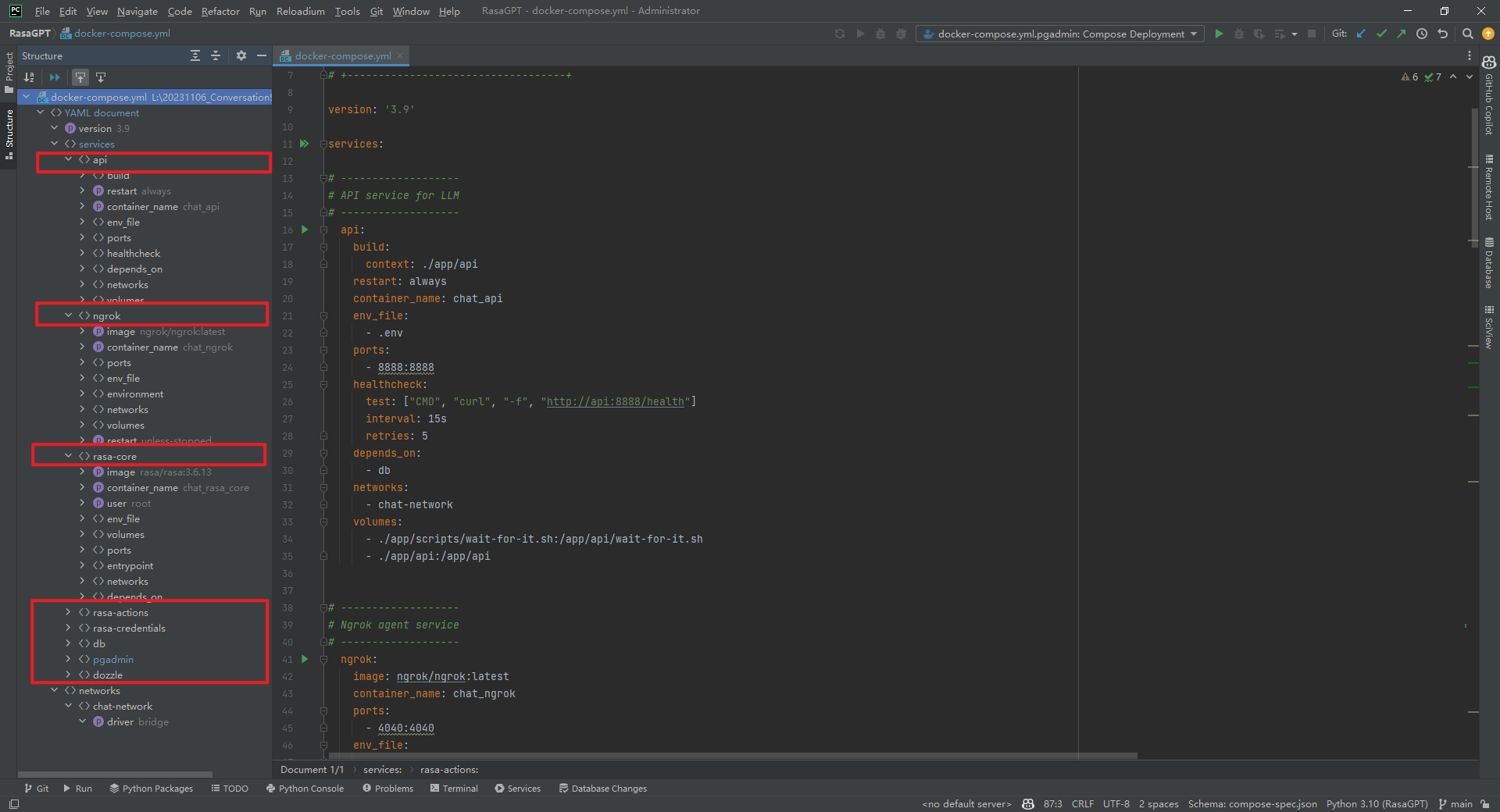
简化后的 RasaGPT 项目[3]包括:chat_rasa_core(模型)、chat_api(LLM 接口)、chat_db(数据库)、chat_rasa_actions(action 服务)、chat_rasa_credentials(凭证)。如下所示:
三.操作说明
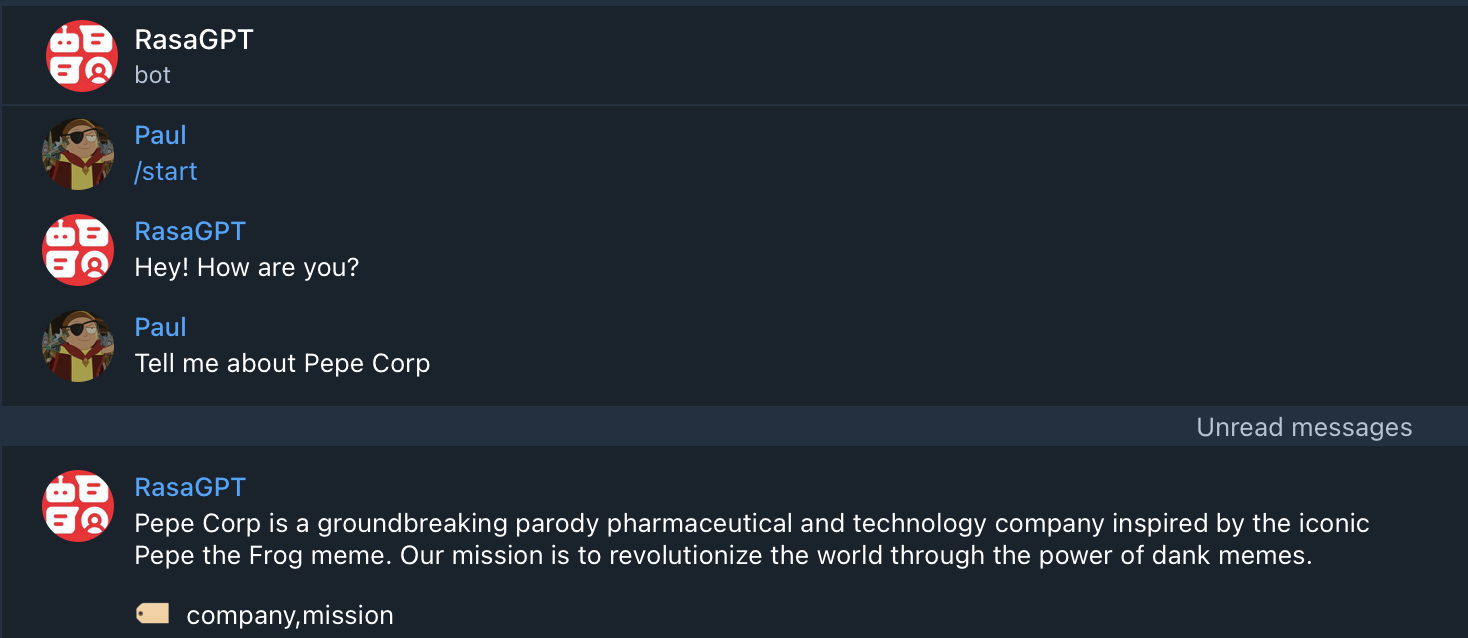
1.对话操作
2.查看日志
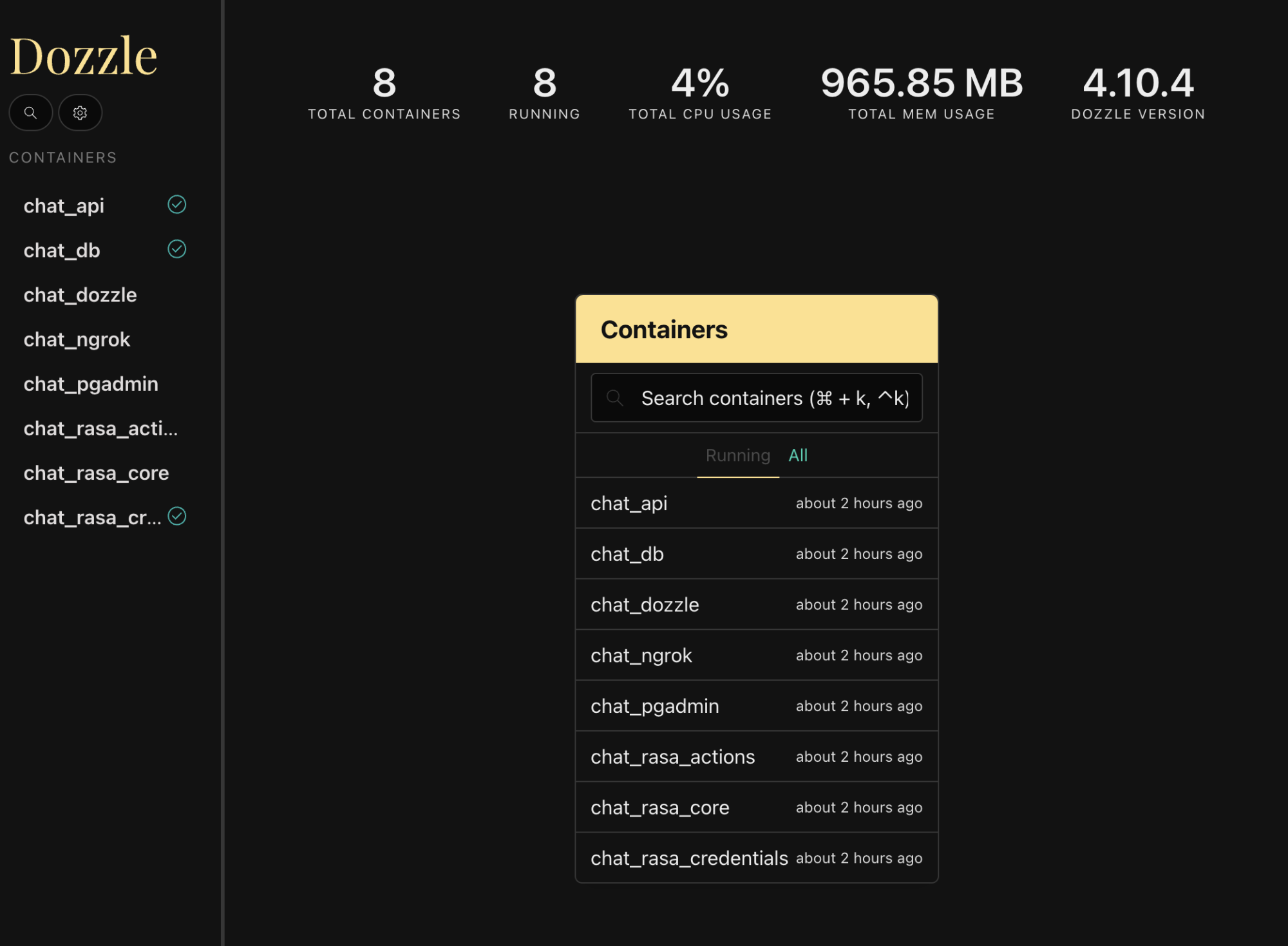
可以通过访问 https://localhost:9999/查看所有日志,它将显示所有 Docker 容器的实时日志。如下所示:
3.API 文档
可以通过访问 https://localhost:8888/docs 查看 API 端点文档。在这个页面上,可以创建和更新实体,以及将文档上传到知识库。如下所示:
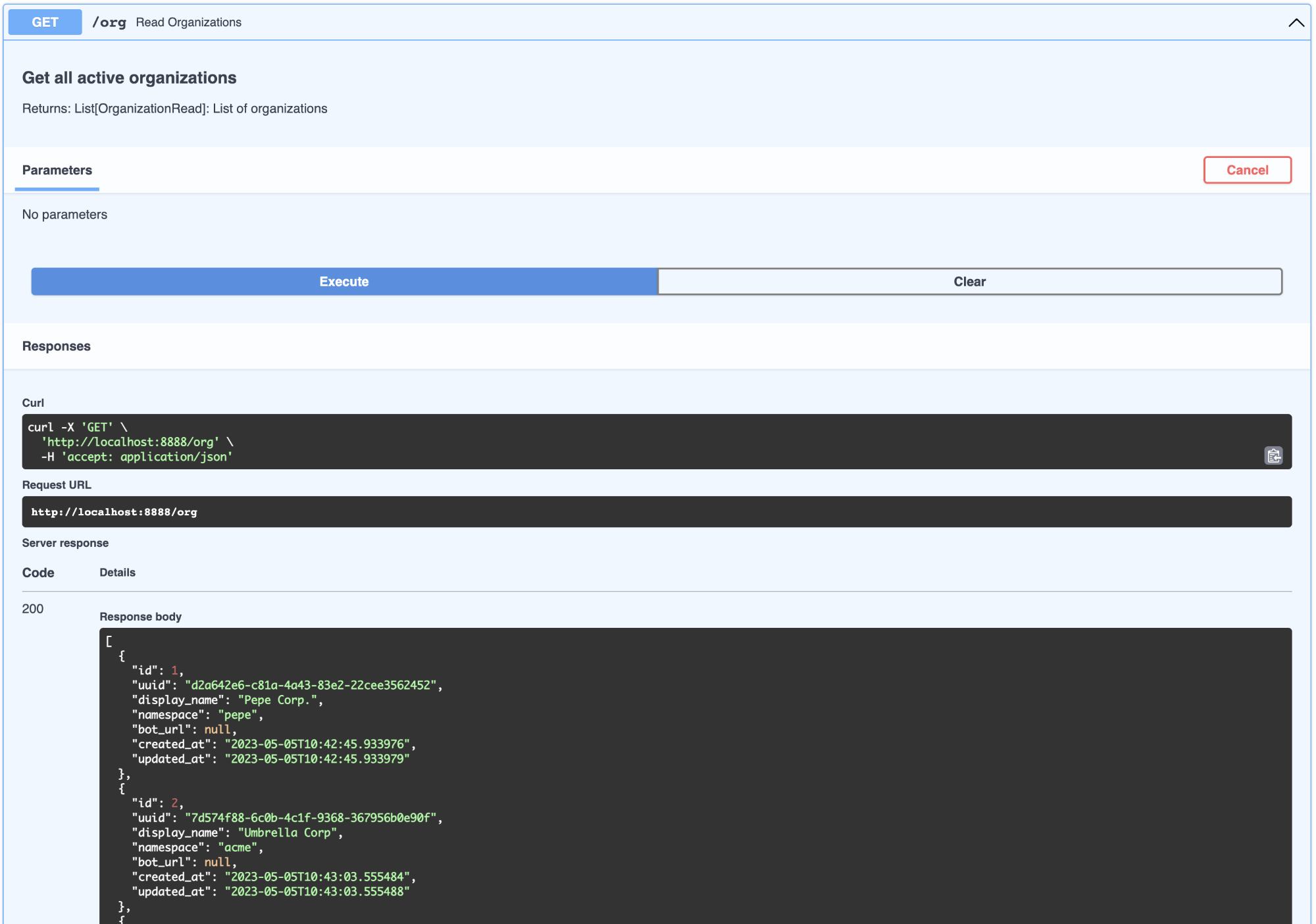
3.1.Organization(组织)
这可以被认为是 SaaS/多租户中的客户公司。默认情况下,已提供虚拟组织列表。如下所示:
[
{
"id": 1,
"uuid": "d2a642e6-c81a-4a43-83e2-22cee3562452",
"display_name": "Pepe Corp.",
"namespace": "pepe",
"bot_url": null,
"created_at": "2023-05-05T10:42:45.933976",
"updated_at": "2023-05-05T10:42:45.933979"
},
{
"id": 2,
"uuid": "7d574f88-6c0b-4c1f-9368-367956b0e90f",
"display_name": "Umbrella Corp",
"namespace": "acme",
"bot_url": null,
"created_at": "2023-05-05T10:43:03.555484",
"updated_at": "2023-05-05T10:43:03.555488"
},
{
"id": 3,
"uuid": "65105a15-2ef0-4898-ac7a-8eafee0b283d",
"display_name": "Cyberdine Systems",
"namespace": "cyberdine",
"bot_url": null,
"created_at": "2023-05-05T10:43:04.175424",
"updated_at": "2023-05-05T10:43:04.175428"
},
{
"id": 4,
"uuid": "b7fb966d-7845-4581-a537-818da62645b5",
"display_name": "Bluth Companies",
"namespace": "bluth",
"bot_url": null,
"created_at": "2023-05-05T10:43:04.697801",
"updated_at": "2023-05-05T10:43:04.697804"
},
{
"id": 5,
"uuid": "9283d017-b24b-4ecd-bf35-808b45e258cf",
"display_name": "Evil Corp",
"namespace": "evil",
"bot_url": null,
"created_at": "2023-05-05T10:43:05.102546",
"updated_at": "2023-05-05T10:43:05.102549"
}
]
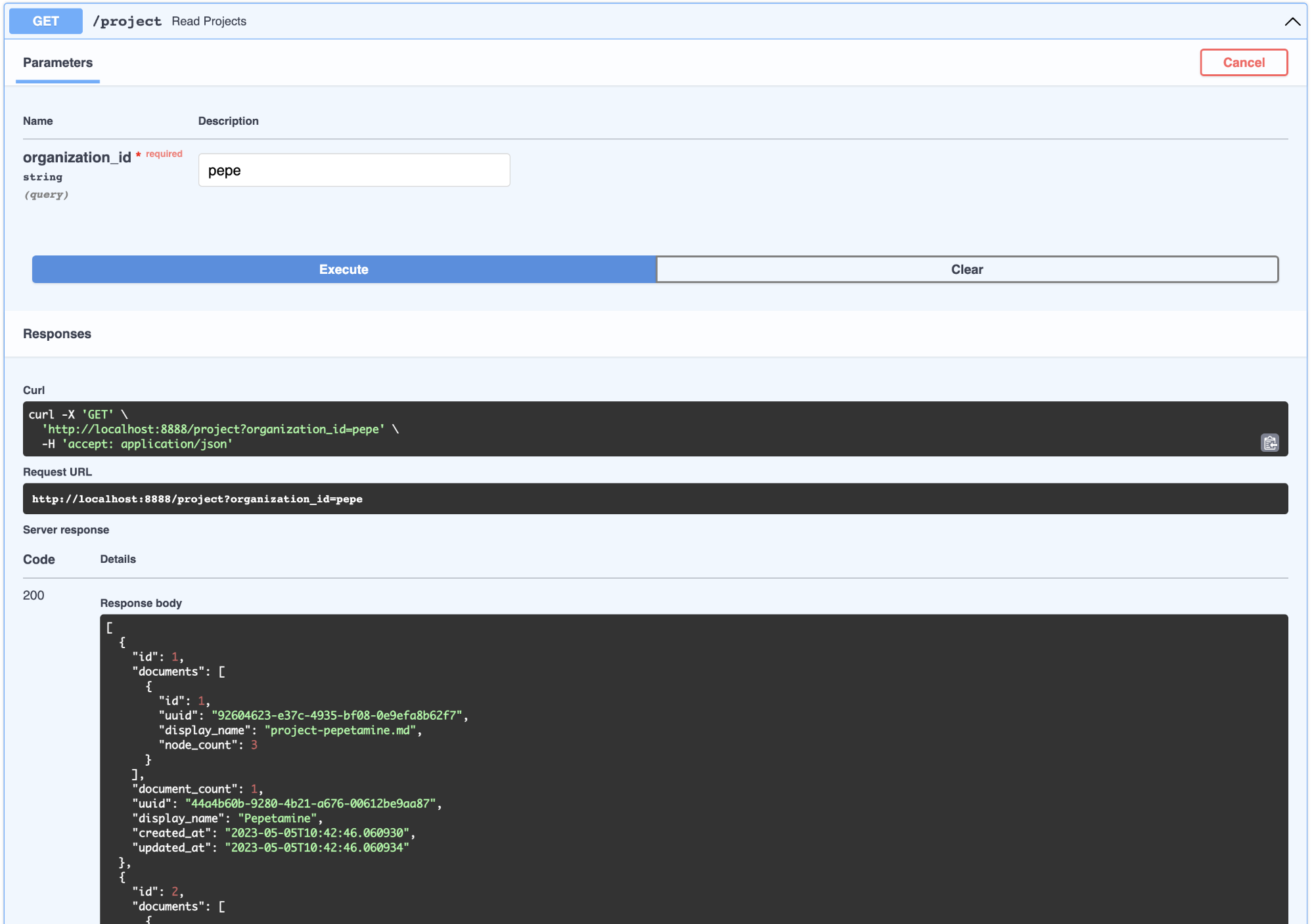
3.2.Project(项目)
