MapReduce清洗数据进行可视化
继上篇第一阶段清洗数据并导入hive
本篇是剩下的两阶段
2、数据处理:
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
2、
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
package mapreduce; import java.io.IOException; import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class GetVideoResult { public static void main(String[] args) {
try {
Job job = Job.getInstance();
job.setJobName("GetVideoResult");
job.setJarByClass(GetVideoResult.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out1/part-r-00000");
Path out = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out1.2");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
//System.exit(job.waitForCompletion(true) ? 0:1);
if(job.waitForCompletion(true))
{
Job job1 = Job.getInstance();
job1.setJobName("Sort");
job1.setJarByClass(GetVideoResult.class);
job1.setMapperClass(doMapper1.class);
job1.setReducerClass(doReducer1.class);
job1.setOutputKeyClass(IntWritable.class);
job1.setOutputValueClass(Text.class);
job1.setSortComparatorClass(IntWritableDecreasingComparator.class);
job1.setInputFormatClass(TextInputFormat.class);
job1.setOutputFormatClass(TextOutputFormat.class);
Path in1 = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out1.2/part-r-00000");
Path out1 = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out1.3");
FileInputFormat.addInputPath(job1,in1);
FileOutputFormat.setOutputPath(job1,out1);
System.exit(job1.waitForCompletion(true) ? 0:1);
} } catch (Exception e) {
e.printStackTrace();
}
} public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{
public static Text word = new Text();
public static final IntWritable id = new IntWritable(1);
@Override
protected void map(Object key,Text value,Context context) throws IOException,InterruptedException{
String[] data = value.toString().split("\t");
word.set(data[5]);
//id.set(Integer.parseInt(data[5])); context.write(word,id); }
} public static class doReducer extends Reducer< Text, IntWritable, IntWritable, Text>{
private static IntWritable result= new IntWritable(); public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
int sum = 0;
for(IntWritable value:values){
sum += value.get();
} result.set(sum);
context.write(result,key);
}
} public static class doMapper1 extends Mapper<Object , Text , IntWritable,Text >{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
String arr[]=line.split("\t");
num.set(Integer.parseInt(arr[0]));
goods.set(arr[1]);
context.write(num,goods);
}
} public static class doReducer1 extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
int i=0; public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text value:values){
if(i<10) {
context.write(key,value);
i++;
}
} }
} private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
} }
自己一开始使用两个类完成的,先求和在排序,在网上查阅资料后发现可以有两个job,然后就在一个类中完成,然后MapReduce本来的排序是升序,而我们需要的是降序,所以在此引入了一个比较器。
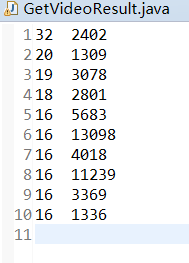
按照地市统计最受欢迎的Top10课程 (ip)
package mapreduce; import java.io.IOException; import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class GetVideoResultip { public static void main(String[] args) {
try {
Job job = Job.getInstance();
job.setJobName("GetVideoResult");
job.setJarByClass(GetVideoResultip.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in = new Path("hdfs://192.168.137.67:9000/mymapreducel/in/result.txt");
Path out = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out2.1");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
//System.exit(job.waitForCompletion(true) ? 0:1);
if(job.waitForCompletion(true))
{
Job job1 = Job.getInstance();
job1.setJobName("Sort");
job1.setJarByClass(GetVideoResult.class);
job1.setMapperClass(doMapper1.class);
job1.setReducerClass(doReducer1.class);
job1.setOutputKeyClass(IntWritable.class);
job1.setOutputValueClass(Text.class);
job1.setSortComparatorClass(IntWritableDecreasingComparator.class);
job1.setInputFormatClass(TextInputFormat.class);
job1.setOutputFormatClass(TextOutputFormat.class);
Path in1 = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out2.1/part-r-00000");
Path out1 = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out2.2");
FileInputFormat.addInputPath(job1,in1);
FileOutputFormat.setOutputPath(job1,out1);
System.exit(job1.waitForCompletion(true) ? 0:1);
} } catch (Exception e) {
e.printStackTrace();
}
} public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{
public static Text word = new Text();
