分类树,我从2s优化到0.1s
前言
Java技术突击网站:http://www.susan.net.cn
分类树查询功能,在各个业务系统中可以说随处可见,特别是在电商系统中。

但就是这样一个简单的分类树查询功能,我们却优化了5次。
到底是怎么回事呢?
背景
我们的网站使用了SpringBoot推荐的模板引擎:Thymeleaf,进行动态渲染。
它是一个XML/XHTML/HTML5模板引擎,可用于Web与非Web环境中的应用开发。
它提供了一个用于整合SpringMVC的可选模块,在应用开发中,我们可以使用Thymeleaf来完全代替JSP或其他模板引擎,如Velocity\FreeMarker等。
前端开发写好Thymeleaf的模板文件,调用后端接口获取数据,进行动态绑定,就能把想要的内容展示给用户。
由于当时这个是从0-1的新项目,为了开快速开发功能,我们第一版接口,直接从数据库中查询分类数据,组装成分类树,然后返回给前端。
通过这种方式,简化了数据流程,快速把整个页面功能调通了。
第1次优化
我们将该接口部署到dev环境,刚开始没啥问题。
随着开发人员添加的分类越来越多,很快就暴露出性能瓶颈。
我们不得不做优化了。
我们第一个想到的是:加Redis缓存。
流程图如下:
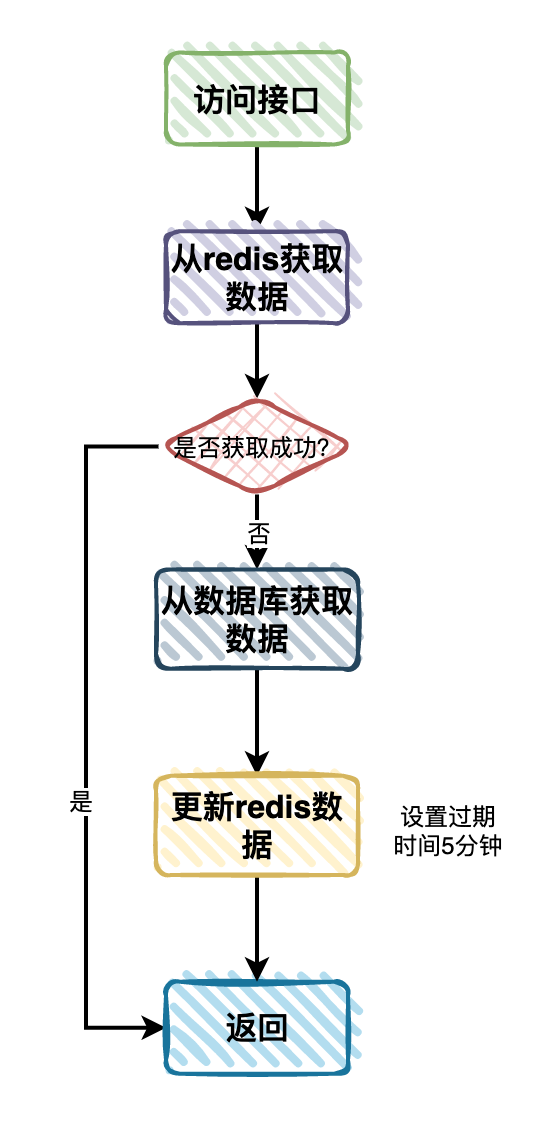
于是暂时这样优化了一下:
- 用户访问接口获取分类树时,先从Redis中查询数据。
- 如果Redis中有数据,则直接数据。
- 如果Redis中没有数据,则再从数据库中查询数据,拼接成分类树返回。
- 将从数据库中查到的分类树的数据,保存到Redis中,设置过期时间5分钟。
- 将分类树返回给用户。
我们在Redis中定义一个了key,value是一个分类树的json格式转换成了字符串,使用简单的key/value形式保存数据。
经过这样优化之后,dev环境的联调和自测顺利完成了。
第2次优化
我们将这个功能部署到st环境了。
刚开始测试同学没有发现什么问题,但随着后面不断地深入测试,隔一段时间就出现一次首页访问很慢的情况。
于是,我们马上进行了第2次优化。
我们决定使用Job定期异步更新分类树到Redis中,在系统上线之前,会先生成一份数据。
当然为了保险起见,防止Redis在哪条突然挂了,之前分类树同步写入Redis的逻辑还是保留。
于是,流程图改成了这样:

增加了一个job每隔5分钟执行一次,从数据库中查询分类数据,封装成分类树,更新到Redis缓存中。
其他的流程保持不变。
此外,Redis的过期时间之前设置的5分钟,现在要改成永久。
通过这次优化之后,st环境就没有再出现过分类树查询的性能问题了。
第3次优化
测试了一段时间之后,整个网站的功能快要上线了。
为了保险起见,我们需要对网站首页做一次压力测试。
果然测出问题了,网站首页最大的qps是100多,最后发现是每次都从Redis获取分类树导致的网站首页的性能瓶颈。
我们需要做第3次优化。
该怎么优化呢?