这可以被视为属于公司的产品。可以查看属于组织的项目列表。如下所示:
[
{
"id": 1,
"documents": [
{
"id": 1,
"uuid": "92604623-e37c-4935-bf08-0e9efa8b62f7",
"display_name": "project-pepetamine.md",
"node_count": 3
}
],
"document_count": 1,
"uuid": "44a4b60b-9280-4b21-a676-00612be9aa87",
"display_name": "Pepetamine",
"created_at": "2023-05-05T10:42:46.060930",
"updated_at": "2023-05-05T10:42:46.060934"
},
{
"id": 2,
"documents": [
{
"id": 2,
"uuid": "b408595a-3426-4011-9b9b-8e260b244f74",
"display_name": "project-frogonil.md",
"node_count": 3
}
],
"document_count": 1,
"uuid": "5ba6b812-de37-451d-83a3-8ccccadabd69",
"display_name": "Frogonil",
"created_at": "2023-05-05T10:42:48.043936",
"updated_at": "2023-05-05T10:42:48.043940"
},
{
"id": 3,
"documents": [
{
"id": 3,
"uuid": "b99d373a-3317-4699-a89e-90897ba00db6",
"display_name": "project-kekzal.md",
"node_count": 3
}
],
"document_count": 1,
"uuid": "1be4360c-f06e-4494-bf20-e7c73a56f003",
"display_name": "Kekzal",
"created_at": "2023-05-05T10:42:49.092675",
"updated_at": "2023-05-05T10:42:49.092678"
},
{
"id": 4,
"documents": [
{
"id": 4,
"uuid": "94da307b-5993-4ddd-a852-3d8c12f95f3f",
"display_name": "project-memetrex.md",
"node_count": 3
}
],
"document_count": 1,
"uuid": "1fd7e772-365c-451b-a7eb-4d529b0927f0",
"display_name": "Memetrex",
"created_at": "2023-05-05T10:42:50.184817",
"updated_at": "2023-05-05T10:42:50.184821"
},
{
"id": 5,
"documents": [
{
"id": 5,
"uuid": "6deff180-3e3e-4b09-ae5a-6502d031914a",
"display_name": "project-pepetrak.md",
"node_count": 4
}
],
"document_count": 1,
"uuid": "a389eb58-b504-48b4-9bc3-d3c93d2fbeaa",
"display_name": "PepeTrak",
"created_at": "2023-05-05T10:42:51.293352",
"updated_at": "2023-05-05T10:42:51.293355"
