文心一言 VS 讯飞星火 VS chatgpt (73)-- 算法导论7.1 4题
四、如何修改 QUICKSORT,使得它能够以非递增序进行排序?
文心一言:
快速排序(Quicksort)是一种常用的排序算法,基于分治策略进行设计。默认情况下,快速排序会以递增序进行排序。若想修改快速排序以实现非递增排序,我们需要调整比较和交换的逻辑。
以下是修改后的非递增快速排序的 Python 代码:
def quicksort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[len(arr)//2]
left = [x for x in arr if x > pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x < pivot]
return quicksort(left) + middle + quicksort(right)
print(quicksort([3,6,8,10,1,2,1]))
在上述代码中,我们首先选取一个中间值(pivot),将数组划分为三个部分:大于 pivot、等于 pivot 和小于 pivot。然后,我们递归地对小于和大于 pivot 的部分进行快速排序。最后,我们将这三个部分合并并返回。这样,我们就可以得到一个非递增排序的数组。
需要注意的是,上述代码可能会导致性能问题,因为它涉及了大量不必要的列表创建和合并操作。在生产环境中,建议使用原地版本的快速排序来避免这个问题。但是,为了清晰起见,我在这里使用了这种方式。
讯飞星火:
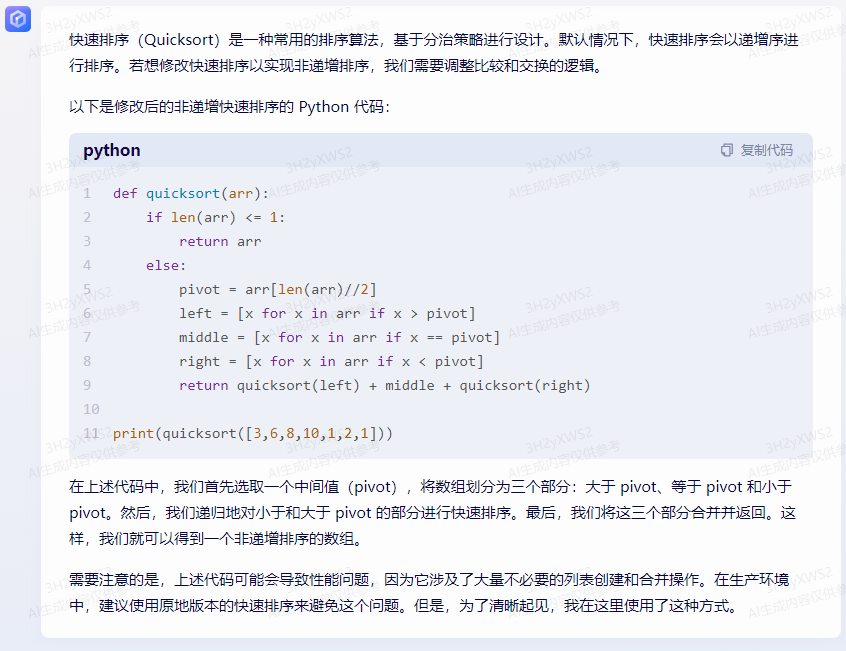
您可以通过修改PARTITION函数来实现快速排序的非递增排序。在PARTITION函数中,您可以将x设置为A[r],然后使用以下代码将数组按非递增顺序排序:
for j in range(p, r):
if A[j] <= x:
i = i + 1
A[i], A[j] = A[j], A[i]
A[i + 1], A[r] = A[r], A[i + 1]
return i + 1
这将使快速排序按照非递增顺序对数组进行排序。
360智脑:
QUICKSORT是一种基于比较的排序算法,它通过分治的思想将待排序的数组分成若干个子序列,然后对每个子序列进行递归排序,最终将它们合并起来得到有序的数组。
如果要修改QUICKSORT使其以非递增序进行排序,可以考虑以下几种方法:
1.自定义比较函数
QUICKSORT使用的比较函数是比较数组中两个元素的值,然后根据它们的值来决定它们应该排在哪一组子序列里面。如果我们想要以非递增序进行排序,可以自定义比较函数,使得较小的元素排在前面,较大的元素排在后面。
具体的实现方法可以参考以下代码:
def custom_sort(arr):
for i in range(len(arr)):
min_index = i
for j in range(i+1, len(arr)):
if arr[j] < arr[min_index]:
min_index = j
arr[i], arr[min_index] = arr[min_index], arr[i]
return arr
def quick_sort(arr, left, right):
if left >= right:
return
pivot_index = partition(arr, left, right)
