拒绝低效!Python教你爬虫公众号文章和链接
本文首发于公众号「Python知识圈」,如需转载,请在公众号联系作者授权。
前言
上一篇文章整理了的公众号所有文章的导航链接,其实如果手动整理起来的话,是一件很费力的事情,因为公众号里添加文章的时候只能一篇篇的选择,是个单选框。
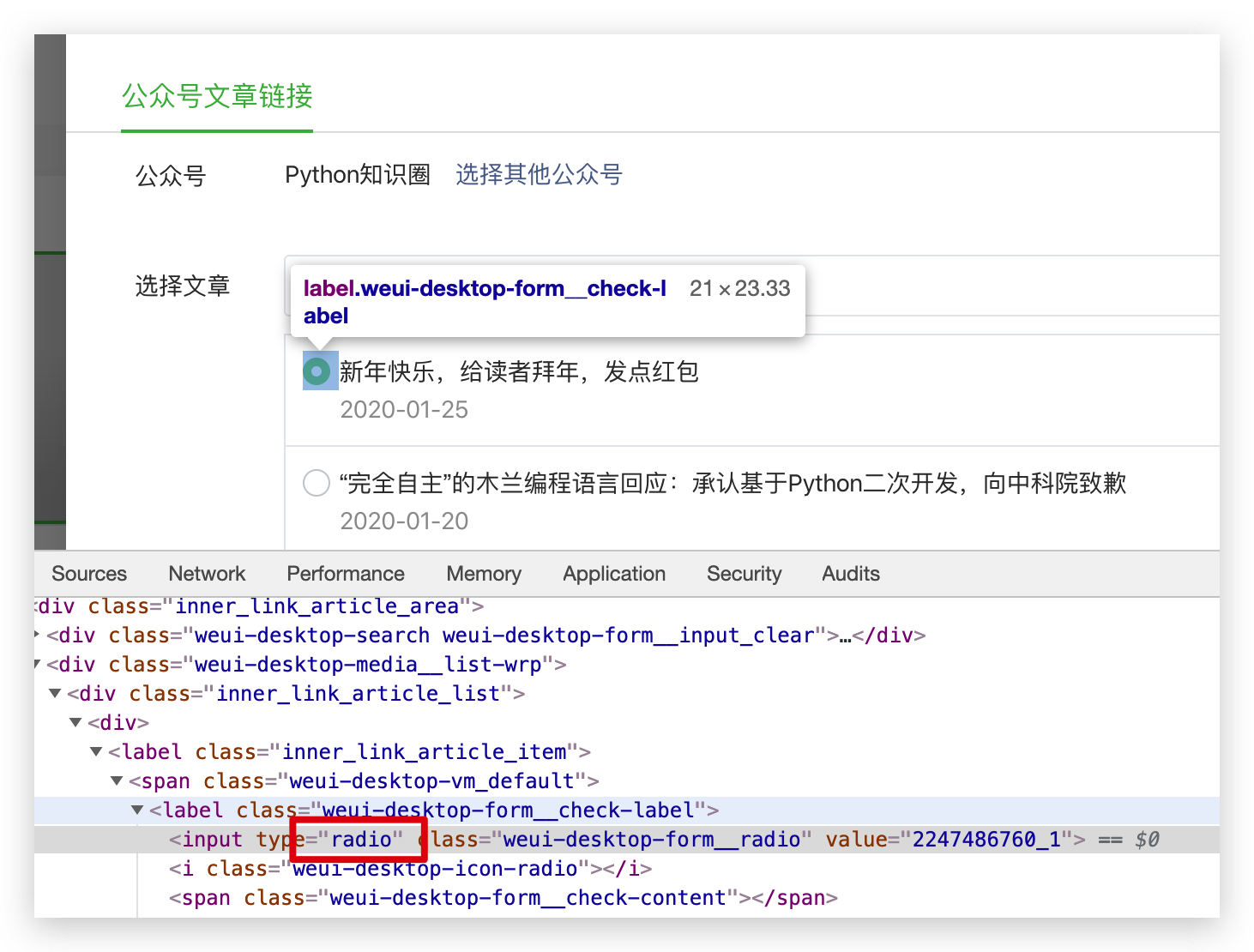
面对几百篇的文章,这样一个个选择的话,是一件苦差事。
pk哥作为一个 Pythoner,当然不能这么低效,我们用爬虫把文章的标题和链接等信息提取出来。
抓包
我们需要通过抓包提取公众号文章的请求的 URL,参考之前写过的一篇抓包的文章 Python爬虫APP前的准备,pk哥这次直接抓取 PC 端微信的公众号文章列表信息,更简单。
我以抓包工具 Charles 为例,勾选容许抓取电脑的请求,一般是默认就勾选的。
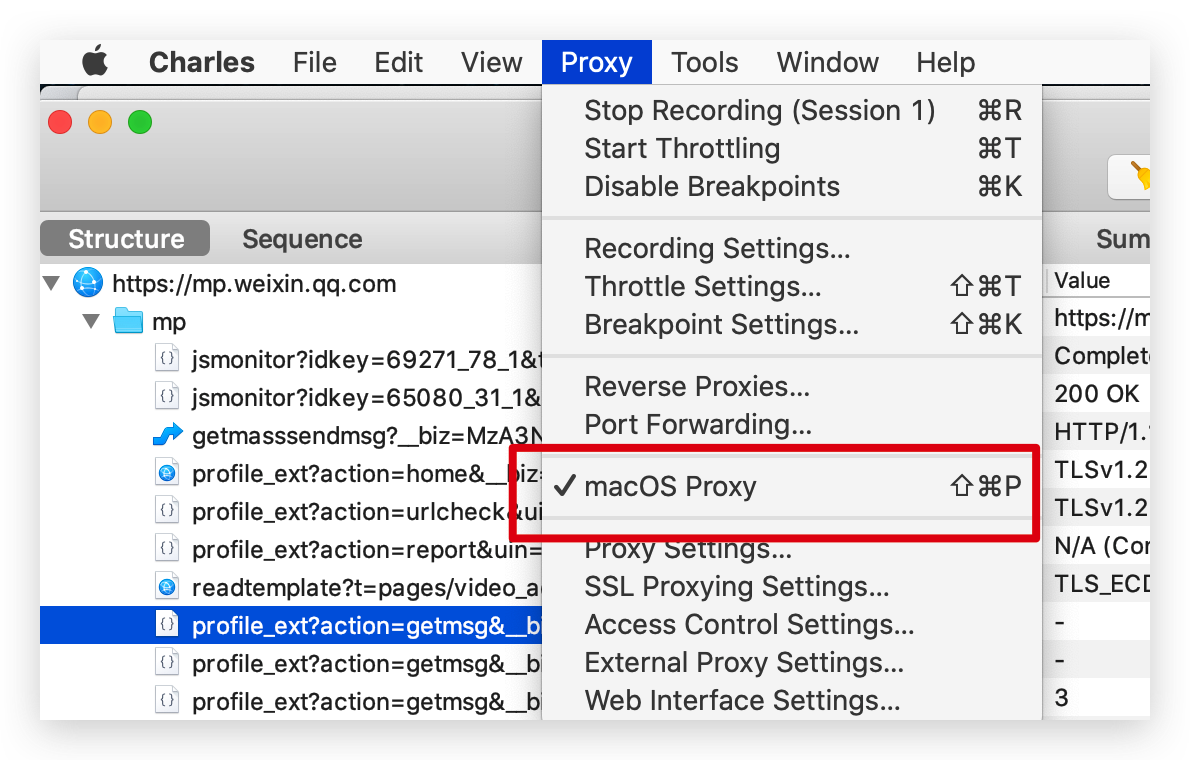
为了过滤掉其他无关请求,我们在左下方设置下我们要抓取的域名。
