Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:算子和分区
一、reduce和reduceByKey:

二、:RDD 的算子总结
- RDD 的算子大部分都会生成一些专用的 RDD
-
map,flatMap,filter等算子会生成MapPartitionsRDDcoalesce,repartition等算子会生成CoalescedRDD
- 常见的 RDD 有两种类型
-
转换型的 RDD, Transformation
动作型的 RDD, Action
- 常见的 Transformation 类型的 RDD
-
map
flatMap
filter
groupBy
reduceByKey
- 常见的 Action 类型的 RDD
-
collect
countByKey
reduce
2.3. RDD 对不同类型数据的支持
理解 RDD 对 Key-Value 类型的数据是有专门支持的
理解 RDD 对数字类型也有专门的支持
- 一般情况下 RDD 要处理的数据有三类
-
字符串
键值对
数字型
- RDD 的算子设计对这三类不同的数据分别都有支持
-
对于以字符串为代表的基本数据类型是比较基础的一些的操作, 诸如 map, flatMap, filter 等基础的算子
对于键值对类型的数据, 有额外的支持, 诸如 reduceByKey, groupByKey 等 byKey 的算子
同样对于数字型的数据也有额外的支持, 诸如 max, min 等
- RDD 对键值对数据的额外支持:
键值型数据本质上就是一个二元元组, 键值对类型的 RDD 表示为 RDD[(K, V)]
-
RDD 对键值对的额外支持是通过隐式支持来完成的, 一个
RDD[(K, V)], 可以被隐式转换为一个PairRDDFunctions对象, 从而调用其中的方法.
- 既然对键值对的支持是通过
PairRDDFunctions提供的, 那么从PairRDDFunctions中就可以看到这些支持有什么
类别 算子 聚合操作
reduceByKeyfoldByKeycombineByKey分组操作
cogroupgroupByKey连接操作
joinleftOuterJoinrightOuterJoin排序操作
sortBysortByKeyAction
countByKeytakecollect - 既然对键值对的支持是通过