public static final IntWritable id = new IntWritable(1);
@Override
protected void map(Object key,Text value,Context context) throws IOException,InterruptedException{
String[] data = value.toString().split(",");
String str=data[0]+"\t"+data[5];
System.out.println(str);
word.set(str);
//id.set(Integer.parseInt(data[5])); context.write(word,id);
}
} public static class doReducer extends Reducer< Text, IntWritable, IntWritable, Text>{
private static IntWritable result= new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
int sum = 0;
for(IntWritable value:values){
sum += value.get();
} result.set(sum);
context.write(result,key);
}
} public static class doMapper1 extends Mapper<Object , Text , IntWritable,Text >{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
String arr[]=line.split("\t");
String str=arr[1]+"\t"+arr[2];
num.set(Integer.parseInt(arr[0]));
goods.set(str);
context.write(num,goods);
}
} public static class doReducer1 extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
int i=0; public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text value:values){
if(i<10) {
context.write(key,value);
i++;
}
} }
} private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
} }

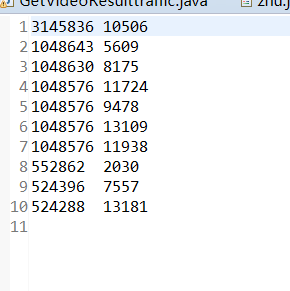
·按照流量统计最受欢迎的Top10课程 (traffic)
package mapreduce; import java.io.IOException; import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class GetVideoResulttraffic { public static void main(String[] args) {
try {
Job job = Job.getInstance();
job.setJobName("GetVideoResult");
job.setJarByClass(GetVideoResultip.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in = new Path("hdfs://192.168.137.67:9000/mymapreducel/in/result.txt");
Path out = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out3.1");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
//System.exit(job.waitForCompletion(true) ? 0:1);
if(job.waitForCompletion(true))
{
Job job1 = Job.getInstance();
job1.setJobName("Sort");
job1.setJarByClass(GetVideoResult.class);
job1.setMapperClass(doMapper1.class);
job1.setReducerClass(doReducer1.class);
job1.setOutputKeyClass(IntWritable.class);
job1.setOutputValueClass(Text.class);
job1.setSortComparatorClass(IntWritableDecreasingComparator.class);
job1.setInputFormatClass(TextInputFormat.class);
job1.setOutputFormatClass(TextOutputFormat.class);
Path in1 = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out3.1/part-r-00000");
Path out1 = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out3.2");
FileInputFormat.addInputPath(job1,in1);
FileOutputFormat.setOutputPath(job1,out1);
System.exit(job1.waitForCompletion(true) ? 0:1);
} } catch (Exception e) {
e.printStackTrace();
}
} public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{
public static Text word = new Text();
public static final IntWritable id = new IntWritable();
@Override
protected void map(Object key,Text value,Context context) throws IOException,InterruptedException{
String[] data = value.toString().split(",");
//String str=data[0]+"\t"+data[5];
data[3] = data[3].substring(0, data[3].length()-1);
word.set(data[5]);
id.set(Integer.parseInt(data[3])); context.write(word,id);
}
} public static class doReducer extends Reducer< Text, IntWritable, IntWritable, Text>{
private static IntWritable result= new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
int sum = 0;
for(IntWritable value:values){
sum += value.get();
} result.set(sum);
context.write(result,key);
}
} public static class doMapper1 extends Mapper<Object , Text , IntWritable,Text >{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
String arr[]=line.split("\t");
num.set(Integer.parseInt(arr[0]));
goods.set(arr[1]);
context.write(num,goods);
}
} public static class doReducer1 extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
int i=0; public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text value:values){
if(i<10) {
context.write(key,value);
i++;
}
} }
} private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
} }
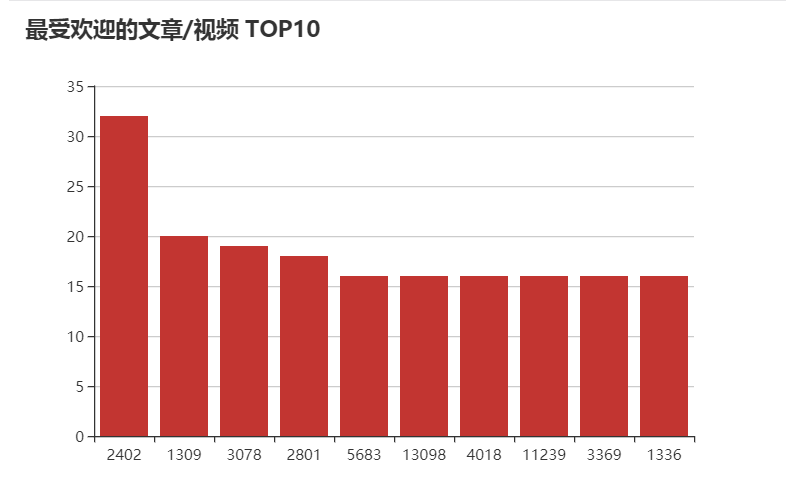
3、数据没有导入到mysql中,但是通过MapReduce进行了echarts可视化
先通过MapReduce进行清洗数据,然后在jsp中进行可视化
package mapreduce3; import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Pai { public static List<String> Names=new ArrayList<String>();
public static List<String> Values=new ArrayList<String>(); public static class Sort extends WritableComparator
{
public Sort()
{
super(IntWritable.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b)