打开 PC 端微信,打开 「Python知识圈」公众号文章列表后,Charles 就会抓取到大量的请求,找到我们需要的请求,返回的 JSON 信息里包含了文章的标题、摘要、链接等信息,都在 comm_msg_info 下面。
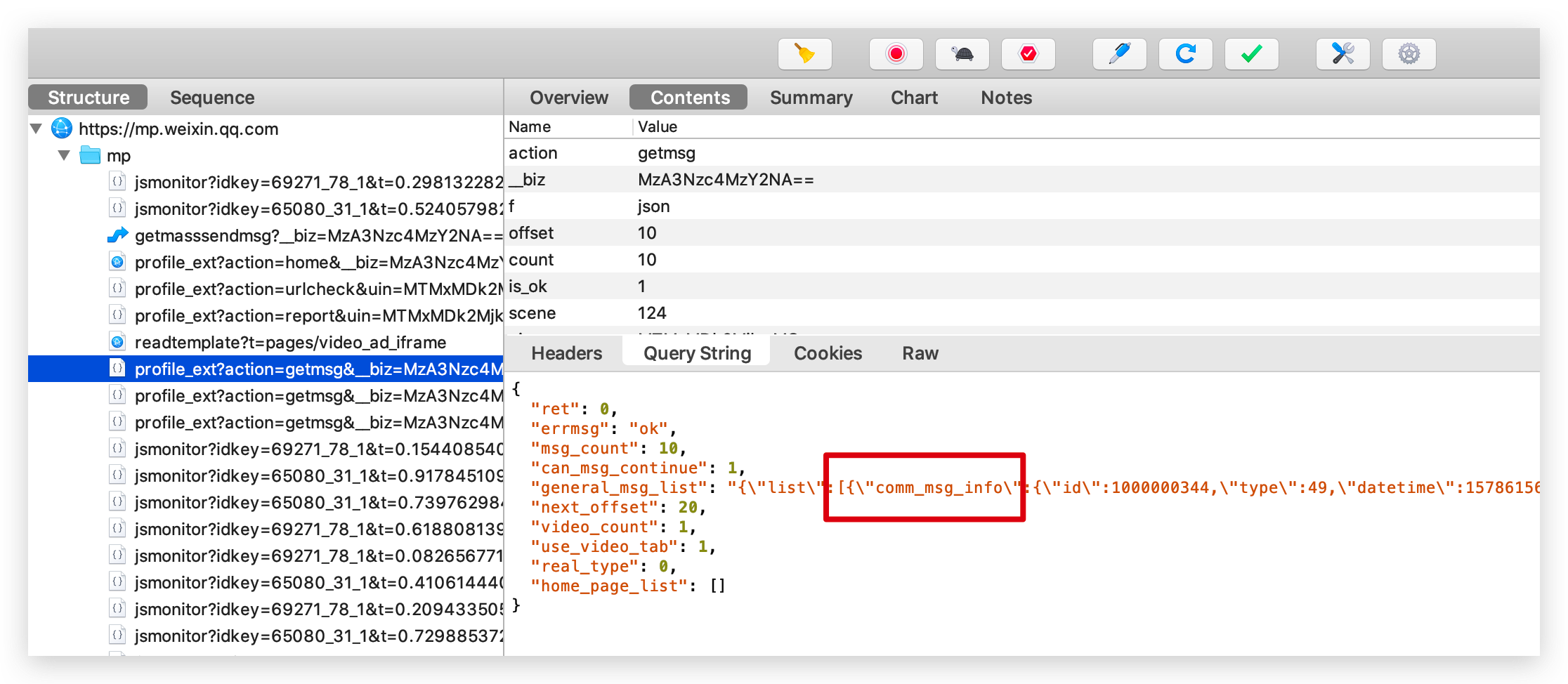

这些都是请求链接后的返回,请求链接 url 我们可以在 Overview 中查看。
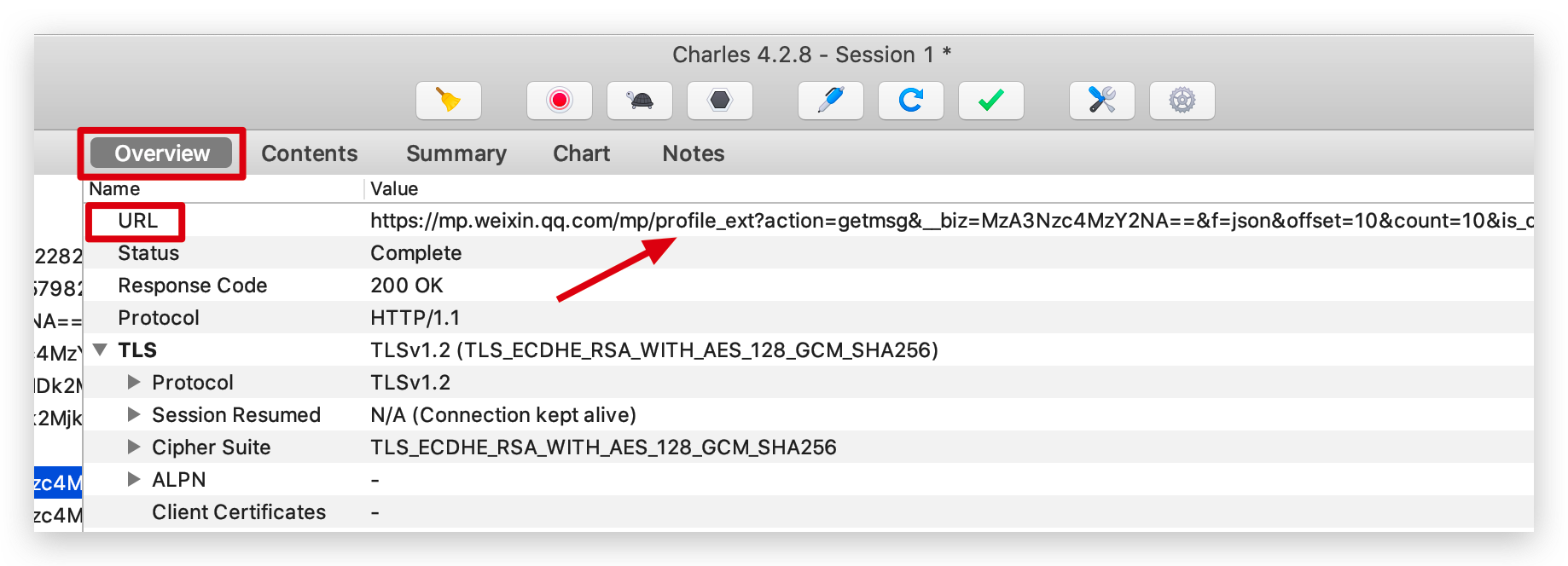
通过抓包获取了这么多信息后,我们可以写爬虫爬取所有文章的信息并保存了。
初始化函数
公众号历史文章列表向上滑动,加载更多文章后发现链接中变化的只有 offset 这个参数,我们创建一个初始化函数,加入代理 IP,请求头和信息,请求头包含了 User-Agent、Cookie、Referer。
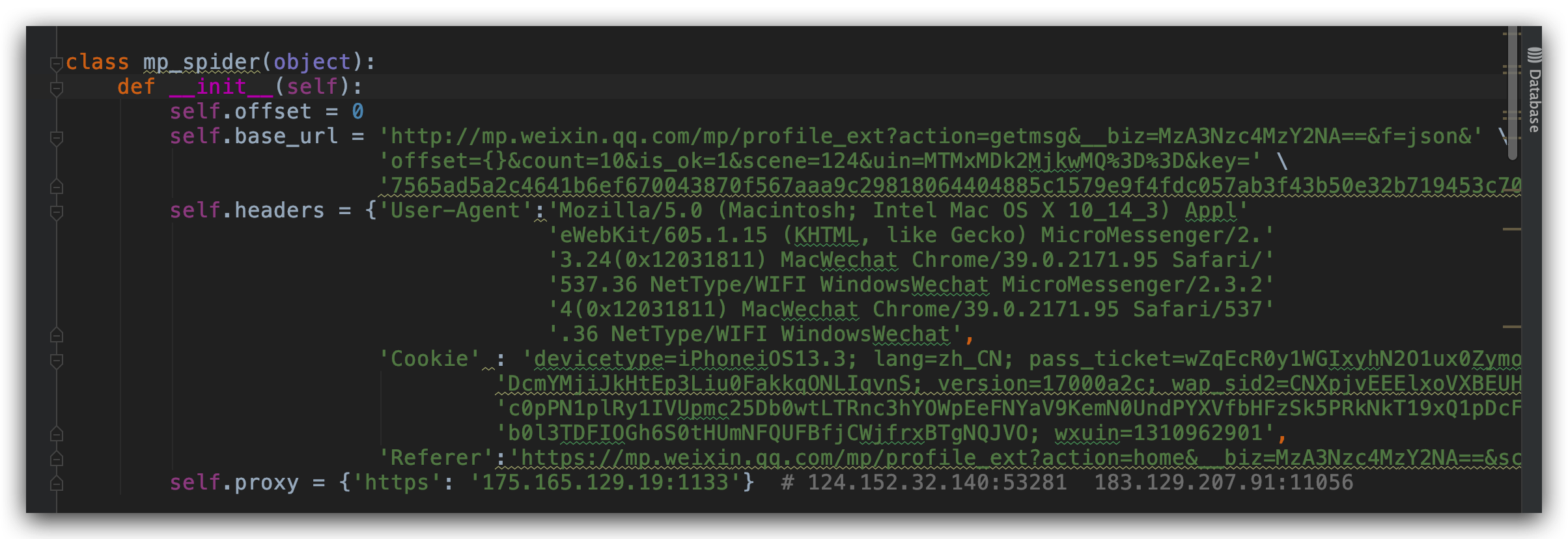
这些信息都在抓包工具可以看到。