答:加内存缓存。
如果加了内存缓存,就需要考虑数据一致性问题。
内存缓存是保存在服务器节点上的,不同的服务器节点更新的频率可能有点差异,这样可能会导致数据的不一致性。
但分类本身是更新频率比较低的数据,对于用户来说不太敏感,即使在短时间内,用户看到的分类树有些差异,也不会对用户造成太大的影响。
因此,分类树这种业务场景,是可以使用内存缓存的。
于是,我们使用了Spring推荐的caffine作为内存缓存。
改造后的流程图如下:
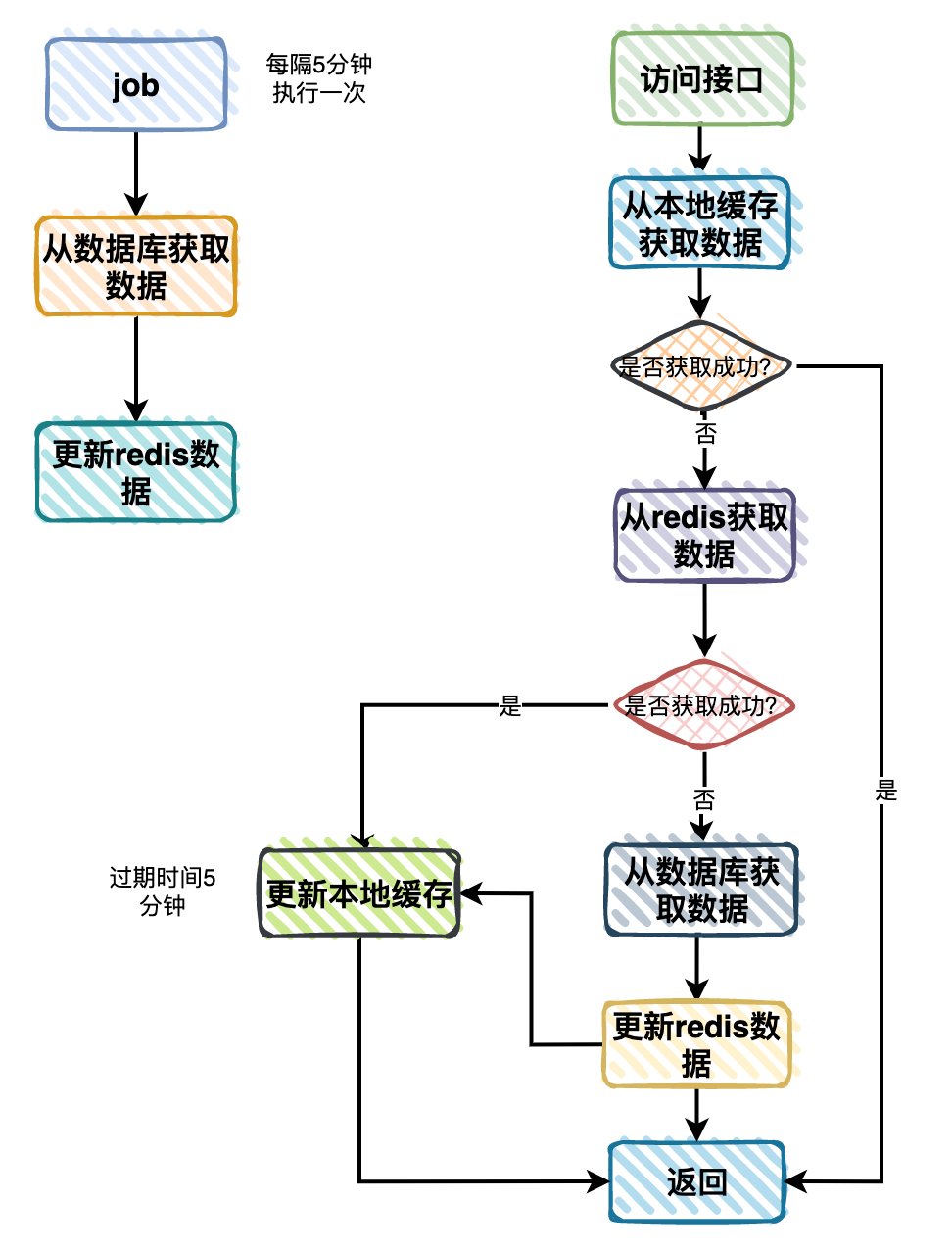
- 用户访问接口时改成先从本地缓存分类数查询数据。
- 如果本地缓存有,则直接返回。
- 如果本地缓存没有,则从Redis中查询数据。
- 如果Redis中有数据,则将数据更新到本地缓存中,然后返回数据。
- 如果Redis中也没有数据(说明Redis挂了),则从数据库中查询数据,更新到Redis中(万一Redis恢复了呢),然后更新到本地缓存中,返回返回数据。
需要注意的是,需要改本地缓存设置一个过期时间,这里设置的5分钟,不然的话,没办法获取新的数据。
这样优化之后,再次做网站首页的压力测试,qps提升到了500多,满足上线要求。
第4次优化
之后,这个功能顺利上线了。
使用了很长一段时间没有出现问题。
两年后的某一天,有用户反馈说,网站首页有点慢。
我们排查了一下原因发现,分类树的数据太多了,一次性返回了上万个分类。
原来在系统上线的这两年多的时间内,运营同学在系统后台增加了很多分类。
我们需要做第4次优化。
这时要如何优化呢?
限制分类树的数量?
答:也不太现实,目前这个业务场景就是有这么多分类,不能让用户选择不到他想要的分类吧?
这时我们想到最快的办法是开启nginx的GZip功能。
让数据在传输之前,先压缩一下,然后进行传输,在用户浏览器中,自动解压,将真实的分类树数据展示给用户。
之前调用接口返回的分类树有1MB的大小,优化之后,接口返回的分类树的大小是100Kb,一下子缩小了10倍。
这样简单的优化之后,性能提升了一些。
第5次优化
经过上面优化之后,用户很长一段时间都没有反馈性能问题。
但有一天公司同事在排查Redis中大key的时候,揪出了分类树。之前的分类树使用key/value的结构保存数据的。
我们不得不做第5次优化。
为了优化在Redis中存储数据的大小,我们首先需要对数据进行瘦身。
只保存需要用到的字段。
例如:
@AllArgsConstructor
@Data
public class Category {
private Long id;
private String name;
private Long parentId;
private Date inDate;