{
return -a.compareTo(b);
}
}
public static class Map extends Mapper<Object , Text , IntWritable,Text >{
private static Text Name=new Text();
private static IntWritable num=new IntWritable();
public void map(Object key,Text value,Context context)throws IOException, InterruptedException
{
String line=value.toString();
String arr[]=line.split("\t");
if(!arr[0].startsWith(" "))
{
num.set(Integer.parseInt(arr[0]));
Name.set(arr[1]);
context.write(num, Name);
} }
}
public static class Reduce extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
int i=0; public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text val:values)
{
if(i<10)
{i=i+1;
Names.add(val.toString());
Values.add(key.toString());
}
context.write(key,val);
}
}
} public static int run()throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.137.67:9000");
FileSystem fs =FileSystem.get(conf);
Job job =new Job(conf,"OneSort");
job.setJarByClass(Pai.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setSortComparatorClass(Sort.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out1.2/part-r-00000");
Path out = new Path("hdfs://192.168.137.67:9000/mymapreducelShiYan/out1.4");
FileInputFormat.addInputPath(job,in);
fs.delete(out,true);
FileOutputFormat.setOutputPath(job,out);
return(job.waitForCompletion(true) ? 0 : 1); } }
zhu.jsp
<%@page import="mapreduce3.Pai"%>
<%@page import="mapreduce3.GetVideoResult"%>
<%@ page language="java" import="java.util.*" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
<script src="${pageContext.request.contextPath}/resource/echarts.js"></script>
</head>
<body>
<% Pai ss= new Pai();
ss.run();
String[] a=new String[11];
String[] b=new String[11];
int i=0,j=0; for(i = 0 ; i < 10 ; i++)
{
a[i] = ss.Values.get(i);
b[i] = ss.Names.get(i);
}
%>
<div id="main" style="width: 600px;height:400px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据
var option = {
title: {
text: '最受欢迎的文章/视频 TOP10'
},
tooltip: {},
legend: {
data:['统计']
},
xAxis: {
data: [ <%
for( i=0;i<10;i++)
{
%><%=b[i]%>,<% }
%>]
},
yAxis: {},
series: [{
name: '最受欢迎的文章',
type: 'bar',
data: [
<%
for( i=0;i<10;i++)
{
%><%=a[i]%>,<% }
%> ]
}]
}; // 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
因为其他的数据清洗上边有,代码就不一一展示,只贴出jsp文件,如果想要改变可视化团,在echarts官网中直接复制代码到jsp中进行修改即可。
zhe.jsp
<%@page import="mapreduce3.Pai1"%>
<%@page import="mapreduce3.GetVideoResult"%>
<%@ page language="java" import="java.util.*" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
<script src="${pageContext.request.contextPath}/resource/echarts.js"></script>
</head>
<body>
<% Pai1 ss= new Pai1();
ss.run();
String[] a=new String[11];
String[] b=new String[11];
int i=0,j=0; for(i = 0 ; i < 10 ; i++)
{
a[i] = ss.Values.get(i);
b[i] = ss.Names.get(i);
}
%>
<div id="main" style="width: 600px;height:400px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据
var option = {
title: {
text: '按照地市最受欢迎'
},
tooltip: {},
legend: {
data:['统计']
},
xAxis: {
data: [
<%
for( i=0;i<10;i++)
{
%>'<%=b[i]%>',
<%
}
%>
]
},
yAxis: {},
series: [{
name: '最受欢迎的文章',
type: 'line',
data: [
<%
for( i=0;i<10;i++)
{
%><%=a[i]%>,<% }
%> ]
}]
}; // 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>

tu.jsp
<%@page import="mapreduce3.Pai2"%>
<%@page import="mapreduce3.GetVideoResult"%>
<%@ page language="java" import="java.util.*" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
<script src="${pageContext.request.contextPath}/resource/echarts.js"></script>
</head>
<body>
<% Pai2 ss= new Pai2();
ss.run();
String[] a=new String[11];
String[] b=new String[11];
int i=0,j=0; for(i = 0 ; i < 10 ; i++)
{
a[i] = ss.Values.get(i);
b[i] = ss.Names.get(i);
}
%>
<div id="main" style="width: 600px;height:400px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据
option = {
title : {
text: '按照流量最受欢迎',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
legend: {
orient: 'vertical',
left: 'left',
data: [
<%
for( i=0;i<10;i++)
{
%>'<%=b[i]%>', <%
}
%>
]
},
series : [
{
name: '访问来源',
type: 'pie',
radius : '55%',
center: ['50%', '60%'],
data:[ <%
for( i=0;i<10;i++)
{
%>{value:<%=a[i]%>,name:'<%=b[i]%>'}, <%
}
%>
],
itemStyle: {
emphasis: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
}; // 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>

MapReduce清洗数据进行可视化的更多相关文章
- mapreduce清洗数据
继上篇 MapReduce清洗数据 package mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Confi ...