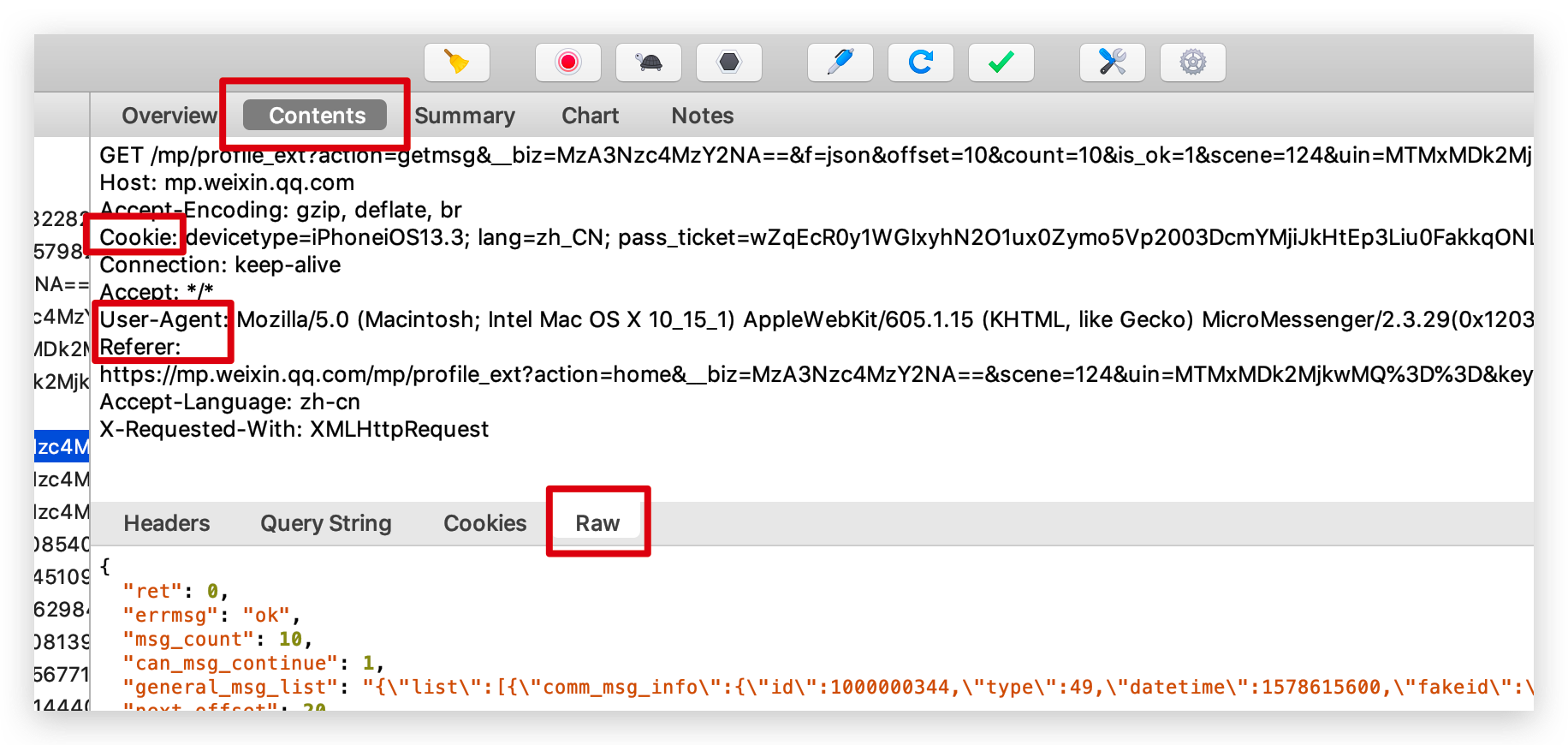
请求数据
通过抓包分析出来了请求链接,我们就可以用 requests 库来请求了,用返回码是否为 200 做一个判断,200 的话说明返回信息正常,我们再构建一个函数 parse_data() 来解析提取我们需要的返回信息。
def request_data(self):
try:
response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy)
print(self.base_url.format(self.offset))
if 200 == response.status_code:
self.parse_data(response.text)
except Exception as e:
print(e)
time.sleep(2)
pass
提取数据
通过分析返回的 Json 数据,我们可以看到,我们需要的数据都在 app_msg_ext_info 下面。