},
{
"id": 6,
"documents": [
{
"id": 6,
"uuid": "2e3c2155-cafa-4c6b-b7cc-02bb5156715b",
"display_name": "project-memegen.md",
"node_count": 5
}
],
"document_count": 1,
"uuid": "cec4154f-5d73-41a5-a764-eaf62fc3db2c",
"display_name": "MemeGen",
"created_at": "2023-05-05T10:42:52.562037",
"updated_at": "2023-05-05T10:42:52.562040"
},
{
"id": 7,
"documents": [
{
"id": 7,
"uuid": "baabcb6f-e14c-4d59-a019-ce29973b9f5c",
"display_name": "project-neurokek.md",
"node_count": 5
}
],
"document_count": 1,
"uuid": "4a1a0542-e314-4ae7-9961-720c2d092f04",
"display_name": "Neuro-kek",
"created_at": "2023-05-05T10:42:53.689537",
"updated_at": "2023-05-05T10:42:53.689539"
},
{
"id": 8,
"documents": [
{
"id": 8,
"uuid": "5be007ec-5c89-4bc4-8bfd-448a3659c03c",
"display_name": "org-about_the_company.md",
"node_count": 5
},
{
"id": 9,
"uuid": "c2b3fb39-18c0-4f3e-9c21-749b86942cba",
"display_name": "org-board_of_directors.md",
"node_count": 3
},
{
"id": 10,
"uuid": "41aa81a9-13a9-4527-a439-c2ac0215593f",
"display_name": "org-company_story.md",
"node_count": 4
},
{
"id": 11,
"uuid": "91c59eb8-8c05-4f1f-b09d-fcd9b44b5a20",
"display_name": "org-corporate_philosophy.md",
"node_count": 4
},
{
"id": 12,
"uuid": "631fc3a9-7f5f-4415-8283-78ff582be483",
"display_name": "org-customer_support.md",
"node_count": 3
},
{
"id": 13,
"uuid": "d4c3d3db-6f24-433e-b2aa-52a70a0af976",
"display_name": "org-earnings_fy2023.md",
"node_count": 5
},
{
"id": 14,
"uuid": "08dd478b-414b-46c4-95c0-4d96e2089e90",
"display_name": "org-management_team.md",
"node_count": 3
}
],
"document_count": 7,
"uuid": "1d2849b4-2715-4dcf-aa68-090a221942ba",
"display_name": "Pepe Corp. (company)",
"created_at": "2023-05-05T10:42:55.258902",
