我也来扒一扒python的内存回收机制!
python的内存回收是面试中经常会问到一个问题,今天我来给大家深度剖析下python的内存回收和缓存机制
1、引用计数器
我们知道,python是通过引用计数器来做内存回收的,下面我们来重点讲下引用计数器
提到引用计数器,我们需要先讲下python中的环状双向链表refchain。
1.1 双向链表refchain
在python程序中,创建的任意一个对象,都会加到这个refchain双向链表中
不同的类型的对象在放到refchain中会有不同的地方,也会有相同的地方
1.2 refchain结构体
可以看下,cpython中的源码中定义的结构体

PyObject这个结构体封装了四个值,其他类型的对象会基于PyObject这个结构体作为基类,在封装其他需要的类型
下面我们看不同给类型的结构体封装格式
比如float类型

比如int类型

list类型

tuple类型

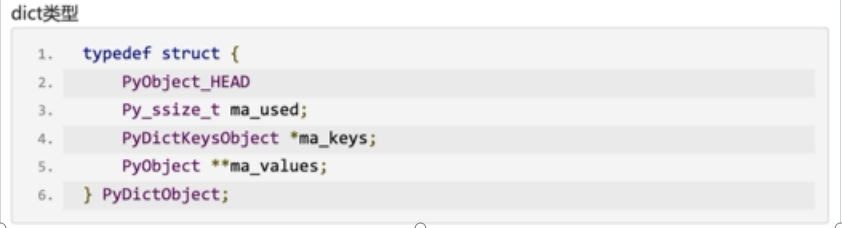
dict类型
1.3 引用计数器
我们上面讲的 引用计数器
Ob_refcnt就是引用计数器,默认是1,当有其他对象引用对象的时候,这个值就会发生变化
name = "test" #ob_refcnt的值是1 new = name #ob_refcnt的值是2 del new #ob_refcnt的值是1
当ob_refcnt为0的时候,就会对该对象做垃圾回收,会做两件事情
1、从refchain双向链表中移除
2、将这个对象进行销毁,归还内存给操作系统
2、标记清除
大家认为引用计数器的方式很牛逼,但是其实这里有个场景,引用计数器是解决不了的
# 存在双向引用的场景,引用计数器就会出问题
v1 = [1,2,3] v2 = [4,5,6] v1.append(v2) v2.append(v1) # 此时
# v1的ob_refcnt为2
# v2的ob_refcnt为2 del v1
del v2 # 此时
# v1的ob_refcnt为1
# v2的ob_refcnt为1
#
# 此时v1和v2不会被回收,但是其实已经没有对象引用v1和v2了 此时就会出现内存泄露的现象
为了解决上面的场景,python又引入了标记清除
在python底层,会维护另外一个链表(A),这个链表中存放可能存在双向应用的对象。在python中,只有list,tupule、dict、set会存在双向引用的场景,如果我们创建这样的对象,这个对象会被存在到两个链表中
在python内部,会有规律的扫描这个链表A中的每个元素,检查是否有双向引用,如果有,会让双方的引用计数器分别减1,然后在判断ob_refcnt来判断是否做垃圾回收
3、分代回收
那在链表A中,扫描一次链表A还是比较耗时的,因为每个元素都要扫描一次,扫描一次的代价比较大,python是以什么规律下会触发扫描链表A呢?
在分代回收中,把链表A中的数据,也就是可能存在双向引用的元素,划成3个链表,依次来提升扫描的效率
0代:0代中的对象个数达到700个,在触发扫描一次0代链表;第一次扫描0代中的对象,如果0代中有垃圾,则回收,如果不是垃圾,则清空0代,把不是 垃圾的对象放到1代
1代:0代扫描超过10次,则1代扫描一次
如果1代中有垃圾,则回收,如果不是垃圾,则清空1代,把不是 垃圾的对象放到2代
2代:1代扫描超过10次,则2代扫描一次
如果2代中有垃圾,则回收,如果不是垃圾,则清空2代
4、缓存机制
Python中还有些内存管理的机制,用来优化性能,就是这里准备讲的缓存机制
4.1 池
在python中,为了避免重复申请内存和销毁内存,python会对一部分常见的对象,会提前把这些常见的对象提前申请好
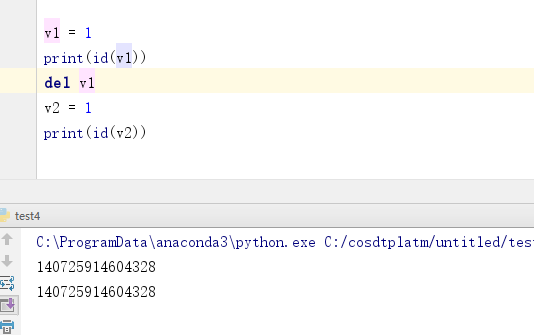
Int类型是用池来做缓存
比如 -5,-4 .。。。。。。。256 这部分对象python认为非常常用,会在python启动的时候提前创建好对象,且不会去走销毁流程,
可以看到v1和v2的内存地址是一样的
4.2 free_list机制
Free_list机制(float、tupule、list、dict为典型代表)
