wxdown 公众号离线文章保存(GO语言开发)
简介
本来一开始用 nodejs 写的,考虑大小、易操作、高性能、跨平台以及环境等问题,我就想能不能搞个不需依赖开发语言环境就能运行的。所以我就选择 go并且它本身就具备以上优点。作者本身是java开发,第一次使用 go所以过程也是比较艰难,好在 GPT 在学习一门新的开发语言方面还是相当给力!
这是一个用于保存公众号文章到本地离线查看的软件,支持将 HTML 文章保存至本地,并提供 HTML 转 PDF 的功能。此外,软件还支持图片素材管理,可在 Windows、Mac 和 Linux 系统上运行,使用 Go 语言开发,具备轻量级、小体积、高性能和并发支持的特点。不支持批量直接获取文章列表
功能特点
- 保存公众号文章至本地
- 支持将 HTML 文章转换为 PDF 格式(需安装 wkhtmltopdf)
- 图片素材管理
- 保存原始地址
- 跨平台支持:Windows、Mac 和 Linux
- 使用 Go 语言开发,轻量级、高性能、高并发
- 提供简单易用的 Web 界面管理
下载
| 操作系统 | 版本/架构 | 大小 |
|---|---|---|
| Windows | wxdown-1.0.0-windows-amd64.exe | 9.23MB |
| ARM Linux | wxdown-1.0.0-linux-arm64 | 8.75MB |
| Linux | wxdown-1.0.0-linux-amd64 | 9.04MB |
| macOS | wxdown-1.0.0-darwin-amd64 | 9.09MB |
| macOS(Apple Silicon) | wxdown-1.0.0-darwin-arm64 | 8.75MB |
安装和运行
Windows
包含了 wkhtmltopdf
- 解压缩包
- 打开目录
- 双击
wxdown-1.0.0-windows-amd64.exe启动 - 浏览器访问 http://127.0.0.1:81
如下所示启动成功:
cwd: E:\code\go\go-wx-download
----------------------------------------
欢迎使用 wxdown 工具!
----------------------------------------
运行模式 : binary
软件版本 : 1.0.0
操作系统 : windows
系统架构 : amd64
启动时间 : 2024-05-19 00:00:00
----------------------------------------
服务信息
----------------------------------------
服务地址:
http://192.168.31.209:81 (浏览器访问)
http://192.168.202.1:81 (浏览器访问)
http://192.168.11.1:81 (浏览器访问)
http://172.26.192.1:81 (浏览器访问)
http://127.0.0.1:81 (浏览器访问)
采集接口:
http://192.168.31.209:81/gather/ (GET|POST|HEAD)
http://192.168.202.1:81/gather/ (GET|POST|HEAD)
http://192.168.11.1:81/gather/ (GET|POST|HEAD)
http://172.26.192.1:81/gather/ (GET|POST|HEAD)
http://127.0.0.1:81/gather/ (GET|POST|HEAD)
----------------------------------------
配置信息
----------------------------------------
运行路径 : E:\code\go\go-wx-download
资源路径 : E:\code\go\go-wx-download\data
Linux
添加权限
chmod +x wxdown-1.0.0-linux-amd64
启动程序
root@mac-max:/home/wx# ./wxdown-1.0.0-linux-amd64
cwd: /home/wx
----------------------------------------
欢迎使用 wxdown 工具!