- RDD 对数字型数据的额外支持:
对于数字型数据的额外支持基本上都是 Action 操作, 而不是转换操作:
-
算子 含义 count个数
mean均值
sum求和
max最大值
min最小值
variance方差
sampleVariance从采样中计算方差
stdev标准差
sampleStdev采样的标准差
详见代码。
三、RDD 的 Shuffle 和分区:
RDD 的分区操作
Shuffle 的原理
- 分区的作用
-
RDD 使用分区来分布式并行处理数据, 并且要做到尽量少的在不同的 Executor 之间使用网络交换数据, 所以当使用 RDD 读取数据的时候, 会尽量的在物理上靠近数据源, 比如说在读取 Cassandra 或者 HDFS 中数据的时候, 会尽量的保持 RDD 的分区和数据源的分区数, 分区模式等一一对应
- 分区和 Shuffle 的关系
-
分区的主要作用是用来实现并行计算, 本质上和 Shuffle 没什么关系, 但是往往在进行数据处理的时候, 例如`reduceByKey`, `groupByKey`等聚合操作, 需要把 Key 相同的 Value 拉取到一起进行计算, 这个时候因为这些 Key 相同的 Value 可能会坐落于不同的分区, 于是理解分区才能理解 Shuffle 的根本原理
- Spark 中的 Shuffle 操作的特点
-
只有
Key-Value型的 RDD 才会有 Shuffle 操作, 例如RDD[(K, V)], 但是有一个特例, 就是repartition算子可以对任何数据类型 Shuffle早期版本 Spark 的 Shuffle 算法是
Hash base shuffle, 后来改为Sort base shuffle, 更适合大吞吐量的场景
3.1. RDD 的分区操作
- 查看分区数
-
scala> sc.parallelize(1 to 100).count
res0: Long = 100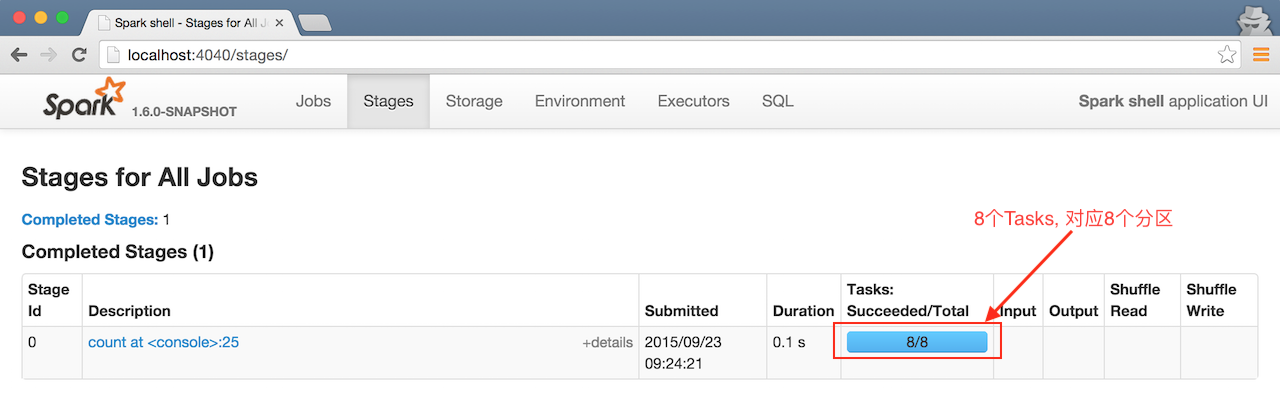
之所以会有 8 个 Tasks, 是因为在启动的时候指定的命令是
spark-shell --master local[8], 这样会生成 1 个 Executors, 这个 Executors 有 8 个 Cores, 所以默认会有 8 个 Tasks, 每个 Cores 对应一个分区, 每个分区对应一个 Tasks, 可以通过rdd.partitions.size来查看分区数量
