Paimon读取流程
查询模式
先来看看官网关于Paimon查询模式的说明

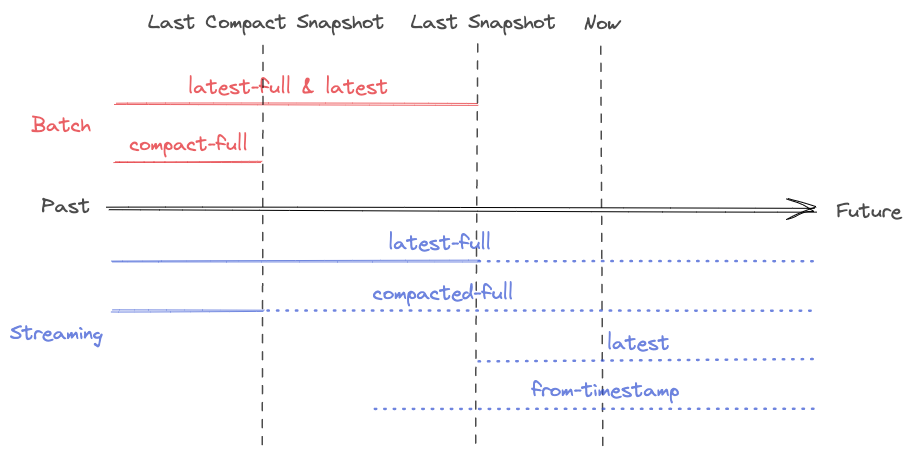
可以看到查询模式围绕snapshot展开, 而snapshot分了两种一种是Last compact snapshot和 last snapshot. 直接读last snapshot的话应该是需要merge on read. 而last compact snapshot 应该有点类似于hudi里面的Read Optimized Queries
Change log producer
上表中流读都提到需要读取变更流的数据.因此,Paimon表要有产生变更流的数据的能力. 内置了几种不同的changelog producer.
Changelog producer的含义是这张Paimon表的change log producer. 也就是用户写入数据后,如果对于这张表产生正确的change log. 这样下游才可以基于这个变更流进行增量的处理.
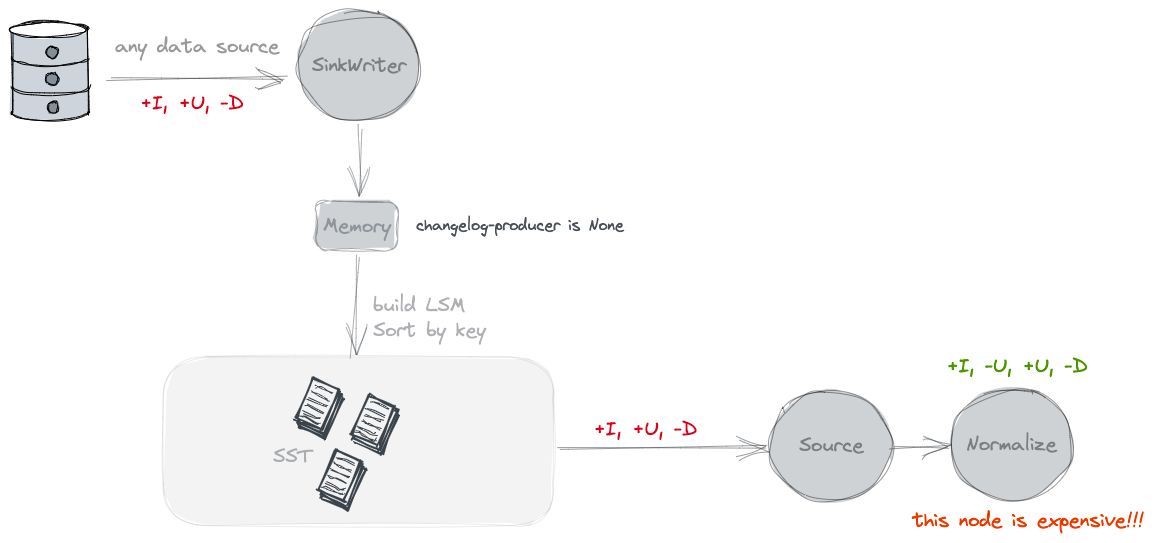
None
不单独产生Changelog文件. 按照官网的说法是只能看到snapshot之间的变化. 但是没有old value.
Paimon source can only see the merged changes across snapshots, like what keys are removed and what are the new values of some keys.