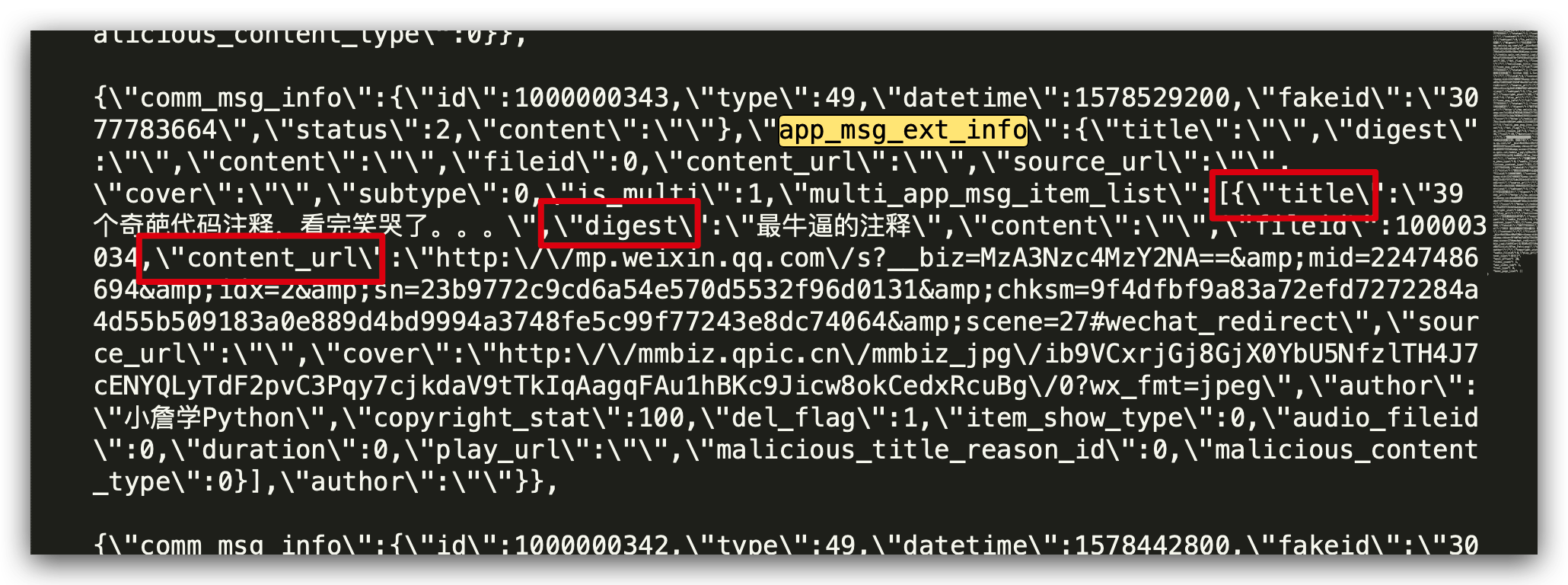
我们用 json.loads 解析返回的 Json 信息,把我们需要的列保存在 csv 文件中,有标题、摘要、文章链接三列信息,其他信息也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas['ret'] and all_datas['msg_count']>0:
summy_datas = all_datas['general_msg_list']
datas = json.loads(summy_datas)['list']
a = []
for data in datas:
try:
title = data['app_msg_ext_info']['title']
title_child = data['app_msg_ext_info']['digest']
article_url = data['app_msg_ext_info']['content_url']
info = {}
info['标题'] = title
info['小标题'] = title_child
info['文章链接'] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print('正在写入文件')
with open('Python公众号文章合集1.csv', 'a', newline='', encoding='utf-8') as f:
fieldnames = ['标题', '小标题', '文章链接'] # 控制列的顺序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print("写入成功")
print('----------------------------------------')
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print('抓取数据完毕!')