- 视频网站数据MapReduce清洗及Hive数据分析
一.需求描述 利用MapReduce清洗视频网站的原数据,用Hive统计出各种TopN常规指标: 视频观看数 Top10 视频类别热度 Top10 视频观看数 Top20 所属类别包含这 Top20 ...
- MapReduce处理数据1
学了一段时间的hadoop了,一直没有什么正经练手的机会,今天老师给了一个课堂测试来进行练手,正好试一下. 项目已上传至github:https://github.com/yandashan/MapR ...
- discuz论坛apache日志hadoop大数据分析项目:清洗数据核心功能解说及代码实现
discuz论坛apache日志hadoop大数据分析项目:清洗数据核心功能解说及代码实现http://www.aboutyun.com/thread-8637-1-1.html(出处: about云 ...
- 做Data Mining,其实大部分时间都花在清洗数据
做Data Mining,其实大部分时间都花在清洗数据 时间 2016-12-12 18:45:50 51CTO 原文 http://bigdata.51cto.com/art/201612/52 ...
- 11,SFDC 管理员篇 - 报表和数据的可视化
1,Report Builder 1,每一个report type 都有一个 primay object 和多个相关的object 2,Primary object with related obje ...
- MetricGraphics.js – 时间序列数据的可视化
MetricsGraphics.js 是建立在D3的基础上,被用于可视化和布局的时间序列数据进行了优化.它提供以产生一个原则性的,一致的和响应式的方式的图形常见类型的简单方法.该库目前支持折线图,散点 ...
- 利用 t-SNE 高维数据的可视化
利用 t-SNE 高维数据的可视化 具体软件和教程见: http://lvdmaaten.github.io/tsne/ 简要介绍下用法: % Load data load ’mnist_trai ...
- MapReduce的数据流程、执行流程
MapReduce的数据流程: 预先加载本地的输入文件 经过MAP处理产生中间结果 经过shuffle程序将相同key的中间结果分发到同一节点上处理 Recude处理产生结果输出 将结果输出保存在hd ...
随机推荐
- 深度学习论文翻译解析(七):Support Vector Method for Novelty Detection
论文标题:Support Vector Method for Novelty Detection 论文作者:Bernhard Scholkopf, Robert Williamson, Alex Sm ...
- python修改列表
替换元素 效果图: 代码: #创建一个列表 list = ['a','b','c','d','e','f'] print('修改前:',list) #修改元素 指定索引重设其值 list[1] = ' ...
- Babel+vscode实现APICloud开发中兼容ES6及以上代码
本文出自APICloud官方论坛, 感谢论坛版主 penghuoyan 的分享. 使用APICloud开发时,考虑到兼容问题一直使用ES5开发,时间越久感觉越落后,整理了一个兼容ES6的开发环境, ...
- Unity3d游戏角色描边
本文发布于游戏程序员刘宇的个人博客,欢迎转载,请注明来源https://www.cnblogs.com/xiaohutu/p/10834491.html 游戏里经常需要在角色上做描边,这里总结一下平时 ...
- [bzoj4569] [loj#2014] [Scoi2016] 萌萌哒
Description 一个长度为 \(n\) 的大数,用 \(S1S2S3...Sn\) 表示,其中 \(Si\) 表示数的第 \(i\) 位, \(S1\) 是数的最高位,告诉你一些限制条件,每个 ...
- 程序员你为什么这么累【三】:编码习惯之Controller规范
作者:晓风轻本文转载自:https://zhuanlan.zhihu.com/p/28717374 第一篇文章中,我贴了2段代码,第一个是原生态的,第2段是我指定了接口定义规范,使用AOP技术之后最终 ...
- windows下RocketMQ安装部署
一.预备环境 1.系统 Windows 2. 环境 JDK1.8.Maven.Git 二. RocketMQ部署 1.下载 1.1地址:http://rocketmq.apache.org/relea ...
- 最新Pyecharts-基本图表
Pyecharts是由Echarts而来,Echarts是百度开源的数据可视化的库,适合用来做图表设计开发,当使用Python与Echarts结合时就产生了Pyecharts.可使用pip安装,默认是 ...
- PTA 6-15 用单向循环链表实现猴子选大王 (20 分)
一群猴子要选新猴王.新猴王的选择方法是:让n只候选猴子围成一圈,从某位置起顺序编号为1~n号.每只猴子预先设定一个数(或称定数),用最后一只猴子的定数d,从第一只猴子开始报数,报到d的猴子即退出圈子: ...
- PMP——项目管理的价值观与方法论
关于项目管理的十个成语: 未雨绸缪(计划.风险):识别风险.做出计划.并指定负责人: 防微杜渐(监控.纠正):持续的实时的监控计划,监控和发现偏差,并进行纠正: 资源集成(整合.采购):把最专业的资源 ...