Lucene之查询索引
Query子类
TermQuery:根据域和关键词进行搜索
/**
* termQuery根据域和关键词进行搜索
*/
@Test
public void termQuery() throws IOException {
//1.创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\\Luene资料\\Index").toPath());
//2.创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//3.创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//4.创建Query查询对象
Query query=new TermQuery(new Term("fieldContent","spring"));
//5.执行查询,获取到文档对象
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("共获取:"+topDocs.totalHits+"个文档~~~~~~~~~~~~~~~~~~~~~");
//6.获取文档列表
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc item:scoreDocs) {
//获取文档ID
int docId=item.doc;
//取出文档
Document doc = indexSearcher.doc(docId);
//获取到文档域中数据
System.out.println("fieldName:"+doc.get("fieldName"));
System.out.println("fieldPath:"+doc.get("fieldPath"));
System.out.println("fieldSize:"+doc.get("fieldSize"));
System.out.println("fieldContent:"+doc.get("fieldContent"));
System.out.println("==============================================================");
}
//7.关闭资源
indexReader.close();
}
结果
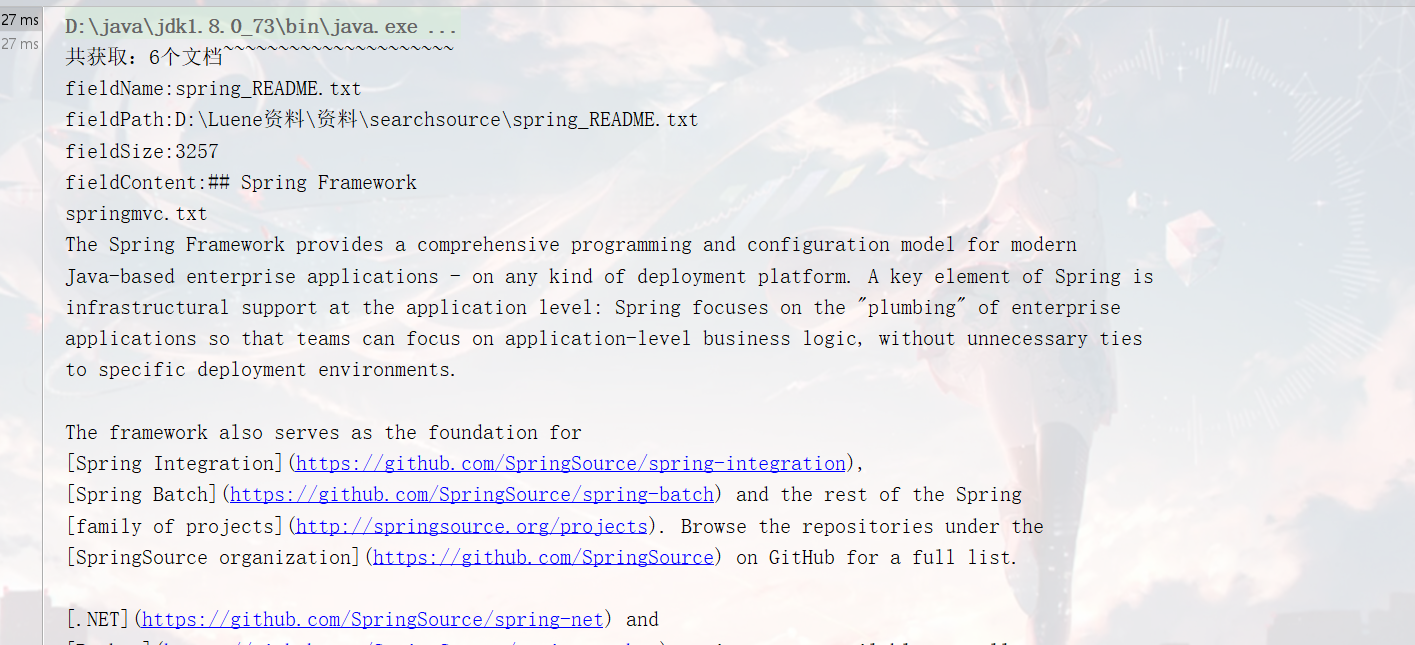
RangeQuery:范围搜索
/**
* RangeQuery范围搜素
*/
@Test
public void RangeQuery() throws IOException {
//创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\\Luene资料\\Index").toPath());
//创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//设置范围搜索的条件 参数一范围所在的域
Query query= LongPoint.newRangeQuery("fieldSize",0,50);
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
} //关闭
indexReader.close();
}
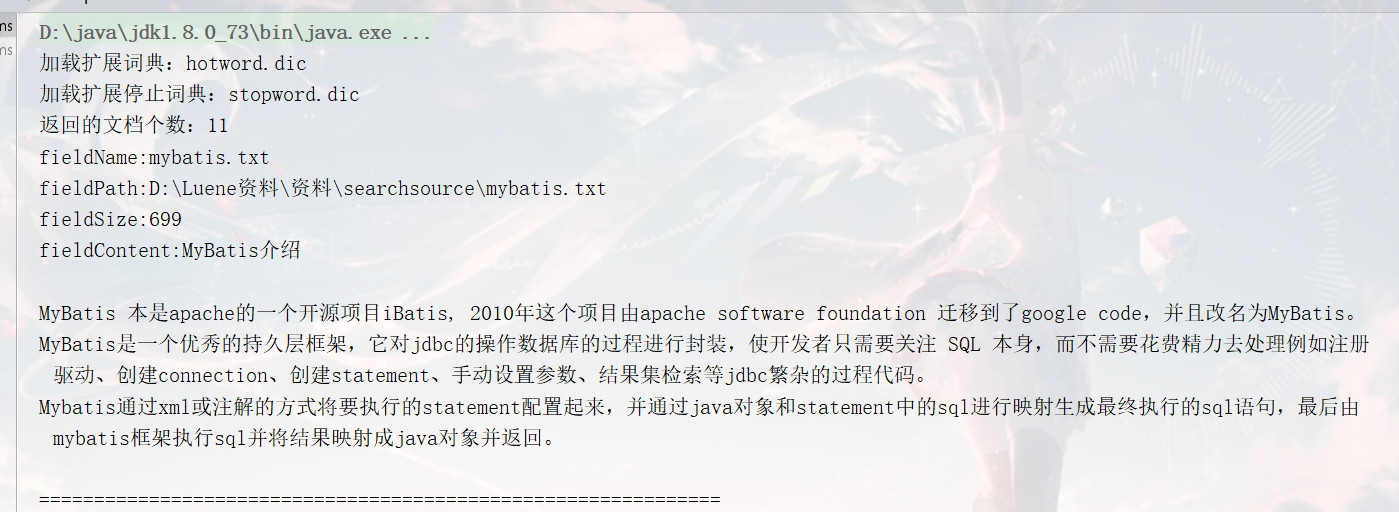