"updated_at": "2023-05-05T10:42:55.258904"
}
]
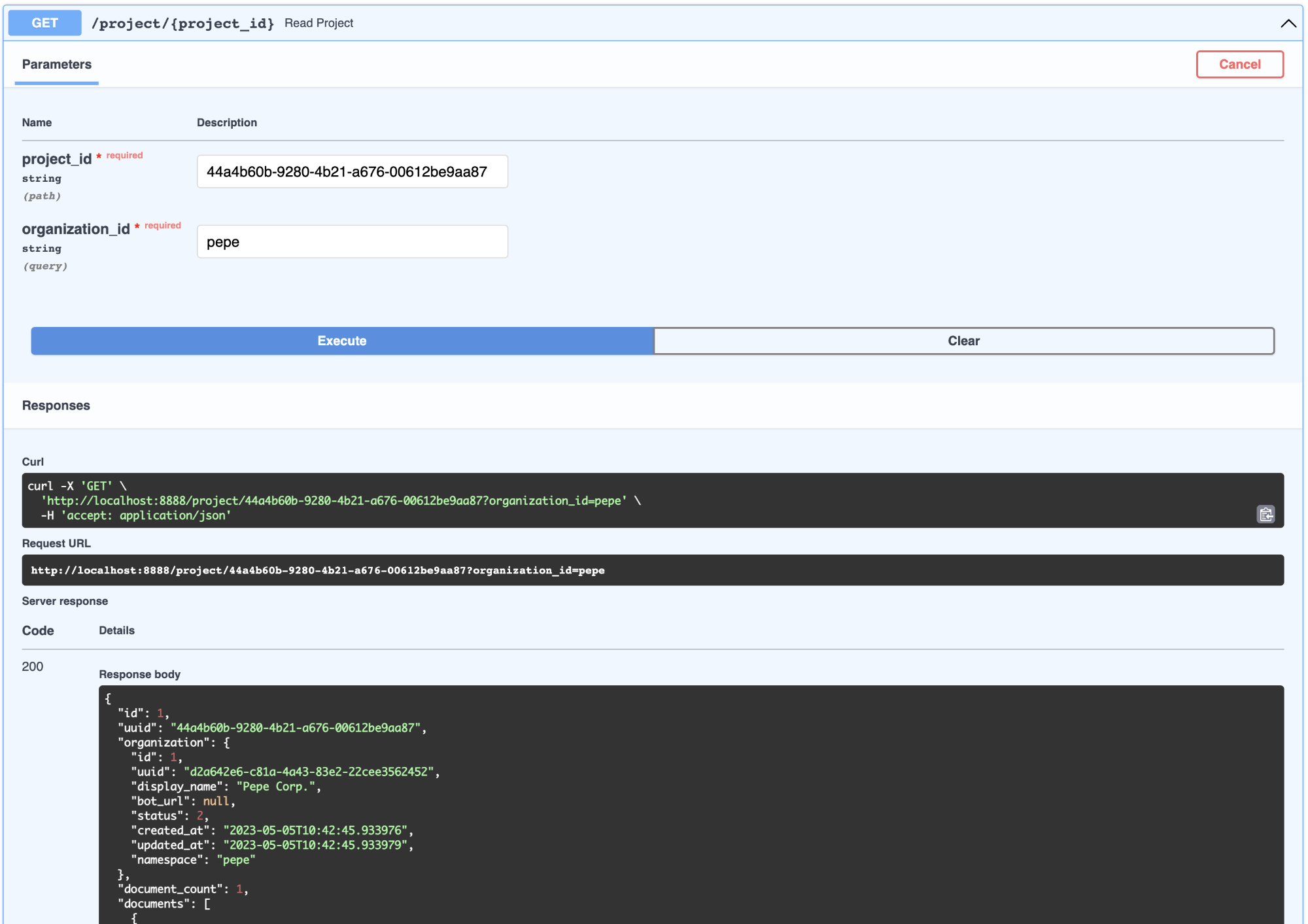
3.3.Document(文档)
这可以被视为与产品相关的工件,例如 FAQ 页面或财务报表收益 PDF。可以查看与组织项目相关的所有文档。如下所示:
{
"id": 1,
"uuid": "44a4b60b-9280-4b21-a676-00612be9aa87",
"organization": {
"id": 1,
"uuid": "d2a642e6-c81a-4a43-83e2-22cee3562452",
"display_name": "Pepe Corp.",
"bot_url": null,
"status": 2,
"created_at": "2023-05-05T10:42:45.933976",
"updated_at": "2023-05-05T10:42:45.933979",
"namespace": "pepe"
},
"document_count": 1,
"documents": [
{
"id": 1,
"uuid": "92604623-e37c-4935-bf08-0e9efa8b62f7",
"organization_id": 1,
"project_id": 1,
"display_name": "project-pepetamine.md",
"url": "",
"data": "# Pepetamine\n\nProduct Name: Pepetamine\n\nPurpose: Increases cognitive focus just like the Limitless movie\n\n**How to Use**\n\nPepetamine is available in the form of rare Pepe-coated tablets. The recommended dosage is one tablet per day, taken orally with a glass of water, preferably while browsing your favorite meme forum for maximum cognitive enhancement. For optimal results, take Pepetamine 30 minutes before engaging in mentally demanding tasks, such as decoding ancient Pepe hieroglyphics or creating your next viral meme masterpiece.\n\n**Side Effects**\n\nSome potential side effects of Pepetamine may include:\n\n1. Uncontrollable laughter and a sudden appreciation for dank memes\n2. An inexplicable desire to collect rare Pepes\n3. Enhanced meme creation skills, potentially leading to internet fame\n4. Temporary green skin pigmentation, resembling the legendary Pepe himself\n5. Spontaneously speaking in \"feels good man\" language\n\nWhile most side effects are generally harmless, consult your memologist if side effects persist or become bothersome.