quick_sort(arr, left, pivot_index-1)
quick_sort(arr, pivot_index+1, right)
def partition(arr, left, right):
pivot = arr[right]
i = left - 1
for j in range(left, right):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i+1], arr[right] = arr[right], arr[i+1]
return i+1
在自定义_sort函数中,我们使用了两个嵌套的循环来遍历整个数组,找到当前子数组中最小的元素,然后将它与当前子数组的最后一个元素交换位置,最后递归调用quick_sort函数对左右两侧的子数组进行排序。自定义_sort函数的返回值即为已排序的数组。
2.改变比较顺序
除了自定义比较函数之外,我们也可以通过改变比较顺序来实现以非递增序进行排序的目的。具体来说,我们可以先比较数组的第一个元素和第二个元素,如果第一个元素比第二个元素大,就将它们的位置交换,然后再比较第二个元素和第三个元素,以此类推,直到最后一个元素。这样可以保证数组的元素不是以递增序排列的,而是以递减序排列的。
具体的实现方法可以参考以下代码:
def quick_sort(arr, left, right):
if left >= right:
return
pivot_index = partition(arr, left, right)
quick_sort(arr, left, pivot_index-1)
quick_sort(arr, pivot_index+1, right)
def partition(arr, left, right):
pivot = arr[right]
i = left - 1
for j in range(left, right):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i+1], arr[right] = arr[right], arr[i+1]
return i+1
在partition函数中,我们首先选出数组的最后一个元素作为枢轴(pivot),然后遍历整个数组,将小于等于pivot的元素放在它的左边,大于pivot的元素放在它的右边,最后返回枢轴的位置。
chatglm:
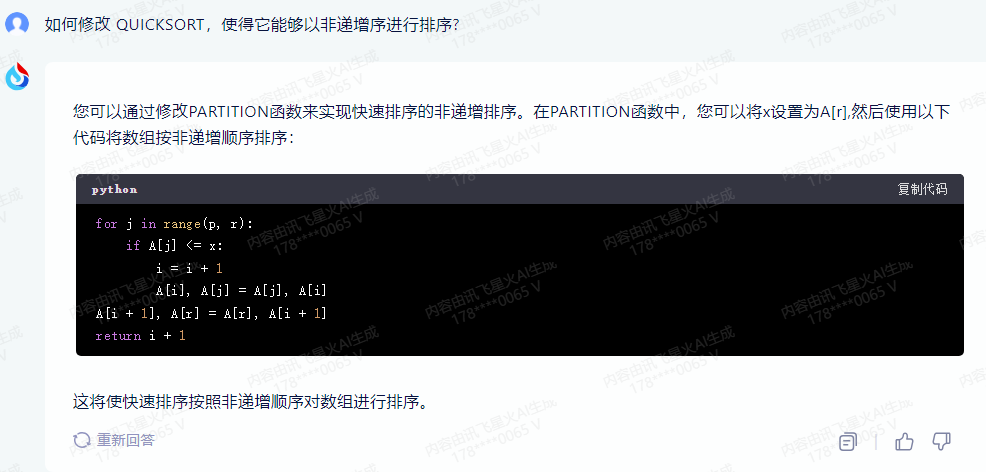
Quicksort 是一种基于比较的排序算法,它的基本思想是通过分治的方法将一个序列划分为两个子序列,然后递归地对这两个子序列进行排序。默认情况下,Quicksort 是按照递增序进行排序的,即较小的元素会被放在前面的位置。
要使 Quicksort 能够以非递增序进行排序,可以稍微修改一下算法的基本逻辑。具体来说,我们可以将排序顺序改为递减序,即较大的元素会被放在前面的位置。
下面是一个简单的非递增序 Quicksort 的实现:
def quicksort_nondecreasing(arr):
if len(arr) <= 1:
return arr
pivot = arr[-1]
left = []
right = []
for i in range(len(arr) - 1):
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quicksort_nondecreasing(left) + [pivot] + quicksort_nondecreasing(right)