同时也可以通过 spark-shell 的 WebUI 来查看 Executors 的情况
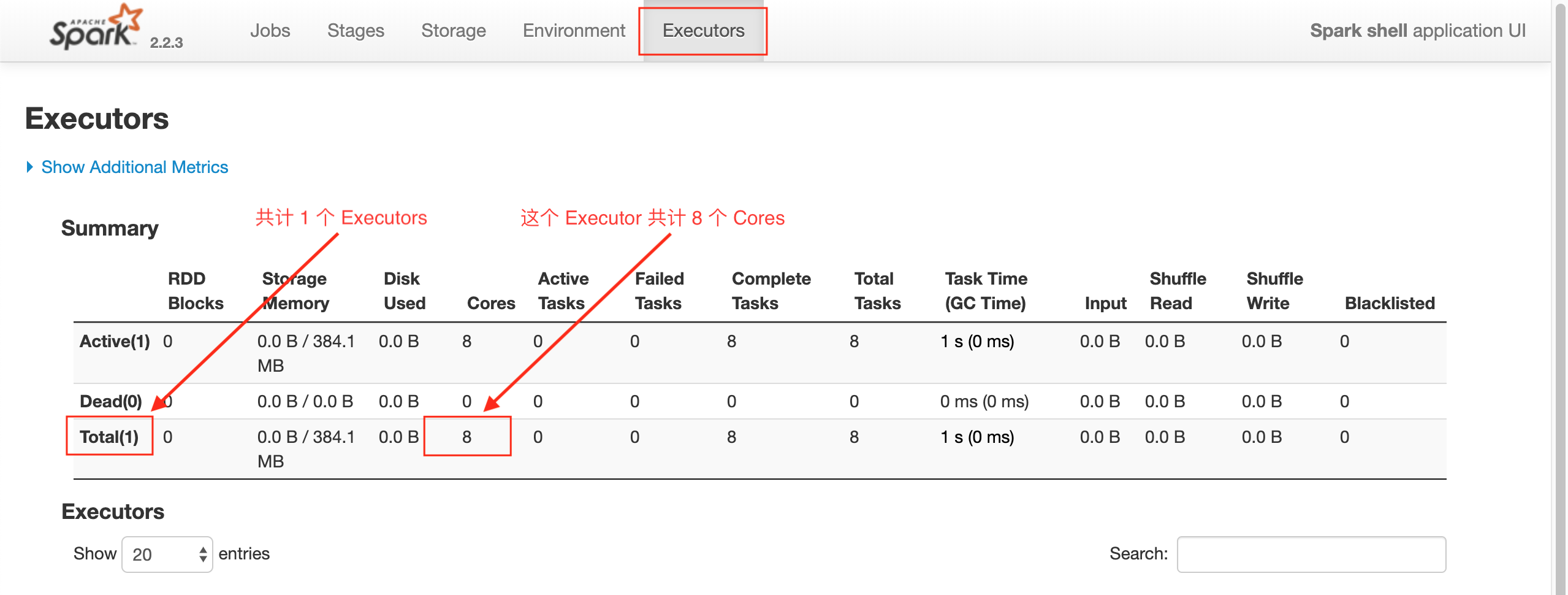
默认的分区数量是和 Cores 的数量有关的, 也可以通过如下三种方式修改或者重新指定分区数量
- 创建 RDD 时指定分区数
-
scala> val rdd1 = sc.parallelize(1 to 100, 6)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24 scala> rdd1.partitions.size
res1: Int = 6 scala> val rdd2 = sc.textFile("hdfs:///dataset/wordcount.txt", 6)
rdd2: org.apache.spark.rdd.RDD[String] = hdfs:///dataset/wordcount.txt MapPartitionsRDD[3] at textFile at <console>:24 scala> rdd2.partitions.size
res2: Int = 7rdd1 是通过本地集合创建的, 创建的时候通过第二个参数指定了分区数量. rdd2 是通过读取 HDFS 中文件创建的, 同样通过第二个参数指定了分区数, 因为是从 HDFS 中读取文件, 所以最终的分区数是由 Hadoop 的 InputFormat 来指定的, 所以比指定的分区数大了一个.
- 通过`coalesce` 算子指定
-
coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null): RDD[T]- numPartitions
-
新生成的 RDD 的分区数
- shuffle
-
是否 Shuffle
scala> val source = sc.parallelize(1 to 100, 6)
source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> source.partitions.size
res0: Int = 6 scala> val noShuffleRdd = source.coalesce(numPartitions=8, shuffle=false)
noShuffleRdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:26 scala> noShuffleRdd.toDebugString
res1: String =
(6) CoalescedRDD[1] at coalesce at <console>:26 []
| ParallelCollectionRDD[0] at parallelize at <console>:24 [] scala> val noShuffleRdd = source.coalesce(numPartitions=8, shuffle=false)
noShuffleRdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:26 scala> shuffleRdd.toDebugString
res3: String =
(8) MapPartitionsRDD[5] at coalesce at <console>:26 []
| CoalescedRDD[4] at coalesce at <console>:26 []
| ShuffledRDD[3] at coalesce at <console>:26 []
+-(6) MapPartitionsRDD[2] at coalesce at <console>:26 []
| ParallelCollectionRDD[0] at parallelize at <console>:24 [] scala> noShuffleRdd.partitions.size
res4: Int = 6 scala> shuffleRdd.partitions.size
res5: Int = 8如果 shuffle参数指定为false, 运行计划中确实没有ShuffledRDD, 没有shuffled这个过程如果 shuffle参数指定为true, 运行计划中有一个ShuffledRDD, 有一个明确的显式的shuffled过程如果 shuffle参数指定为false却增加了分区数, 分区数并不会发生改变, 这是因为增加分区是一个宽依赖, 没有shuffled过程无法做到, 后续会详细解释宽依赖的概念 - 通过
repartition算子指定 -
repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]repartition算子本质上就是coalesce(numPartitions, shuffle = true)
scala> val source = sc.parallelize(1 to 100, 6)
source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:24 scala> source.partitions.size
res7: Int = 6 scala> source.repartition(100).partitions.size
res8: Int = 100 scala> source.repartition(1).partitions.size
res9: Int = 1增加分区有效 减少分区有效 repartition算子无论是增加还是减少分区都是有效的, 因为本质上repartition会通过shuffle操作把数据分发给新的 RDD 的不同的分区, 只有shuffle操作才可能做到增大分区数, 默认情况下, 分区函数是RoundRobin, 如果希望改变分区函数, 也就是数据分布的方式, 可以通过自定义分区函数来实现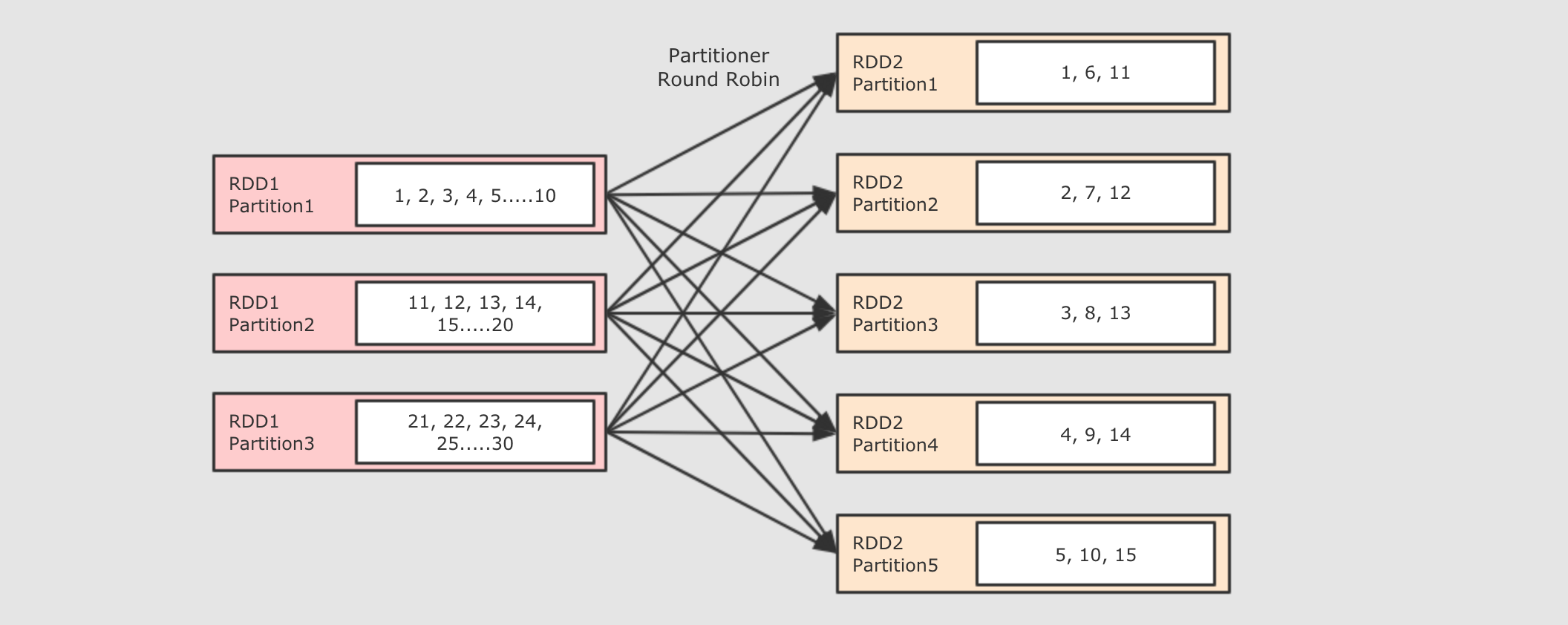
3.2. RDD 的 Shuffle 是什么
val sourceRdd = sc.textFile("hdfs://node01:9020/dataset/wordcount.txt")
val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1))
val aggCountRdd = flattenCountRdd.reduceByKey(_ + _)
val result = aggCountRdd.collect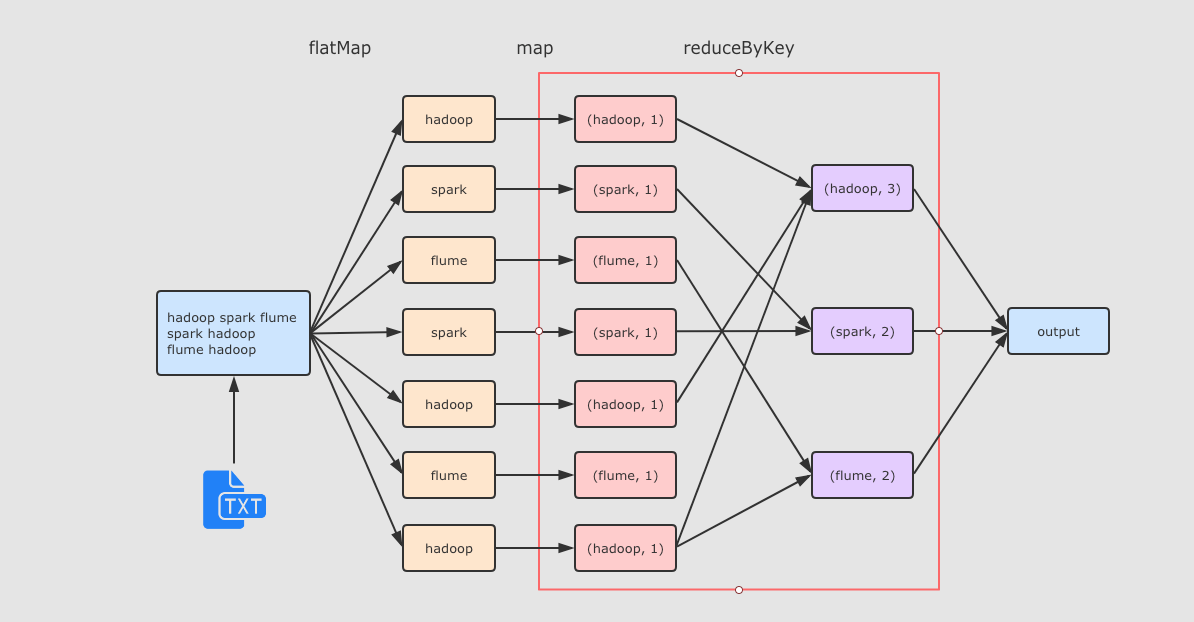
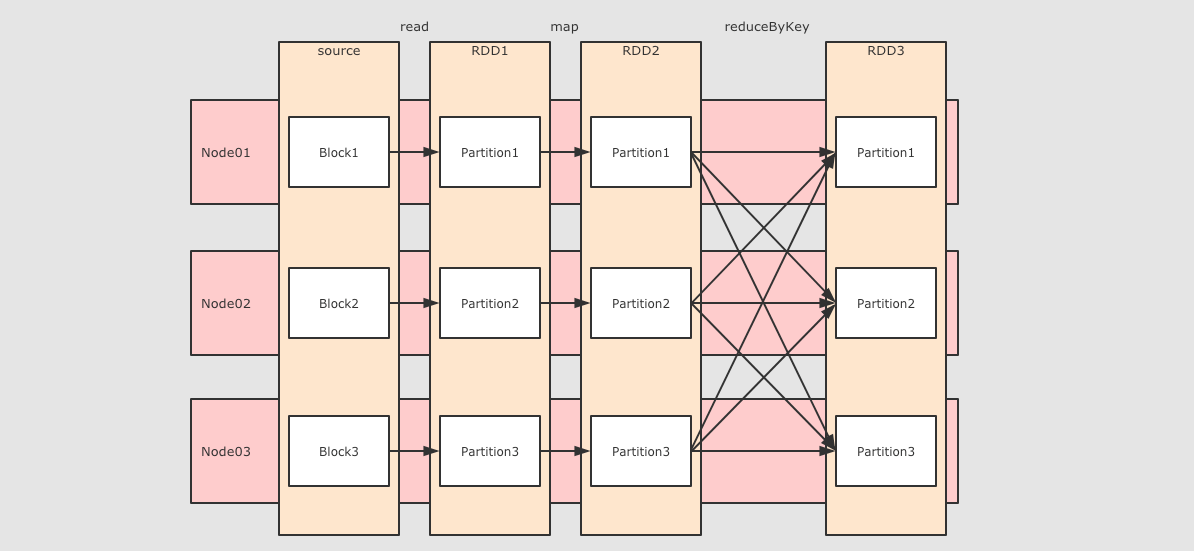
reduceByKey 这个算子本质上就是先按照 Key 分组, 后对每一组数据进行 reduce, 所面临的挑战就是 Key 相同的所有数据可能分布在不同的 Partition 分区中, 甚至可能在不同的节点中, 但是它们必须被共同计算.