这样,爬取的结果就会以 csv 格式保存起来。
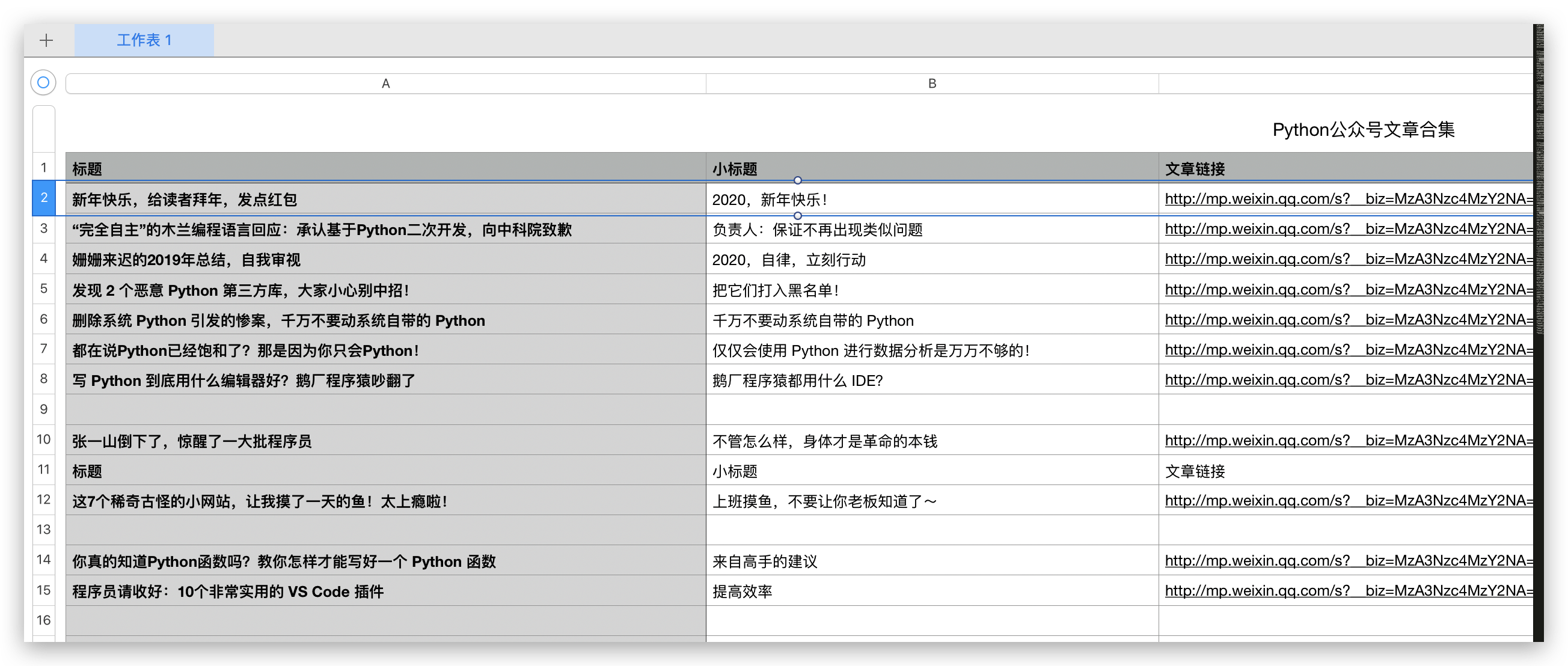
运行代码时,可能会遇到 SSLError 的报错,最快的解决办法就是 base_url 前面的 https 去掉 s 再运行。
保存markdown格式的链接
经常写文章的人应该都知道,一般写文字都会用 Markdown 的格式来写文章,这样的话,不管放在哪个平台,文章的格式都不会变化。
在 Markdown 格式里,用 [文章标题](文章url链接) 表示,所以我们保存信息时再加一列信息就行,标题和文章链接都获取了,Markdown 格式的 url 也就简单了。
md_url = '[{}]'.format(title) + '({})'.format(article_url)
爬取完成后,效果如下。
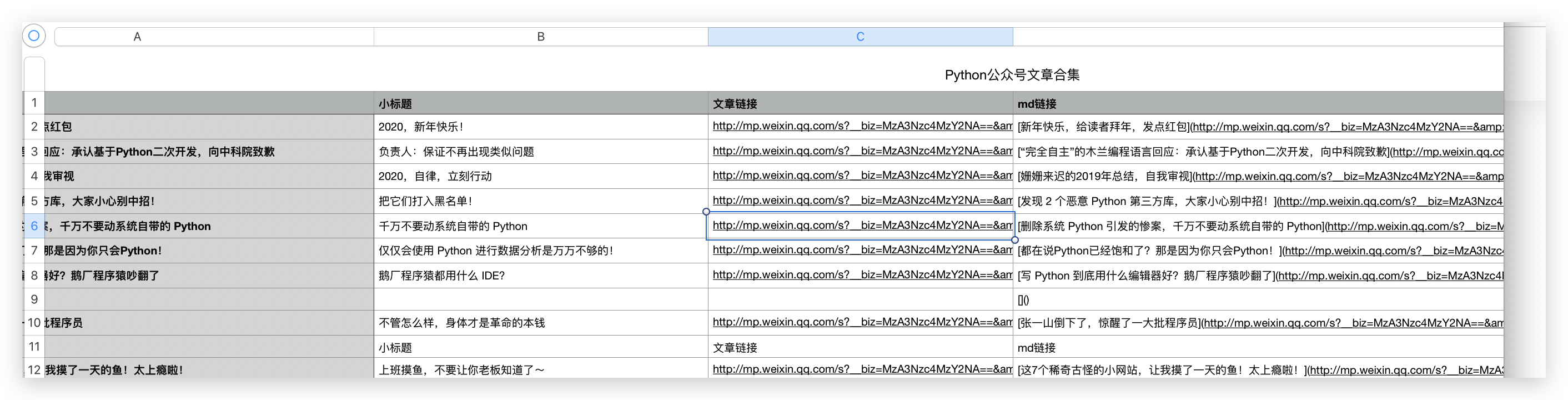