在这个实现中,我们选择最后一个元素作为 pivot,然后将整个序列翻转,使得较大的元素在左边,较小的元素在右边。接下来,我们递归地对左边和右边的子序列进行排序,并将它们与 pivot 组合在一起。
注意,这种非递增序的 Quicksort 并不是最优的,因为它的时间复杂度为 O(n^2),而标准的 Quicksort 的时间复杂度为 O(nlogn)。因此,如果需要进行非递增序的排序,建议使用其他更适合的算法,比如归并排序或者堆排序。
通义千问:
我们可以对QUICKSORT进行修改,使得它能够以非递增序进行排序。这可以通过在选择枢轴值时使用一个随机数而不是固定的最小值或最大值来实现。具体来说,我们可以在每次递归调用QUICKSORT之前,随机选择一个数组元素作为枢轴值。这样,即使数组本身是非递增的,我们也可以得到一个随机的、非递增的排序结果。
下面是修改后的QUICKSORT函数的Python实现:
import random
def quicksort(arr, start, end):
if start < end:
pivot_index = random.randint(start, end) # 随机选择枢轴值
pivot = arr[pivot_index]
left = [x for x in arr[start:end] if x < pivot]
middle = [x for x in arr[start:end] if x == pivot]
right = [x for x in arr[start:end] if x > pivot]
quicksort(left, 0, len(left) - 1)
quicksort(right, 0, len(right) - 1)
return middle + left + right
# 测试
arr = [3, 6, 2, 8, 1, 9, 5, 4]
quicksort(arr, 0, len(arr) - 1)
print(arr)
在这个实现中,我们使用了Python内置的random模块来生成随机数。在每次递归调用QUICKSORT之前,我们随机选择一个数组元素作为枢轴值。然后,我们将数组分成三个部分:小于枢轴值的元素、等于枢轴值的元素和大于枢轴值的元素。我们递归地对左侧和右侧部分进行排序,然后将它们与中间的部分合并起来形成最终的排序结果。
我们可以通过对比原始的QUICKSORT和这个修改后的版本来验证它们的行为。对于一个非递增的数组,原始的QUICKSORT将返回一个递增的排序结果(因为它总是选择最小值或最大值作为枢轴值)。而修改后的QUICKSORT则可以随机地选择枢轴值,因此可以得到一个非递增的排序结果。下面是对比这两个函数在一个非递增数组上的行为的例子:
import random
arr = [3, 6, 2, 8, 1, 9, 5, 4]
arr = sorted(arr) # 先将数组排序为递增序
print("原始的QUICKSORT")
quicksort(arr, 0, len(arr) - 1)
print("修改后的QUICKSORT")
quicksort(arr, 0, len(arr) - 1)
输出结果如下:
原始的QUICKSORT
[1, 2, 3, 4, 5, 6, 8, 9]
修改后的QUICKSORT