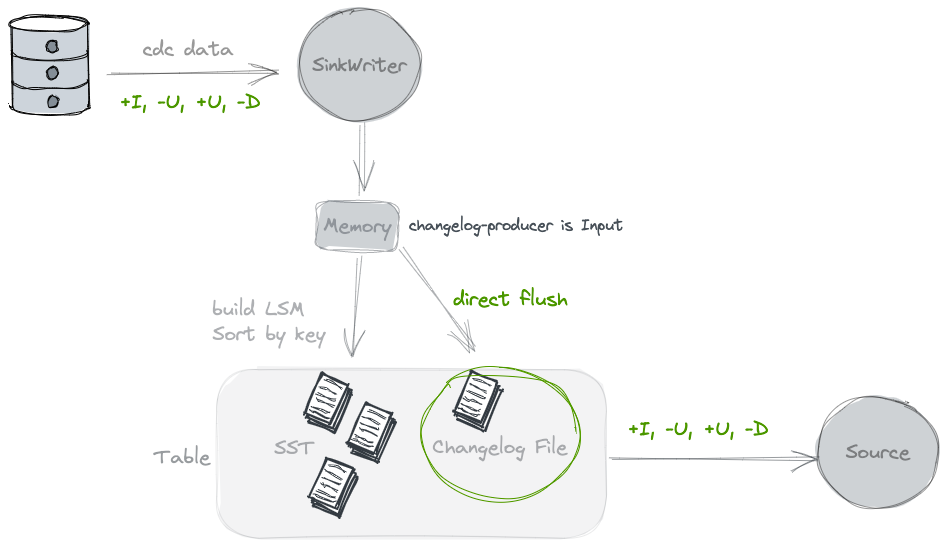
Input
在刷写数据的时候,会同时写一份Changelog的文件,提供给下游消费. 相当于为了流式能消费到变更流的视图, 需要将上游的变更流数据另外保存一份.
使用这种类型的clp的前提是, 基于输入数据已经能完全反应这张表的Changelog, 例如由CDC同步进来的数据,是可以的. 但是对于partial update 是不行的
// 如果配置了ChangelogProducer.INPUT 那么再刷写WriteBuffer的时候会同时将原始数据写入到changelog里面
final RollingFileWriter<KeyValue, DataFileMeta> changelogWriter =
changelogProducer == ChangelogProducer.INPUT
? writerFactory.createRollingChangelogFileWriter(0)
: null;
final RollingFileWriter<KeyValue, DataFileMeta> dataWriter =
writerFactory.createRollingMergeTreeFileWriter(0);
try {
// forEach会对原始数据的基于key的有序遍历
writeBuffer.forEach(
keyComparator,
mergeFunction,
changelogWriter == null ? null : changelogWriter::write,
dataWriter::write); // 最终使用的Orc/Parquet Writer来将数据写出
} finally {
if (changelogWriter != null) {
changelogWriter.close();
}
dataWriter.close();
}
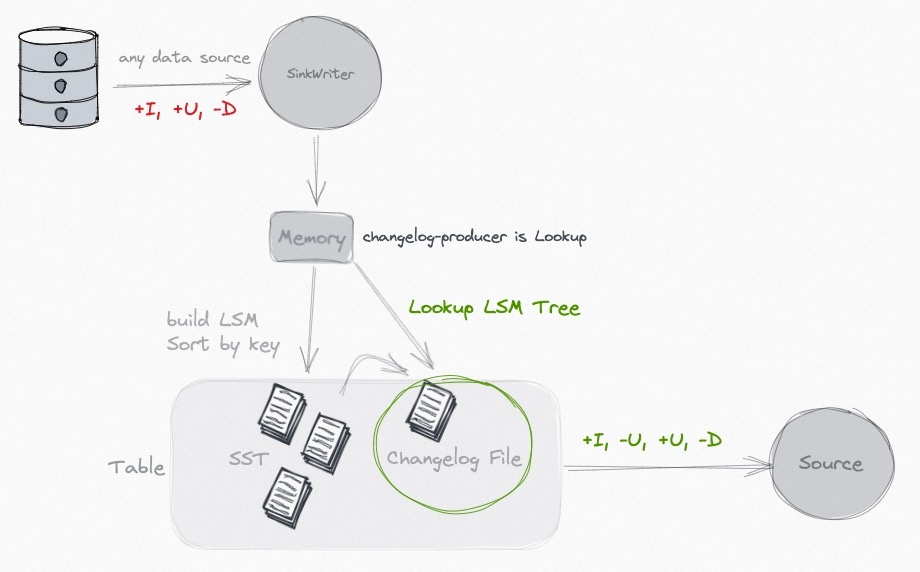
Lookup
当input无法形成一个完整的changelog, 比如partial update的场景中, 每个单独的input是没法产生changelog流的, changelog的过程实际和Compaction的merge过程相关
// 针对lookup的changelog producer 需要
// 1. 使用LookupCompaction CompactionStrategy
// 2. 使用LookupMergeTreeCompactRewriter
// 3. 使用LookupMergeFunction
LOOKUP(
"lookup",
"Generate changelog files through 'lookup' before committing the data writing.");
KeyValue result = mergeFunction.getResult();
checkArgument(result != null);
KeyValue highLevel = mergeFunction.highLevel;
boolean containLevel0 = mergeFunction.containLevel0;
// 1. No level 0, just return
// 没有level 0的数据, 意味着没有新数据产生
// 那么没有changelog文件产生, 只是高层文件的合并
if (!containLevel0) {