当引用计数器ob_refcnt为0的时候,按理说应该回收的,但是在python中,为了优化性能,不会回收,而是将对象添加到free_list链表中,当作缓存,以后再次创建相同的对象,就会重新创建对象,而是直接使用free_list中的对象
v3 = 3.14 del v3 #会放到free_list中 v4 = 4.14 #会对v3的内存地址重新赋值,就不需要重新申请内存
float类型
# float类型,维护free_list链表中最多可以缓存100个float对象
v9 = 3.14
print(id(v9))
del v3 #会放到free_list中 v10 = 3.14 #会对v3的内存地址重新赋值,就不需要重新申请内存
print(id(v10)) # 当前引用计数器为0的时候,会先去判断free_list是否满,未满在缓存到free_list中,满了则销毁
list类型
# list类型,维护一个free_list对多可缓存个80个list对象 v11 = [1,2,3]
print(id(v11))
del v11 v11 = ["2b","2b"]
print(id(v11)) # 输出
# 2303949405888
# 2303949405888
dict类型
# dict类型,会维护一个free_list最多可缓存80个dict对象
v13 = {"k1":"v1","k2":"v2"}
print(id(v13))
del v13 v13 = {"k3":"v1","k4":"v2"}
print(id(v13)) # 2291100371392
# 2291100371392
tuple类型
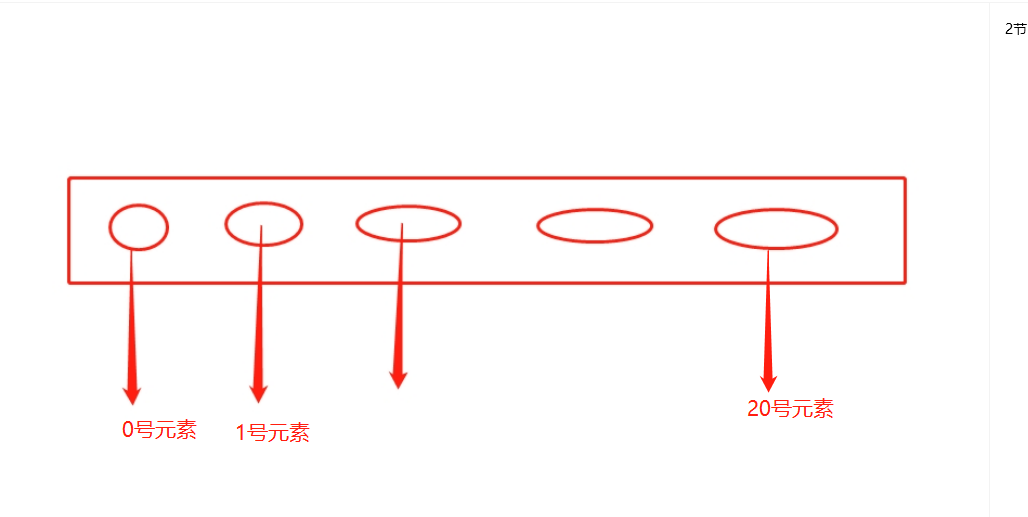
会维护一个20个元素的free_list的表。其中0号元素,缓存在只有一个元素的tuple,1号元素缓存只有2个元素的tuple。。。。。。20号元素缓存只有21个元素的tuple。其中每个元素中最多可以存储2000个列表
str类型
1、首先会把所有的ascii码元素全部会缓存起来,不会销毁
2、除此之外,python还对常用的字符串做了驻留机制,争对只有数字,字母,下划线组成的字符串做了驻留缓存,如果内存中存在相同的值,则不会去重新申请内存,而是直接使用驻留内存中的地址
我也来扒一扒python的内存回收机制!的更多相关文章
- python的内存回收机制
变量相当于门牌号,当门牌没有了,即函数的引用都没有调用了,内存的数据就会被清除掉. python内有个定时器,定期的会刷新,如果发现内存中数据被引用了,就会被回收,这个就是内存的回收机制 ...
- python的内存回收机制即gc模块讲解
最后容易造成内存问题的通常就是全局单例.全局缓存.长期存活的对象 引用计数(主要), 标记清除, 分代收集(辅助) 引用计数为0则会被gc回收.标记删除可以解决循环引用的问题.分代:0代--年轻代:1 ...
- python 的内存回收,及深浅Copy详解
一.python中的变量及引用 1.1 python中的不可变类型: 数字(num).字符串(str).元组(tuple).布尔值(bool<True,False>) 接下来我们讲完后你就 ...
- python的内存管理机制
先从较浅的层面来说,Python的内存管理机制可以从三个方面来讲 (1)垃圾回收 (2)引用计数 (3)内存池机制 一.垃圾回收: python不像C++,Java等语言一样,他们可以不用事先声明变量 ...
- 详解python的垃圾回收机制
python的垃圾回收机制 一.引子 我们定义变量会申请内存空间来存放变量的值,而内存的容量是有限的,当一个变量值没有用了(简称垃圾)就应该将其占用的内存空间给回收掉,而变量名是访问到变量值的唯一方式 ...
- 谈一谈python的垃圾回收机制
[python的垃圾回收机制是怎么实现的] 在C语言时代程序员要负责内存的申请和释放,虽然这样的程序可以对资源进行精细的控制.但是它也有它的问题.这就要求程序员 要写许多与业务逻辑无关的内容在代码里面 ...
- python中垃圾回收机制
Python垃圾回收机制详解 一.垃圾回收机制 Python中的垃圾回收是以引用计数为主,分代收集为辅.引用计数的缺陷是循环引用的问题.在Python中,如果一个对象的引用数为0,Python虚拟 ...