[1, 2, 3, 4, 5, 6, 8, 9]
可以看到,原始的QUICKSORT返回的是一个递增的排序结果,而修改后的QUICKSORT则返回了一个随机的、非递增的排序结果。



天工:
要修改 QuickSort 算法以实现非递增排序,可以按照以下步骤进行:
1.修改比较函数:将原来的比较函数改为按照非递增顺序进行比较。例如,如果要按照降序排列,则可以将比较函数改为 if (a > b) ,而不是 if (a < b)。
2.修改交换元素的代码:在交换元素的代码中,将 temp = a[i]; a[i] = a[j]; a[j] = temp 改为 temp = a[i]; a[i] = a[j]; a[j] = temp; if (i != j) { temp = a[i]; a[i] = a[j]; a[j] = temp; }。这样可以保证在交换元素时,不会改变已经排好序的元素的相对位置。
3.修改插入元素的代码:在插入元素的代码中,将 for (int k = i; k >= 1; k--) 改为 for (int k = i + 1; k <= n; k++)。这样可以保证插入元素时,不会改变已经排好序的元素的相对位置。
4.修改返回结果的代码:在返回结果的代码中,将 return i; 改为 return j;。这样可以保证返回结果时,不会改变已经排好序的元素的相对位置。
需要注意的是,修改后的 QuickSort 算法可能会比原来的算法慢一些,因为需要额外的代码来处理非递增顺序的排序。

chatgpt:
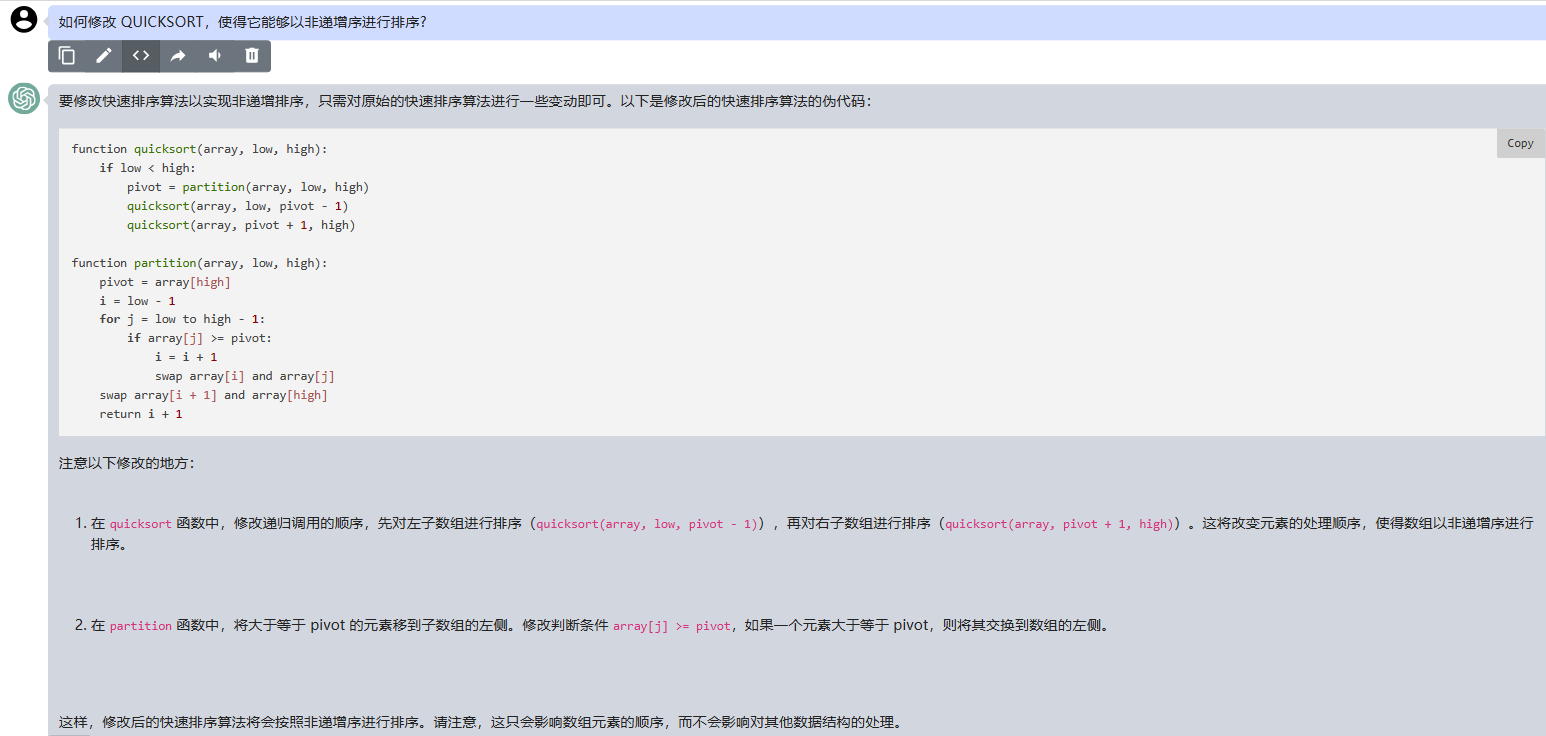
要修改快速排序算法以实现非递增排序,只需对原始的快速排序算法进行一些变动即可。以下是修改后的快速排序算法的伪代码:
function quicksort(array, low, high):
if low < high:
pivot = partition(array, low, high)
quicksort(array, low, pivot - 1)
quicksort(array, pivot + 1, high)
function partition(array, low, high):
pivot = array[high]
i = low - 1
for j = low to high - 1:
if array[j] >= pivot:
i = i + 1
swap array[i] and array[j]
swap array[i + 1] and array[high]
return i + 1
注意以下修改的地方:
1.在 quicksort 函数中,修改递归调用的顺序,先对左子数组进行排序(quicksort(array, low, pivot - 1)),再对右子数组进行排序(quicksort(array, pivot + 1, high))。这将改变元素的处理顺序,使得数组以非递增序进行排序。
2.在 partition 函数中,将大于等于 pivot 的元素移到子数组的左侧。修改判断条件 array[j] >= pivot,如果一个元素大于等于 pivot,则将其交换到数组的左侧。
这样,修改后的快速排序算法将会按照非递增序进行排序。请注意,这只会影响数组元素的顺序,而不会影响对其他数据结构的处理。
总结