为了让来自相同 Key 的所有数据都在 reduceByKey 的同一个 reduce 中处理, 需要执行一个 all-to-all 的操作, 需要在不同的节点(不同的分区)之间拷贝数据, 必须跨分区聚集相同 Key 的所有数据, 这个过程叫做 Shuffle.
3.3. RDD 的 Shuffle 原理
Spark 的 Shuffle 发展大致有两个阶段: Hash base shuffle 和 Sort base shuffle
- Hash base shuffle
-
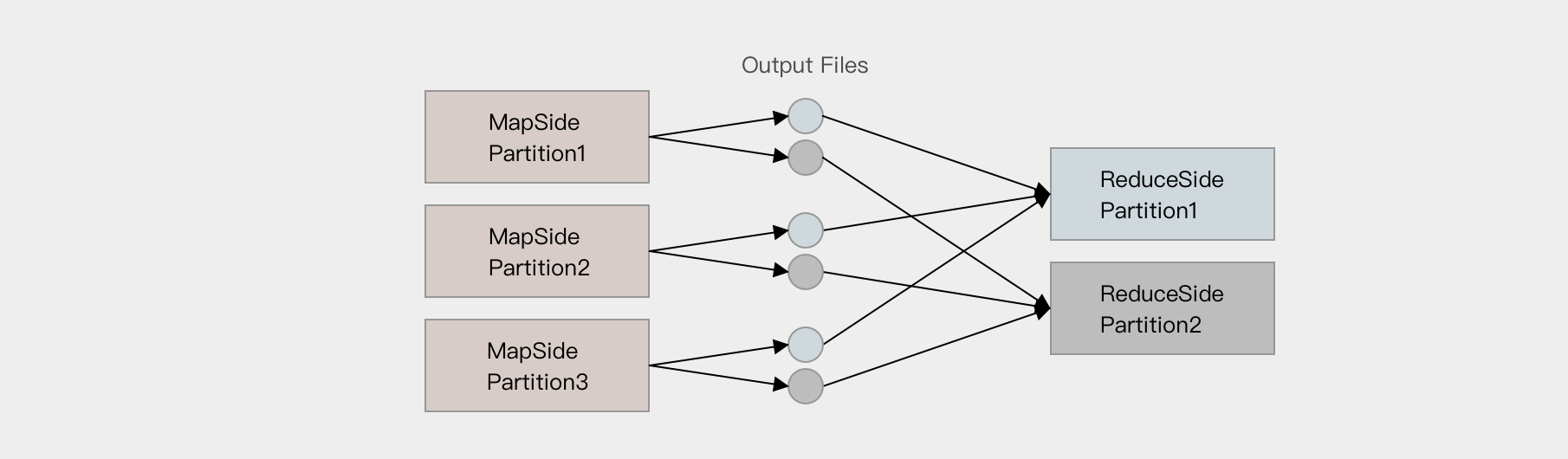
大致的原理是分桶, 假设 Reducer 的个数为 R, 那么每个 Mapper 有 R 个桶, 按照 Key 的 Hash 将数据映射到不同的桶中, Reduce 找到每一个 Mapper 中对应自己的桶拉取数据.
假设 Mapper 的个数为 M, 整个集群的文件数量是
M * R, 如果有 1,000 个 Mapper 和 Reducer, 则会生成 1,000,000 个文件, 这个量非常大了.过多的文件会导致文件系统打开过多的文件描述符, 占用系统资源. 所以这种方式并不适合大规模数据的处理, 只适合中等规模和小规模的数据处理, 在 Spark 1.2 版本中废弃了这种方式.