private Long inUserId;
private String inUserName;
private List<Category> children;
}
像这个分类对象中inDate、inUserId和inUserName字段是可以不用保存的。
修改自动名称。
例如:
@AllArgsConstructor
@Data
public class Category {
/**
* 分类编号
*/
@JsonProperty("i")
private Long id;
/**
* 分类层级
*/
@JsonProperty("l")
private Integer level;
/**
* 分类名称
*/
@JsonProperty("n")
private String name;
/**
* 父分类编号
*/
@JsonProperty("p")
private Long parentId;
/**
* 子分类列表
*/
@JsonProperty("c")
private List<Category> children;
}
由于在一万多条数据中,每条数据的字段名称是固定的,他们的重复率太高了。
由此,可以在json序列化时,改成一个简短的名称,以便于返回更少的数据大小。
这还不够,需要对存储的数据做压缩。
之前在Redis中保存的key/value,其中的value是json格式的字符串。
其实RedisTemplate支持,value保存byte数组。
先将json字符串数据用GZip工具类压缩成byte数组,然后保存到Redis中。
再获取数据时,将byte数组转换成json字符串,然后再转换成分类树。
这样优化之后,保存到Redis中的分类树的数据大小,一下子减少了10倍,Redis的大key问题被解决了。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:面试、代码神器、开发手册、时间管理有超赞的粉丝福利,另外回复:加群,可以跟很多BAT大厂的前辈交流和学习。
分类树,我从2s优化到0.1s的更多相关文章
- C#无限极分类树-创建-排序-读取 用Asp.Net Core+EF实现
今天做一个管理后台菜单,想着要用无限极分类,记得园子里还是什么地方见过这种写法,可今天找了半天也没找到,没办法静下心来自己写了: 首先创建节点类(我给它取名:AdminUserTree): /// & ...
- ecshop显示所有分类树栏目
1.找到 category.php 和goods.php 两个文件修改: $smarty->assign('categories', get_categories_tree(0)); // 分类 ...