\n\n**Precautions**\n\nBefore taking Pepetamine, please consider the following precautions:\n\n1. Do not use Pepetamine if you have a known allergy to rare Pepes or dank memes.\n2. Pepetamine may not be suitable for individuals with a history of humor deficiency or meme intolerance.\n3. Exercise caution when driving or operating heavy machinery, as Pepetamine may cause sudden fits of laughter or intense meme ideation.\n\n**Interactions**\n\nPepetamine may interact with other substances, including:\n\n1. Normie supplements: Combining Pepetamine with normie supplements may result in meme conflicts and a decreased sense of humor.\n2. Caffeine: The combination of Pepetamine and caffeine may cause an overload of energy, resulting in hyperactive meme creation and potential internet overload.\n\nConsult your memologist if you are taking any other medications or substances to ensure compatibility with Pepetamine.\n\n**Overdose**\n\nIn case of an overdose, symptoms may include:\n\n1. Uncontrollable meme creation\n2. Delusions of grandeur as the ultimate meme lord\n3. Time warps into the world of Pepe\n\nIf you suspect an overdose, contact your local meme emergency service or visit the nearest meme treatment facility. Remember, the key to enjoying Pepetamine is to use it responsibly, and always keep in mind the wise words of our legendary Pepe: \"Feels good man.\"",
"hash": "fdee6da2b5441080dd78e7850d3d2e1403bae71b9e0526b9dcae4c0782d95a78",
"version": 1,
"status": 2,
"created_at": "2023-05-05T10:42:46.755428",
"updated_at": "2023-05-05T10:42:46.755431"
}
],
"display_name": "Pepetamine",
"created_at": "2023-05-05T10:42:46.060930",