- Sort base shuffle
-
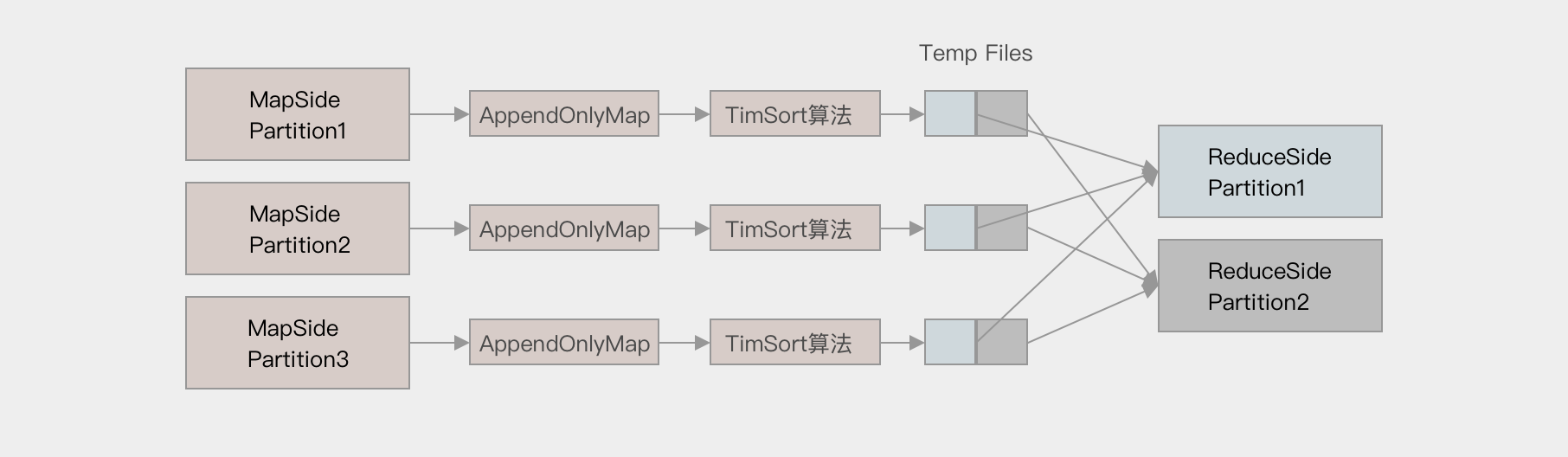
对于 Sort base shuffle 来说, 每个 Map 侧的分区只有一个输出文件, Reduce 侧的 Task 来拉取, 大致流程如下
Map 侧将数据全部放入一个叫做 AppendOnlyMap 的组件中, 同时可以在这个特殊的数据结构中做聚合操作
然后通过一个类似于 MergeSort 的排序算法 TimSort 对 AppendOnlyMap 底层的 Array 排序
先按照 Partition ID 排序, 后按照 Key 的 HashCode 排序
最终每个 Map Task 生成一个 输出文件, Reduce Task 来拉取自己对应的数据
从上面可以得到结论, Sort base shuffle 确实可以大幅度减少所产生的中间文件, 从而能够更好的应对大吞吐量的场景, 在 Spark 1.2 以后, 已经默认采用这种方式.
但是需要大家知道的是, Spark 的 Shuffle 算法并不只是这一种, 即使是在最新版本, 也有三种 Shuffle 算法, 这三种算法对每个 Map 都只产生一个临时文件, 但是产生文件的方式不同, 一种是类似 Hash 的方式, 一种是刚才所说的 Sort, 一种是对 Sort 的一种优化(使用 Unsafe API 直接申请堆外内存)
Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:算子和分区的更多相关文章
- Update(Stage4):spark_rdd算子:第1节 RDD_定义_转换算子:深入RDD
一. 二.案例:详见代码.针对案例提出的6个问题: 假设要针对整个网站的历史数据进行处理, 量有 1T, 如何处理? 放在集群中, 利用集群多台计算机来并行处理 如何放在集群中运行? 简单来讲, 并行 ...
- Update(Stage4):sparksql:第1节 SparkSQL_使用场景_优化器_Dataset & 第2节 SparkSQL读写_hive_mysql_案例
目标 SparkSQL 是什么 SparkSQL 如何使用 Table of Contents 1. SparkSQL 是什么 1.1. SparkSQL 的出现契机 1.2. SparkSQL 的适 ...