return reusedResult.setResult(result);
}
// 2. With level 0, with the latest high level, return changelog
// 先前的value也在此次的Compaction列表里面,直接就可以得出change log了
if (highLevel != null) {
setChangelog(highLevel, result);
return reusedResult.setResult(result);
}
// 3. Lookup to find the latest high level record
// 向更高level中查找这个key先前的数据, 为了产生变更流代价还是挺高的
// org.apache.paimon.mergetree.LookupLevels#lookup
highLevel = lookup.apply(result.key());
if (highLevel != null) {
mergeFunction2.reset();
mergeFunction2.add(highLevel);
mergeFunction2.add(result);
result = mergeFunction2.getResult();
setChangelog(highLevel, result);
} else {
setChangelog(null, result);
}
return reusedResult.setResult(result);
大致过程就是在Compaction的过程中会向高层的文件中查找该key的数据, 并根据查找结果来构建change log stream.
因为高层文件的key是有序的, 所以会通过二分法来过滤文件meta,快速定位到属于哪个文件. 但是因为这个文件是Parquet/Orc的列存文件, 无法直接根据key去高效查询的. 所以会先将原始数据读出,并重新成一个新的格式的文件,用于lookup探查, 主要是构建key的索引, 用于. HashLookupStoreWriter HashLookupStoreReader 主体逻辑可以参看
Full-compaction
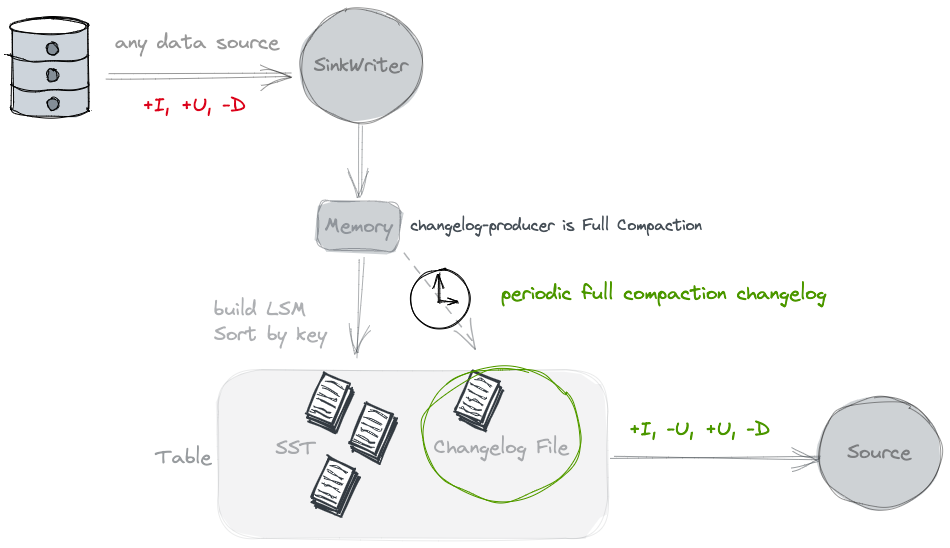
从上面的过程分析可以看出lookup的clp开销还是很大的,需要重读某个key的数据, 然后重新构建file cache, 再写出. 这里还提供了 full-compaction的方式.同lookup一样,这个也是在compaction阶段来产生的, 不过是full Compaction阶段.
Full compaction changelog producer can produce complete changelog for any type of source. However it is not as efficient as the input changelog producer and the latency to produce changelog might be high.
他可以支持任意类型的input,但是时延会比较高. 10min 往上
实现类 FullChangelogMergeTreeCompactRewriter 和 FullChangelogMergeFunctionWrapper
full compaction的时候不会产生delete的change log消息(大概是因为并不知道谁被delete了?)