"updated_at": "2023-05-05T10:42:46.060934"
}
3.4.Node(节点)
尽管在 API 中没有公开,但节点是为其生成 embedding 的文档块。节点用于检索搜索以及上下文注入。节点属于文档。
3.5.User(用户)
用户代表与机器人交谈的人。用户不一定属于组织或产品,但这种关系在下面的 ChatSession 中被捕获。
3.6.ChatSession(会话 Session)
不通过 API 公开,但这表示用户和机器人之间的问答。这些对象中的每一个都可以由自动生成的 session_id 灵活识别。Chat Session 包含丰富的 metadata,可用于训练和优化。通过 /chat 端点的 ChatSession 实际上与组织相关联(出于多租户安全目的)。
4.对话例子
这个机器人只是一个概念验证,并且尚未进行检索方面的优化。目前,它使用 1000 个字符长度的分块进行索引,使用基本的欧几里得距离进行检索,质量时好时坏。可以在 RESULTS.MD 文件中查看机器人的示例命中和未命中。总体而言,估计通过进行索引优化和 LLM 配置更改,输出质量可以提高超过 70%。单击查看演示数据的 Q&A 结果在 RESULTS.MD 文件中。
四.RasaGPT 工作原理
1.Rasa
Rasa 处理与通信 channel 的集成,在本例中为 Telegram。
它专门处理用户反馈应该通过的目标网络钩子(target webhook)的提交。在本例子中,它是 FastAPI 服务器,通过 /webhooks/{channel}/webhook
Rasa 有两个组件,核心Rasa app和单独运行的actions server。
Rasa 必须通过一些 yaml 文件进行配置(已经完成):
config.yml:包含 NLU 管道和策略配置。重要的是设置 FallbackClassifier阈值credentials.yml:包含 webhook 和 Telegram 凭据的路径。这将由辅助服务 rasa-credentials通过app/rasa-credentials/main.py进行更新domain.yml:这包含聊天入口点逻辑配置,如意图和针对意图采取的操作。在这里,添加 action_gpt_fallback操作,它将触发actions serverendpoints.yml:这是为 Rasa 设置自定义操作端点以触发 fallback 的地方 nlu.yml:这是设置意图 out_of_scope的地方rules.yml:为这个意图设置了一个规则,它应该触发动作 action_gpt_fallbackactions.py:这是通过 ActionGPTFallback定义和表达 action 的地方。方法名返回为上面意图定义的动作
Rasa 的 NLU 模型必须经过训练,这可以通过 CLI 命令
rasa train来完成。当运行make install时,这会自动完成。训练后必须通过
rasa run运行 Rasa Core。Rasa 的 action server 必须用
rasa run actions单独运行。
2.Telegram
Rasa 会自动使用 credentials.yml 中的回调 webhook 更新 Telegram Bot API。 默认情况下这是静态的。由于在本地运行,利用 Ngrok 生成一个公开访问的 URL,并反向隧道进入 Docker 容器。 rasa-credentials服务会处理这个过程。Ngrok 作为一个服务运行,一旦准备就绪,rasa-credentials 将调用本地的 Ngrok API 来检索隧道 URL,并更新 credentials.yml 文件,然后重新启动 Rasa。Telegram 将发送消息的 webhook 将是我们的 FastAPI 服务器。为什么不使用 Rasa?因为希望灵活地捕获 metadata,而 Rasa 使这变得复杂,集中到 API server 是理想的。 FastAPI 服务器将消息转发到 Rasa webhook。 Rasa 然后将根据用户意图确定要采取的操作。由于这个演示中的意图被弱化,它将进入到 actions.py中运行的 fallback action。自定义操作将捕获 metadata,并将来自 FastAPI 的响应转发给用户。