- python的内存管理机制(zz)
本文转载自:http://www.cnblogs.com/CBDoctor/p/3781078.html 先从较浅的层面来说,Python的内存管理机制可以从三个方面来讲 (1)垃圾回收 (2)引用计 ...
- python的垃圾回收机制和析构函数__del__
析构函数__del__定义:在类里定义,如果不定义,Python 会在后台提供默认析构函数. 析构函数__del__调用: A.使用del 显式的调用析构函数删除对象时:del对象名: class F ...
- python之垃圾回收机制
一.前言 Python 是一门高级语言,使用起来类似于自然语言,开发的时候自然十分方便快捷,原因是Python在背后为我们默默做了很多事情,其中一件就是垃圾回收,来解决内存管理,内存泄漏的问题. 内存 ...
随机推荐
- 函数strncpy和memcpy的区别
1定义 1.1 memcpy void *memcpy(void *destin, void *source, unsigned n); 参数 *destin ---- 需要粘贴的新数据(地址) *s ...
- 02-初识Verilog
1.开发环境搭建 需要使用的软件: QuartusII ModelSim Visio Notepad++ 2.初识Verilog 2.1 Verilog HDL简介 Verilog HDL是一种硬件描 ...
- 代码随想录算法训练营Day42 动态规划
代码随想录算法训练营 代码随想录算法训练营Day40 动态规划|01背包问题,你该了解这些! 01背包问题,你该了解这些!滚动数组 416. 分割等和子集 01背包问题,你该了解这些! 完全背包又是也 ...
- WPF入门教程系列二十六——DataGrid使用示例(3)
WPF入门教程系列目录 WPF入门教程系列二--Application介绍 WPF入门教程系列三--Application介绍(续) WPF入门教程系列四--Dispatcher介绍 WPF入门教程系 ...
- 判断两个矩形是否相交(Rect Intersection)
0x00 Preface 最近在开发一个2D组态图形组件的过程中,里面的数学模块,涉及到两个矩形是否相交的判断. 这个问题很多年前就写过,算是个小的算法吧. 网络上搜索一下,有很多思路,有一些思路要基 ...
- Redis数据结构:高频面试题及解析
概述 Redis 是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映射. 键的类型只能为字符串,值支持五种数据类型:字符串.列表.集合.散列表.有序集合. Red ...
- CMU15445 (Fall 2020) 数据库系统 Project#2 - B+ Tree 详解(上篇)
前言 考虑到 B+ 树较为复杂,CMU15-445 将 B+ 树实验拆成了两部分,这篇博客将介绍 Checkpoint#1 部分的实现过程,搭配教材 <DataBase System Conce ...
- 2023-06-18:给定一个长度为N的一维数组scores, 代表0~N-1号员工的初始得分, scores[i] = a, 表示i号员工一开始得分是a, 给定一个长度为M的二维数组operatio
2023-06-18:给定一个长度为N的一维数组scores, 代表0~N-1号员工的初始得分, scores[i] = a, 表示i号员工一开始得分是a, 给定一个长度为M的二维数组operatio ...
- 从GaussDB(DWS)的技术演进,看数据仓库的积淀与新生
摘要:随着云计算的兴起和渗透,云数仓成为了数仓技术演进的新阶段,并且逐渐成为了众多企业的共同选择. 本文分享自华为云社区<从GaussDB(DWS)的技术演进,看数据仓库的积淀与新生>,作 ...
- APP流水线测试领域探索与最佳实践
1 背景 APP端UI自动化因其特殊性(需连接测试机)一般都在本地执行,这种执行方式的局限性有以下弊端: 时效性低:研发每次打包后都需要通知测试,测试再去打包平台取包,存在时间差 研发自测或产品验收无 ...