- 决策树算法原理(CART分类树)
决策树算法原理(ID3,C4.5) CART回归树 决策树的剪枝 在决策树算法原理(ID3,C4.5)中,提到C4.5的不足,比如模型是用较为复杂的熵来度量,使用了相对较为复杂的多叉树,只能处理分类不 ...
- OneThink生成分类树方法(list_to_tree)使用!
具体方法: Application / Common / Common / function.php 下的 224行: function list_to_tree($list, $pk='id', $ ...
- 【BZOJ4311】向量(线段树分治,斜率优化)
[BZOJ4311]向量(线段树分治,斜率优化) 题面 BZOJ 题解 先考虑对于给定的向量集,如何求解和当前向量的最大内积. 设当前向量\((x,y)\),有两个不同的向量\((u1,v1),(u2 ...
- sklearn 学习之分类树
概要 基于 sklearn 包自带的 iris 数据集,了解一下分类树的各种参数设置以及代表的意义. iris 数据集介绍 iris 数据集包含 150 个样本,对应数据集的每行数据,每行数据包含 ...
- B树索引与索引优化
B树索引与索引优化 MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为“BTREE”),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引 ...
- C#开发BIMFACE系列27 服务端API之获取模型数据12:获取构件分类树
系列目录 [已更新最新开发文章,点击查看详细] BIMFACE官方示例中,加载三维模型后,模型浏览器中左上角默认提供了“目录树”的功能,清晰地展示了模型的完整构成及上下级关系. 本篇介绍如何获 ...
- php 两种获取分类树的方法
php 两种获取分类树的方法 1. /** * 获取分类树 * @param array $array 数据源 * @param int $pid 父级ID * @param int $level 分 ...
- Sklearn分类树在合成数集上的表现
小伙伴们大家好~o( ̄▽ ̄)ブ,今天我们开始来看一下Sklearn分类树的表现,我的开发环境是Jupyter lab,所用的库和版本大家参考: Python 3.7.1(你的版本至少要3.4以上) S ...
随机推荐
- 第七章ssh sftp scp
第七章ssh sftp scp 对数据进行了加密和压缩 版本号协商,可能客户端和服务端的版本号不一致,服务端向客户端发送一个ssh协商,告诉客户端使用的ssh协议的版本号是多少,客户端在接收到了这个协 ...
- docker学习3
docker的启动流程 docker run -t -i <name:tag> /bin/bash -t 把1个伪终端绑定到容器的标准输入 -i 保持容器的标准输入始终打开不关闭 启动流程 ...
- AbstractRoutingDataSource - 动态数据源
AbstractRoutingDataSource 类说明: (1)它的抽象方法 determineCurrentLookupKey() 决定使用哪个数据源. (2)项目启动时,先调用 setTarg ...
- 远程链接linux编程shell脚本
WinSCP-5.15.3-Setup.exe https://pan.baidu.com/s/1zr7ipq8i5rqm8tYS8GeKsQ
- 如何使用Mutex确保并发程序的正确性
1. 简介 本文的主要内容是介绍Go中Mutex并发原语.包含Mutex的基本使用,使用的注意事项以及一些实践建议. 2. 基本使用 2.1 基本定义 Mutex是Go语言中的一种同步原语,全称为Mu ...
- Python自动化环境搭建轻轻松松---selenium
其实安装selenium实现自动化搭建环境也不拿 一共四步 1.Python开发环境 2.安装selenium包 3.安装浏览器 4.安装你安装的浏览器驱动 一: 想要实现Python环境不可能缺席: ...
- 20个值得收藏的实用JavaScript技巧
1.确定对象的数据类型 function myType(type) { return Object.prototype.toString.call(type).slice(8, -1); 使用Obje ...
- SpringBoot——日志及原理
一.SpringBoot日志 选用 SLF4j(接口)和 logback(实现类),除了上述日志框架,市场上还存在 JUL(java.util.logging).JCL(Apache Commons ...
- Kingpin Private Browser - 隐私保护浏览器,隐身模式、广告拦截做你的私人浏览器
Kingpin Private Browser 是一个功能齐全的浏览器,隐身模式和广告拦截总是启用.它不会记住历史记录.密码或cookie.默认情况下,浏览器使用谷歌搜索(您可以在设置中将其更改为Du ...
- Python常见面试题017: Python中是否可以获取类的所有实例
017. Python中是否可以获取类的所有实例 转载请注明出处,https://www.cnblogs.com/wuxianfeng023 出处 https://docs.python.org/zh ...