3.PGVector
PGVector 是 Postgres 的插件,可以自动安装,能够存储和计算向量数据类型。有自己的实现,因为 Langchain PGVector 类不灵活,无法适应模式,需要灵活性。
默认情况下,在 postgres 中,如果数据库尚未初始化,容器路径 /docker-entry-initdb.d中的任何文件都运行。在postgres Dockerfile中,复制 create_db.sh 创建数据库和用户。在Makefile中的 models 命令中,在 API 容器中运行 models.py,该容器从 models 中创建表。enable_vector 方法在数据库中启用 pgvector 扩展。
4.Langchain
训练数据被加载到数据库中 如果索引不存在,则对数据进行索引并存储在名为 index.json 的文件中 LlamaIndex 使用基本 GPTSimpleVectorIndex查找相关数据并将其注入 prompt。通过 prompt 的保护栏用于保持对话的集中。
5.Bot flow
用户将在 Telegram 中聊天,消息将被过滤为现有意图
如果它检测到没有意图匹配,而是匹配
out_of_scope,它将根据 rule.yml 触发action_gpt_fallback操作使用 LlamaIndex 的 API 会找到相关的索引内容,并将其注入到 prompt 中发送给 OpenAI 进行推理
prompt 包含对话护栏,包括:
请求数据 JSON 返回 根据用户的问题创建分类标签 如果对话应该升级到人工(如果没有上下文匹配),则返回布尔值
参考文献
[1] https://github.com/paulpierre/RasaGPT
[2] https://youtu.be/GAPnQ0qf1-E
[3] https://github.com/ai408/RasaGPT
NLP工程化
1.本公众号以对话系统为中心,专注于Python/C++/CUDA、ML/DL/RL和NLP/KG/DS/LLM领域的技术分享。
2.本公众号Roadmap可查看飞书文档:https://z0yrmerhgi8.feishu.cn/wiki/Zpewwe2T2iCQfwkSyMOcgwdInhf
NLP工程化

飞书文档

RasaGPT对话系统的工作原理的更多相关文章
- 菜鸟学Struts2——Struts工作原理
在完成Struts2的HelloWorld后,对Struts2的工作原理进行学习.Struts2框架可以按照模块来划分为Servlet Filters,Struts核心模块,拦截器和用户实现部分,其中 ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
RAC 工作原理和相关组件(三) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- ThreadLocal 工作原理、部分源码分析
1.大概去哪里看 ThreadLocal 其根本实现方法,是在Thread里面,有一个ThreadLocal.ThreadLocalMap属性 ThreadLocal.ThreadLocalMap t ...
- Servlet的生命周期及工作原理
Servlet生命周期分为三个阶段: 1,初始化阶段 调用init()方法 2,响应客户请求阶段 调用service()方法 3,终止阶段 调用destroy()方法 Servlet初始化阶段: 在 ...