在Full compaction阶段最后数据都会写到top level. 然后将最后合并后的数据和topLevel比较, 然后得出一个变更消息写到change log文件中.
对于离线场景的一般delete消息的需求
昨天新增今天删,昨天日增量分区有,今天增量分区没有 (也就是change log中并没有delete消息).昨天的日全量有,今天的日全量没有
今天新增今天删,今天的日增量分区没有,今天的日全量也没有
批读
| 批模式 | 流模式 | |
|---|---|---|
| latest-full | 读取最新的snapshot. 获取的是最近一次的snapshot | 先读取最新的snapshot, 然后持续读取变更流 |
| compacted-full | 读取最近一次Compaction之后的snapshot. | |
| 获取的snapshot是最近一次compaction的. 理论上这样读取阶段就不需要Merge On Read了 | 先读取最近一次Compaction之后的snapshot, 然后持续读取变更流 | |
| latest | 和latest-full一样 | 只读取最新变化的数据, 没有读取snapshot |
| from-timestamp | 读取一个早于或等于 scan.timestamp-millis指定时间戳的snapshot |
读取某个时间之后的数据, 不读取snapshot |
| from-snapshot | 读取scan.snapshot-id指定的某个snapshot id |
读取某个snapshot之后的数据, 不读取snapshot |
| from-snapshot-full | 读取scan.snapshot-id指定的某个snapshot id |
先读取某个snapshot, 然后持续读取其后的变化数据 |
PK表
StaticFileStoreSource
org.apache.paimon.table.source.AbstractInnerTableScan#createStartingScanner
InnerTable#newScan#plan (返回的Splits列表)
org.apache.paimon.table.AbstractFileStoreTable#newScan
org.apache.paimon.KeyValueFileStore#newScan()
org.apache.paimon.table.source.snapshot.SnapshotSplitReaderImpl#splits
org.apache.paimon.operation.AbstractFileStoreScan#plan 通过snapshot, 读取到相应的ManifestEntry 过滤出所有要读的文件
org.apache.paimon.table.source.snapshot.SnapshotSplitReaderImpl#generateSplits 对文件列表创建splits
org.apache.paimon.table.source.MergeTreeSplitGenerator#split 每个bucket内部进行splits切分, 提高读取的并行度
org.apache.paimon.flink.source.FileStoreSourceSplitReader
org.apache.paimon.table.source.KeyValueTableRead#createReader
org.apache.paimon.operation.KeyValueFileStoreRead#createReaderWithoutOuterProjection Merge On Read
Append 表
大体上和上面一样. 除了切分split的时候和创建reader的时候
org.apache.paimon.table.source.AppendOnlySplitGenerator#split
org.apache.paimon.operation.AppendOnlyFileStoreRead#createReader
流读
org.apache.paimon.table.AbstractFileStoreTable#newStreamScan
org.apache.paimon.table.source.AbstractInnerTableScan#createStartingScanner 创建一个初始的scan 这个和批模式很类似. 但是大部分流读都不会去读取Snapshot, 这个部分只是生成一个next Snapshot的id
org.apache.paimon.table.source.InnerStreamTableScanImpl#createFollowUpScanner 创建一个变更流的scan
变更流就和上面的Changelog producer息息相关, 每一种clp都有一个对应的变更流的planner. 用于根据Snapshot返回splits
- DeltaFollowUpScanner
- InputChangelogFollowUpScanner
- CompactionChangelogFollowUpScanner
- CompactionChangelogFollowUpScanner
并且也可以看到变更流的消费是跟着Snapshot走的, 在Stream 的 Source中会定期去获取splits, 就会触发定期Plan的获取, Plan的获取依赖于Snapshot. 所以读取的时延实际上Snapshot息息相关, 而Snapshot的产生又和上游的Checkpoint频率息息相关.
对于Append表 changelog 应该是delta 的数据, 是不是Append表应该只有DeltaFollowUpScanner 呢?
Lookup Join
Paimon还支持维表关联. 维表关联只支持all的模式. 会将数据全部load到本地(会有一些过滤下推), 并存储到Rocksdb中. 不会在关联的过程中直接去查询文件, 从上面的lookup changelog producer实现中也可以看出 kv的查询开销还是很大的.
参考
changelog-producer: https://paimon.apache.org/docs/master/concepts/primary-key-table/#changelog-producers
Paimon读取流程的更多相关文章
- HDFS写入和读取流程
HDFS写入和读取流程 一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而 ...
- 【Spring源码分析】配置文件读取流程
前言 Spring配置文件读取流程本来是和http://www.cnblogs.com/xrq730/p/6285358.html一文放在一起的,这两天在看Spring自定义标签的时候,感觉对Spri ...