----------------------------------------
运行模式 : binary
软件版本 : 1.0.0
操作系统 : linux
系统架构 : amd64
启动时间 : 2024-05-19 00:00:00
----------------------------------------
服务信息
----------------------------------------
服务地址:
http://192.168.31.156:81 (浏览器访问)
http://172.17.0.1:81 (浏览器访问)
http://172.18.0.1:81 (浏览器访问)
http://127.0.0.1:81 (浏览器访问)
采集接口:
http://192.168.31.156:81/gather/ (GET|POST|HEAD)
http://172.17.0.1:81/gather/ (GET|POST|HEAD)
http://172.18.0.1:81/gather/ (GET|POST|HEAD)
http://127.0.0.1:81/gather/ (GET|POST|HEAD)
----------------------------------------
配置信息
----------------------------------------
运行路径 : /home/wx
资源路径 : /home/wx/data
Mac
出现 permission denied 表示没有权限
(base) mac@macdeMacBook-Pro-3 ~ % /Users/mac/Desktop/wxdown-1.0.0-darwin-amd64/wxdown-1.0.0-darwin-amd64
zsh: permission denied: /Users/mac/Desktop/wxdown-1.0.0-darwin-amd64/wxdown-1.0.0-darwin-amd64
添加权限
(base) mac@macdeMacBook-Pro-3 ~ % chmod +x /Users/mac/Desktop/wxdown-1.0.0-darwin-amd64/wxdown-1.0.0-darwin-amd64
双击 wxdown-1.0.0-darwin-amd64 启动或命令启动
(base) mac@macdeMacBook-Pro-3 ~ % /Users/mac/Desktop/wxdown-1.0.0-darwin-amd64/wxdown-1.0.0-darwin-amd64
执行结果同上
简单使用会下载和安装就可以了,后面都基本没啥用了,不用再看了
目录结构
web:HTML 页面,很简单也可以自己修改index.html主页面images.html图片预览页面
config.yaml:系统全局配置文件wxdown-1.0.0可执行文件,程序入口
config.yaml
# 服务端口
port: 81
# 本地数据文件存储路径
path: ./data
# HTML 转 PDF 配置
# 下载 wkhtmltopdf 路径 https://wkhtmltopdf.org/downloads.html
# window 建议下载后将 wkhtmltopdf目录下载所有内容拷贝到项目根目录下
wkhtmltopdf:
# true 开启 false 关闭 默认关闭
enable: false
# linux 例如:/usr/local/wkhtmltopdf/bin/
# window 例如:E:\Program Files\wkhtmltopdf\bin
path:
# 采集线程配置
thread:
# 同时下载 HTML 线程数量
html: 5
# 同时下载图片线程数量
image: 10
接口
采集接口
GET仅支持单次下载,POST支持批量提交,请求头类型JSON格式- http://127.0.0.1:81/gather/+需采集地址。就可以直接把地址发给采集软件
| 地址 | 请求方式 | 请求参数 | 请求体 |
|---|---|---|---|
| http://127.0.0.1:81/gather/ | GET | /gather/https://mp.weixin.qq.com/1 | 无 |
| HEAD | /gather/https://mp.weixin.qq.com/1 | 无 | |
| POST | /gather/ | ["https://mp.weixin.qq.com/1","https://mp.weixin.qq.com/2",...] |
书签脚本
注意️:如果启动软件的机器和浏览文章的机器不是一台机器,使用局域网 IP(192.168.0.xxx)替换 127.0.0.1
javascript:fetch("http://127.0.0.1:81/gather/" + window.location.href,{mode:"no-cors"});
使用方法:
- 浏览器书签栏️右键️添加网页...️名称:随便你能记住就行️网址:输入下面
js脚本 - 打开浏览器公众号文章
- 点击上面添加的书签脚本软件会自动采集
资源接口
| 地址 | 请求方式 | 请求参数 | 请求体 |
|---|---|---|---|
| http://127.0.0.1:81/articles | GET | 无 | 无 |
打开文件夹接口
| 地址 | 请求方式 | 请求参数 | 请求体 |
|---|---|---|---|
| http://127.0.0.1:81/open/ | GET | /open/公众号名称 | 无 |
使用示例
主页面
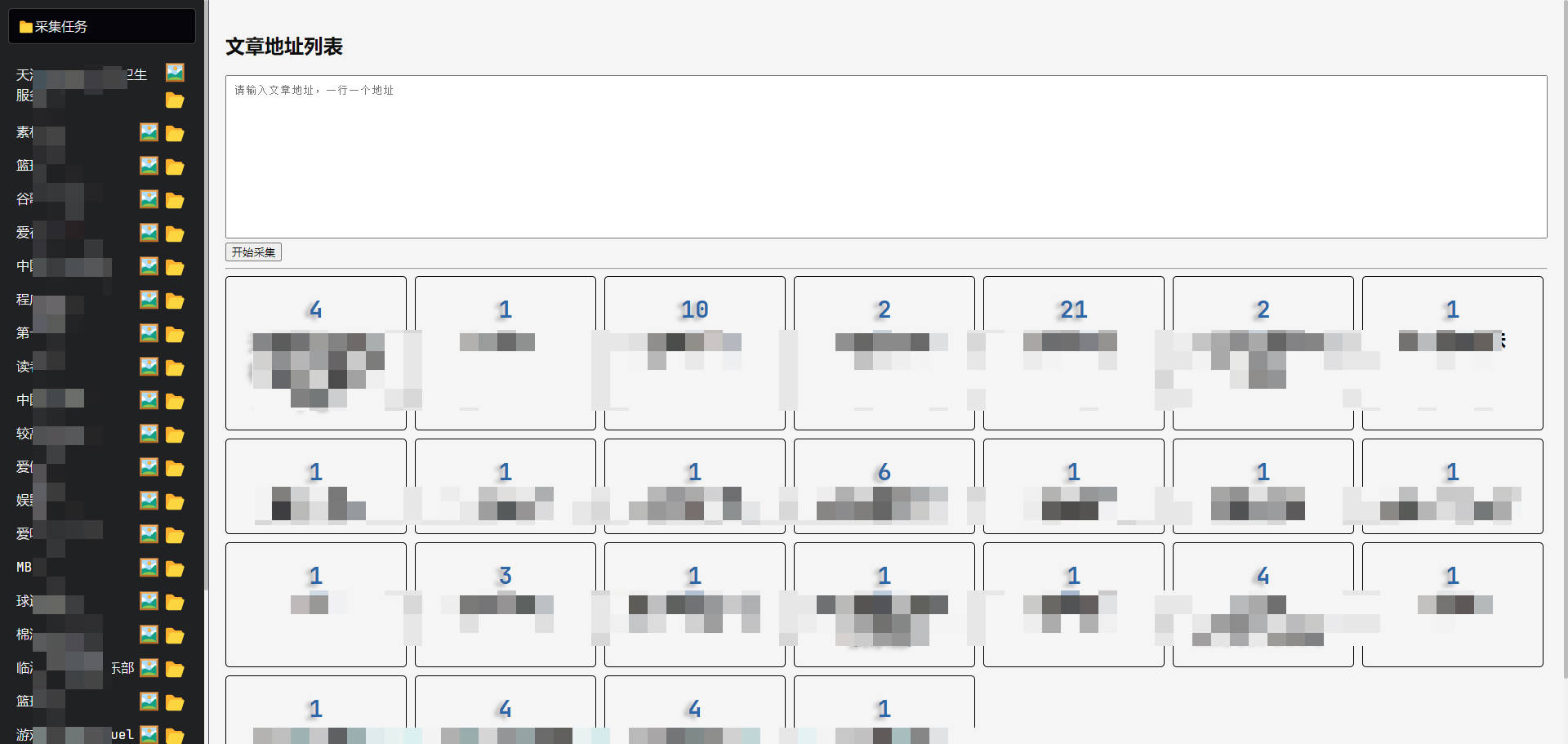
文章列表

图片库

开发和贡献
本软件使用 Go 语言开发,欢迎开发者贡献代码或提出改进建议。请在 GitHub 上提交 issue 或 pull request。
注意事项
- 请勿传播未经授权的文章或图片。
- 在保存、转换文章或管理图片时,请注意版权和法律规定。
wxdown 公众号离线文章保存(GO语言开发)的更多相关文章
- 50行Python代码,教你获取公众号全部文章
> 本文首发自公众号:python3xxx 爬取公众号的方式常见的有两种 - 通过搜狗搜索去获取,缺点是只能获取最新的十条推送文章 - 通过微信公众号的素材管理,获取公众号文章.缺点是需要申请自 ...
- python爬搜狗微信获取指定微信公众号的文章
前言: 之前收藏了一个叫微信公众号的文章爬取,里面用到的模块不错.然而 偏偏报错= =.果断自己写了一个 正文: 第一步爬取搜狗微信搜到的公众号: http://weixin.sogou.com/we ...
- 用iframe嵌入了一个微信公众号平台文章的URL
JS: $.ajaxPrefilter( function (options) { if (options.crossDomain && jQuery.support.cors) { ...
- 我创建了一个网站,专门分享公众号的文章 https://asyons.com
网址:https://asyons.com/,为做个网站,自娱自乐的自明星,但投资也挺大的了,注册了一家公司,公财私章,做账报税,阿里云服务器,全职开发.算上时间价值,按小时,投资过5万了.