我们把 md链接这一列全部粘贴到 Markdown 格式的笔记里就行了,大部分的笔记软件都知道新建 Markdown 格式的文件的。
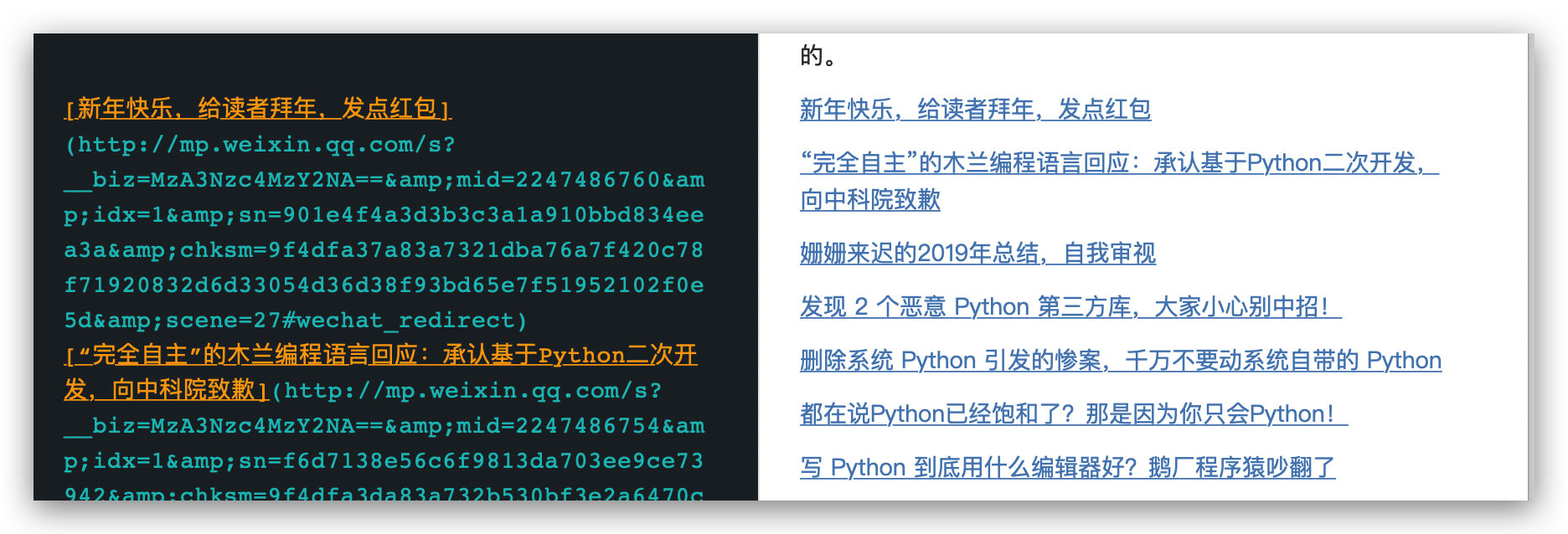
这样,这些导航文章链接整理起来就是分类的事情了。
你用 Python 解决过生活中的小问题吗?欢迎留言讨论。
拒绝低效!Python教你爬虫公众号文章和链接的更多相关文章
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- 50行Python代码,教你获取公众号全部文章
> 本文首发自公众号:python3xxx 爬取公众号的方式常见的有两种 - 通过搜狗搜索去获取,缺点是只能获取最新的十条推送文章 - 通过微信公众号的素材管理,获取公众号文章.缺点是需要申请自 ...