- Android系统分析之运营商显示流程分析之运营商信息的读取流程二
运营商显示流程分析之运营商信息的读取流程 一. SIM卡运营商信息的读取 从前面的 运营商信息的获取和赋值 可以知道SIM卡运营商的赋值最终是在 SIMRecords 中完成的, 而SIM卡信息的相关 ...
- 8.hbase写入流程和读取流程
1 hbase写入流程 hbase中无论是新增数据还是修改已有行,其内部流程都是一样的,hbase执行写入时会写到两个地方,write-ahead log 简称wal 也叫hlog 预写式日志 和 M ...
- (第二章第一部分)TensorFlow框架之文件读取流程
本章概述:在第一章的系列文章中介绍了tf框架的基本用法,从本章开始,介绍与tf框架相关的数据读取和写入的方法,并会在最后,用基础的神经网络,实现经典的Mnist手写数字识别. 有四种获取数据到Tens ...
- HBase读取与写入流程
写入流程 读取流程 https://yq.aliyun.com/articles/670748?spm=a2c4e.11153940.blogcont684011.28.427e4648CTtaPL
- 2017.2.28 activiti实战--第五章--用户与组及部署管理(三)部署流程及资源读取
学习资料:<Activiti实战> 第五章 用户与组及部署管理(三)部署流程及资源读取 内容概览:如何利用API读取已经部署的资源,比如读取流程定义的XML文件,或流程对应的图片文件. 以 ...
- [spring源码学习]三、IOC源码——自定义配置文件读取
一.环境准备 在文件读取的时候,第9步我们发现spring会根据标签的namespace来选择读取方式,联想spring里提供的各种标签,比如<aop:xxx>等应该会有不同的读取和解析方 ...
- activiti自定义流程之整合(五):启动流程时获取自定义表单
流程定义部署之后,自然就是流程定义列表了,但和前一节一样的是,这里也是和之前单独的activiti没什么区别,因此也不多说.我们先看看列表页面以及对应的代码,然后在一步步说明点击启动按钮时如何调用自定 ...
- shell启动时读取的配置文件
bash shell具体可以分为3种类型,这3种类型为: 1 login shell 就是需要输入用户名和密码才能登陆的shell 2 可交互的非login shell 就是不用登陆的,但是可以同用户 ...
随机推荐
- String API(全)
类型 名称 char charAt(int index)返回 char指定索引处的值. int codePointAt(int index)返回指定索引处的字符(Unicode代码点). int co ...
- Django笔记十六之aggregate聚合操作
本文首发于微信公众号:Hunter后端 原文链接:Django笔记十六之aggregate聚合操作 这一篇笔记介绍一下关于聚合的操作,aggregate. 常用的聚合操作比如有平均数,总数,最大值,最 ...
- kubernetes核心实战(四)--- Deployments
6.Deployments(重点) 一个 Deployment 控制器为 Pods和 ReplicaSets提供描述性的更新方式. 描述 Deployment 中的 desired state,并且 ...
- Python3.8环境安装PyHook3
Python3.8环境安装PyHook3 1. 安装python对应版本的pyhook3网 址:https://pypi.org/project/PyHook3/#files如果没有对应版本,请下载 ...
- Unity学习笔记02 —— C#语法
C#语法 控制台 Console Console.WriteLine(); Console.ReadLine(); 随机数 Random Random random = new Random(); r ...
- Android开发_记事本(1)
一些知识 Textview TextView中有下述几个属性: id:为TextView设置一个组件id,根据id,我们可以在Java代码中通过findViewById()的方法获取到该对象,然后进行 ...
- APISIX 是怎么保护用户的敏感数据不被泄露的?
本文以 APISIX 作为例子,为大家介绍了如何借助 Global Data Encryption 功能来保护敏感数据,确保不会有任何敏感数据进行明文存储,这样即使 etcd 中所有存储的数据都被盗取 ...
- C# 一个List 分成多个List
/// <summary> /// 一个List拆分多个List /// </summary> /// <param name= ...
- hasOwnProperty的作用、配合for in使用 、key in Object判读key
我们都知道,对象以 key|value的形式存在 它和数组一样可以遍历,对象可以通过for in 去遍历,拿到遍历对象的所有key 某些idea在使用for in 时,提示代码片段中就有出现以下这种情 ...
- Django笔记三十四之分页操作
本文首发于公众号:Hunter后端 原文链接:Django笔记三十四之分页操作 这一篇笔记介绍一下如何在 Django 使用分页. Django 自带一个分页的模块: from django.core ...