- 巧-微信公众号-操作返回键问题-angularjs开发 SPA
在解决这个问题之前,一直处在很苦逼的状态,因为 现在绝大多数 前端模块都是 SPA 模式:所以由此而来出了许多的问题,当然我现在提的这个只是其中一个: 说一下解决方案: 1.技术栈 angularjs ...
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- Md2All:好用的markdown文件转换工具,文章迁移微信公众号的利器
目录 简介 使用体验 极速上手 更多功能 总结 简介 markdown以简单的语法和强大的功能,征服了无数技术创作者,几乎主流的技术博客网站都开始支持markdown语言撰写博客.但是微信公众号的文章 ...
- 【技巧】如何使用客户端发布BLOG+如何快速发布微信公众号文章
[技巧]如何使用客户端发布BLOG+如何快速发布微信公众号文章 1 BLOG文档结构图 2 前言部分 2.1 导读和注意事项 各位技术爱好者,看完本文后,你可以掌握如下的技能,也 ...
- 拒绝低效!Python教你爬虫公众号文章和链接
本文首发于公众号「Python知识圈」,如需转载,请在公众号联系作者授权. 前言 上一篇文章整理了的公众号所有文章的导航链接,其实如果手动整理起来的话,是一件很费力的事情,因为公众号里添加文章的时候只 ...
- 发现了合自己胃口的公众号,但文章太多翻来翻去真麻烦,还好我学了 Python
现在我们大多数人都会或多或少的关注几个公众号,如果发现一个比较合自己胃口的号 对公众号中的文章一定是每篇必读的. 有时候我们关注到宝藏型公众号时发现其历史文章已经好几百甚至上千篇了,而作者又只对其中自 ...
随机推荐
- RabbitMQ 10 头部模式
头部模式是根据头部信息来决定的,在发送的消息中是可以携带一些头部信息的(类似于HTTP),可以根据这些头部信息来决定路由到哪一个消息队列中. 定义配置类. import org.springframe ...
- Ubuntu部署Django一:环境搭建
前言: Ubuntu系统上部署django,使用的部署方案是 Ubuntu + django + uwsgi + nginx Ubuntu系统版本用的是 ubuntu-20.04.2.0-desk ...
- MogDB/openGauss存储过程的修改
MogDB/openGauss 存储过程的修改 SQL 中没有提供显式的存储过程修改命令,通常需要通过 REPLACE 关键字来指定使用当前的存储过程替代之前的同名存储过程. 将前文定义的存储过程替换 ...
- pc=mobile+pad自适应布局:页面结构与打开方式
pc=mobile+pad自适应布局 在这篇文章,咱们重点聊聊自适应布局的页面结构,以及打开页面的几种方式.关于pc=mobile+pad自适应布局的起源.概念.效果,参见文章:自适应布局:pc = ...
- 掌握 xUnit 单元测试中的 Mock 与 Stub 实战
引言 上一章节介绍了 TDD 的三大法则,今天我们讲一下在单元测试中模拟对象的使用. Fake Fake - Fake 是一个通用术语,可用于描述 stub或 mock 对象. 它是 stub 还是 ...
- spark 异常值过滤 IQR
def getIQR(df:DataFrame,colName:String):Array[Double]={ val tmpDf = df.withColumn(colName, col(colNa ...
- FPGA芯片结构介绍及工作原理解析
FPGA工作原理与简介 如前所述,FPGA是在PAL.GAL.EPLD.CPLD等可编程器件的基础上进一步发展的产物.它是作为ASIC领域中的一种半定制电路而出现的,即解决了定制电路的不足,又克 ...
- List拖拽功能的实现
概述 如何在HarmonyOS应用中实现一个可拖拽的列表组件,通过这个组件,用户可以拖动列表中的项并将其放置在新的位置,实现列表的动态排序. 核心功能 列表初始化:创建并填充列表数据. 拖 ...
- 如何用一行 CSS 实现 10 种现代布局
现代 CSS 布局使开发人员只需按几下键就可以编写十分有意义且强大的样式规则.上面的讨论和接下来的帖文研究了 10 种强大的 CSS 布局,它们实现了一些非凡的工作. 01. 超级居中:place-i ...
- 力扣550(MySQL)-游戏玩法分析Ⅳ(中等)
题目: 需求:编写一个 SQL 查询,报告在首次登录的第二天再次登录的玩家的分数,四舍五入到小数点后两位.换句话说,您需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数. 查询结 ...