- python爬取微信公众号
爬取策略 1.需要安装python selenium模块包,通过selenium中的webdriver驱动浏览器获取Cookie的方法.来达到登录的效果 pip3 install selenium c ...
- Python 微信公众号文章爬取
一.思路 我们通过网页版的微信公众平台的图文消息中的超链接获取到我们需要的接口 从接口中我们可以得到对应的微信公众号和对应的所有微信公众号文章. 二.接口分析 获取微信公众号的接口: https:// ...
- Markdown 直接转换公众号文章,不再为排版花时间
上一篇「又一家数据公司被查,爬虫到底做错了什么?」反响强烈,虽然我这是新号,但还是获得了不少公众号的转发,借机也结识了很多业内大佬,在此感谢大家的抬爱! 同时也有不少号主问我的文章排版是用的哪个网站, ...
- 破解微信防盗链&微信公众号文章爬取方案
破解微信图文防盗链:https://www.cnblogs.com/xsxshmily/p/8000043.html 图片解除防盗链:https://blog.csdn.net/show_ljw/ar ...
- Chrome浏览器保存微信公众号文章中的图片
用chrome浏览器打开微信公众号文章中时,另存为图片时保存的是640.webp,不是图片本身,用IE则没有此问题.大部分chrome插件也无法保存图片. 经过多番尝试,找到一款插件可以批量保存微信公 ...
- pc端引入微信公众号文章
最近做了一个小需求,结果坑特别多..... 需求是这样的,要给公司内部做一个微信公众号广告投票系统,整个项目就不多赘述了,有个小功能,要求是这样的: 点击某条记录后的“投票”按钮,在当前页面弹出弹窗显 ...
- 你所不知道的 Kindle - 阅读微信公众号文章
Kindle 是一款非常优秀的阅读设备,它为我们提供了非常舒服的阅读体验,并且配合强大的亚马逊图书资源,应该是目前最好的阅读设备之一.Kindle 在已有的成就下还一直在努力提升用户体验.为中国用户开 ...
随机推荐
- mysql 执行计划查看
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈.explain执行计划包含的信息 其中最重要的字段为:id ...
- iOS - 创建可以在 InterfaceBuilder 中实时预览的自定义控件
一.需求实现一个前后带图标的输入框 这是一个简单的自定义控件,很容易想到自定义一个视图(UIView),然后前后的图标使用 UIImageView 或者 UIButton 显示,中间放一个 UITex ...
- 使用SqlDependency实时监听SQL server数据库变化并执行事件
sql server设置:ALTER DATABASE <DatabaseName> SET ENABLE_BROKER;语句让相应的数据库启用监听服务,以便支持SqlDependency ...
- asp.net core 3.x 通用主机是如何承载asp.net core的-上
一.前言 上一篇<asp.net core 3.x 通用主机原理及使用>扯了下3.x中的通用主机,刚好有哥们写了篇<.NET Core 3.1和WorkerServices构建Win ...
- C#反射与特性(八):反射操作的示例大全
目录 1,InvokeMember 1.1 InvokeMember 参数 1.2 实践使用 InvokeMember 和成员的重载方法 微信平台,此文仅授权<NCC 开源社区>订阅号发布 ...
- 《C# 爬虫 破境之道》:概述
第一节:写作本书的目的 关于笔者 张晓亭(Mike Cheers),1982年出生,内蒙古辽阔的大草原是我的故乡. 没有高学历,没有侃侃而谈的高谈阔论,拥有的就是那一份对技术的执著,对自我价值的追求. ...
- spark storm 反压
因特殊业务场景,如大促.秒杀活动与突发热点事情等业务流量在短时间内剧增,形成巨大的流量毛刺,数据流入的速度远高于数据处理的速度,对流处理系统构成巨大的负载压力,如果不能正确处理,可能导致集群资源耗尽最 ...
- Nginx配置不同端口号映射二级域名
upstream xx{ #ip_hash; server 127.0.0.1:1008; } server { listen 80; server_name xx.xxx.com; location ...
- PythonI/O进阶学习笔记_11.python的多进程
content: 1. 为什么要多进程编程?和多线程有什么区别? 2. python 多进程编程 3. 进程间通信 ======================================= ...
- HGE引擎改进——2014/1/27
2014/1/27 更新 hge库: 1.增加回调函数procResizeFunc(),这个函数会在窗口大小改变时调用,不是必要函数 2.修复LOG信息显示为乱码的错误 项目主页:https://co ...