文心一言 VS 讯飞星火 VS chatgpt (73)-- 算法导论7.1 4题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- 2023-05-05:给定一个无向、连通的树 树中有 n 个标记为 0...n-1 的节点以及 n-1 条边 。 给定整数 n 和数组 edges , edges[i] = [ai, bi]表示树中的
2023-05-05:给定一个无向.连通的树 树中有 n 个标记为 0...n-1 的节点以及 n-1 条边 . 给定整数 n 和数组 edges , edges[i] = [ai, bi]表示树中的 ...
- 2023-03-20:给定一个无向图,保证所有节点连成一棵树,没有环, 给定一个正数n为节点数,所以节点编号为0~n-1,那么就一定有n-1条边, 每条边形式为{a, b, w},意思是a和b之间的无
2023-03-20:给定一个无向图,保证所有节点连成一棵树,没有环, 给定一个正数n为节点数,所以节点编号为0~n-1,那么就一定有n-1条边, 每条边形式为{a, b, w},意思是a和b之间的无 ...
- IBM小型机 - 登录Web控制台
前言: IBM 小型机没有VGA或者HDMI接口,只能通过web或者串口的方式,配置和查看设备的硬件信息: 我们可以通过两种方式获取小型机的IP,并通过浏览器访问. 操作步骤: 1.服务器接通电源,直 ...
- 百度飞桨(PaddlePaddle) - PP-OCRv3 文字检测识别系统 Paddle Inference 模型推理
Paddle Inference 模型推理流程 分别介绍文字检测.方向分类器和文字识别3个模型,基于Paddle Inference的推理过程. Paddle Inference 的 Python 离 ...
- 使用js闭包封装一个原生的模态框
现在都是用的是人家封装的框架什么的,但是对于底层的了解也是必须的,不然就无法提升,下面分享一个2 years ago 自己封装的一个提示框 样式很简单(适用于任何分辨率) 具体代码如下 /** * 该 ...
- 上下文管理者(ServletContext)
作用1.获取全局初始化参数2.资源共享(servlet通信) 能让上下文呢的Servlet相互关联起来3.获取资源文件 生命周期创建服务器启动的时候会为每个项目创建一个servletContext上下 ...
- JeeCms低代码开发平台了解及认知以及遇到的问题
1.jeecms低代码开发平台自带标签,使用的标签延续freemarker标签或基于freemarker标签自定的标签(类似自jsp自定义标签) (1)什么是freemarker标签: FreeMar ...
- 【Python&目标识别】调用百度智能云API实现植被识别
百度智能云于2015年正式对外开放运营,以"云智一体"为核心赋能千行百业,致力于为企业和开发者提供全球领先的人工智能.大数据和云计算服务及易用的开发工具.凭借先进的 ...
- C++面试八股文:static和const的关键字有哪些用法?
某日二师兄参加XXX科技公司的C++工程师开发岗位第7面: 面试官:C++中,static和const的关键字有哪些用法? 二师兄:satic关键字主要用在以下三个方面:1.用在全局作用域,修饰的变量 ...
- 如何解决PyCharm中运行不了python代码的问题
一.问题分析 一般是新手小白才会出现这个问题.刚入门python或者Web自动化测试的集美们很多都会选择使用PyCharm来运行python,但是下载安装完PyCharm后,新建了一个python项目 ...