- 代码管理工具 --- git的学习笔记二《git的工作原理》
通过几个问题来学习代码管理工具之git 一.git是什么?为什么要用它?使用它的好处?它与svn的区别,在Mac上,比较好用的git图形界面客户端有 git 是分布式的代码管理工具,使用它是因为,它便 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 浏览器内部工作原理--作者:Tali Garsiel
本篇内容为转载,主要用于个人学习使用,作者:Tali Garsiel 一.介绍 浏览器可以被认为是使用最广泛的软件,本文将介绍浏览器的工作原理,我们将看到,从你在地址栏输入google.com到你看到 ...
- Ajax工作原理
在写这篇文章之前,曾经写过一篇关于AJAX技术的随笔,不过涉及到的方面很窄,对AJAX技术的背景.原理.优缺点等各个方面都很少涉及null.这次写这篇文章的背景是因为公司需要对内部程序员做一个培训.项 ...
随机推荐
- Blackmail
Blackmail Arthur Hailey The chief house officer, Ogilvie, who had declared he would appear at the Cr ...
- DB22
IBM官方网站提供了DB2 Express-C版本的软件免费下载: 下载地址 : http://www.ibm.com/developerworks/cn/downloads/im/udbexp/
- kubernetes 概述
云原生的发展 云原生是一条最佳路径或者最佳实践.更详细的说,云原生为用户指定了一条低心智负担的.敏捷的.能够以可扩展.可复制的方式最大化地利用云的能力.发挥云的价值的最佳路径.因此,云原生其实是一套指 ...
- 如何在云服务上快速拥有洛甲WAF(Web防火墙)
如何在云服务上快速拥有洛甲WAF(Web防火墙) 洛甲WAF是基于openresty的web防火墙,通过配合后台保护您的数据安全,详情参考节点服务器 luojiawaf_lua(nginx+lua) ...
- 如何打开关闭Edge鼠标手势
概述 今天突然发现edge有了一个鼠标手势,用起来不是很适应,所以决定将其关掉. 操作步骤 点击edge右上角的三个点 在下拉菜单中选择设置 点开设置之后出现如图所示的界面,然后选择外观 往下面拉页面 ...
- 创建一个自己的 Linux系统
简单来说就是一个文件传递的机制,首先创建/安装一个硬盘,然后把前硬盘中的一部分文件先转移到Linux系统上,再通过Linux系统转移到创建的新硬盘,之后用虚拟机,把新硬盘装在其中,就可以在新硬盘上做到 ...
- helm仓库harbor搭建及上传helm
1.仓库搭建(harbor) 注意: 基础环境为docker 使用docker-compose安装 1.1.docker安装 # 安装需要的软件包 # yum-util 提供yum-config-ma ...
- C# 压缩PDF文件
PDF 文件可以包含文本.图片及各种媒体元素,但如果文件太大则会影响传输效果同时也会占用过多磁盘空间.通过压缩PDF文件,能够有效减小文件大小,从而提高传输效率并节省存储空间.想要通过C#代码快速有效 ...
- Codeforces Round #538 (Div. 2) F. Please, another Queries on Array?
原题链接 F. Please, another Queries on Array? 这道题让求\(\phi(\prod\limits_{i = l}^r a_i)\),然后我们化简一下. 设\(P\) ...
- 旋转矩阵(leetcode4.7每日打卡)
给你一幅由 N × N 矩阵表示的图像,其中每个像素的大小为 4 字节.请你设计一种算法,将图像旋转 90 度. 不占用额外内存空间能否做到? 示例 1: 给定 matrix = [ [1,2, ...