- Update(Stage4):Structured Streaming_介绍_案例
1. 回顾和展望 1.1. Spark 编程模型的进化过程 1.2. Spark 的 序列化 的进化过程 1.3. Spark Streaming 和 Structured Streaming 2. ...
- Update(Stage4):Spark原理_运行过程_高级特性
如何判断宽窄依赖: =================================== 6. Spark 底层逻辑 导读 从部署图了解 Spark 部署了什么, 有什么组件运行在集群中 通过对 W ...
- Update(Stage4):Spark Streaming原理_运行过程_高级特性
Spark Streaming 导读 介绍 入门 原理 操作 Table of Contents 1. Spark Streaming 介绍 2. Spark Streaming 入门 2. 原理 3 ...
- Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:缓存、Checkpoint
4. 缓存 概要 缓存的意义 缓存相关的 API 缓存级别以及最佳实践 4.1. 缓存的意义 使用缓存的原因 - 多次使用 RDD 需求: 在日志文件中找到访问次数最少的 IP 和访问次数最多的 IP ...
- Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
8. Dataset (DataFrame) 的基础操作 8.1. 有类型操作 8.2. 无类型转换 8.5. Column 对象 9. 缺失值处理 10. 聚合 11. 连接 8. Dataset ...
- Update(Stage4):sparksql:第5节 SparkSQL_出租车利用率分析案例
目录: 1. 业务2. 流程分析3. 数据读取5. 数据清洗6. 行政区信息 6.1. 需求介绍 6.2. 工具介绍 6.3. 具体实现7. 会话统计 导读 本项目是 SparkSQL 阶段的练习项目 ...
- Update(Stage4):scala补充知识
1.惰性加载: 在企业的大数据开发中,有时候会编写非常复杂的SQL语句,这些SQL语句可能有几百行甚至上千行.这些SQL语句,如果直接加载到JVM中,会有很大的内存开销.如何解决? 当有一些变量保存的 ...
随机推荐
- Systemd 学习
转:http://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-commands.html 原文链接:https://www.jianshu.com ...
- C++ - cpprestsdk
Windows 安装方法: CMake 1.32+,生成过程会将 vcpkg 下载好,配置到系统环境变量,然后用 vcpkg 安装依赖库(github 上有列出需要的依赖库). Github 上的示例 ...
- Modelsim, Debussy联合仿真Xilinx
http://wenku.baidu.com/view/8363d40003d8ce2f006623e9.html 另外一个博客 生成Xilinx库 先调用ISE的simulation librar ...
- 【转载】Java集合容器全面分析
转自:http://blog.csdn.net/garfielder007/article/details/52143803 简介: 集合类Collection不是Java的核心类,是Java的扩展类 ...
- Linux05——用户操作
用户操作 1.新增用户(useradd 新用户名): 2.设置密码(passwd 用户名): 3.用户是否存在(id 用户名): 4.切换用户(su - 切换用户名) **—— ** s ...
- [linux] 手机Deploy linux 桌面中文乱码
在手机上安装Deploy之后 通过VNC连接桌面,中文出现乱码 是方块乱码 这个是字体缺失造成的 安装字体就好了 我安装的是kali 桌面是LXDE sudo apt-get install font ...
- eclipse提示错误:save could not be completed
原博客地址:https://blog.csdn.net/alane1986/article/details/6514000 2010年12月06日 19:20:00 alane1986 阅读数:150 ...
- CSS学习(1)简介
什么是 CSS? CSS 指层叠样式表 (Cascading Style Sheets) 样式定义如何显示 HTML 元素 样式通常存储在样式表中 把样式添加到 HTML 4.0 中,是为了解决内容与 ...
- git和github的关系以及简单易懂的理解
git和github的关系 写在前面:我身边好多人问我git和github的区别,想必对于好多人没学过的大佬们恐怕也是一脸懵逼,但是不知道也是不行的,所以我今天就来讲一讲这二者的区别和联系. 用一 ...
- 修改链接服务器 Rpc &Rpc Out
USE [master] GO EXEC master.dbo.sp_serveroption @server=N'LinkName', @optname=N'rpc', @optvalue=N'tr ...