结果

QueryParser:匹配一行数据,这一行数据会自动进行分词
/**
* queryparser搜素,会将搜索条件分词
*/
@Test
public void queryparser() throws IOException, ParseException {
//创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\\Luene资料\\Index").toPath());
//创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建一个QueryParser对象 参数一:查询的域 参数二:使用哪种分析器
QueryParser parser=new QueryParser("fieldContent",new IKAnalyzer());
//设置匹配的数据条件
Query query = parser.parse("Lucene是一个开源的基于Java的搜索库");
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
}
//关闭
indexReader.close();
}
结果
Lucene之查询索引的更多相关文章
- 全文检索Lucene框架---查询索引
一. Lucene索引库查询 对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name ...
- lucene入门查询索引——(三)
1.用户接口(lucene不提供)
- 搜索引擎学习(三)Lucene查询索引
一.查询理论 创建查询:构建一个包含了文档域和语汇单元的文档查询对象.(例:fileName:lucene) 查询过程:根据查询对象的条件,在索引中找出相应的term,然后根据term找到对应的文档i ...
- Lucene查询索引(分页)
分页查询只需传入每页显示记录数和当前页就可以实现分页查询功能 Lucene分页查询是对搜索返回的结果进行分页,而不是对搜索结果的总数量进行分页,因此我们搜索的时候都是返回前n条记录 package c ...
- Lucene查询索引
索引创建 以新闻文档为例,每条新闻是一个document,新闻有news_id.news_title.news_source.news_url.news_abstract.news_keywords这 ...
- lucene查询索引库、分页、过滤、排序、高亮
2.查询索引库 插入测试数据 xx.xx. index. ArticleIndex @Test public void testCreateIndexBatch() throws Exception{ ...
- 学习笔记CB011:lucene搜索引擎库、IKAnalyzer中文切词工具、检索服务、查询索引、导流、word2vec
影视剧字幕聊天语料库特点,把影视剧说话内容一句一句以回车换行罗列三千多万条中国话,相邻第二句很可能是第一句最好回答.一个问句有很多种回答,可以根据相关程度以及历史聊天记录所有回答排序,找到最优,是一个 ...
- lucene查询索引之QueryParser解析查询——(八)
0.语法介绍:
- lucene查询索引之Query子类查询——(七)
0.文档名字:(根据名字索引查询文档)
随机推荐
- Django设置session过期时间
settings.py #session 设置 SESSION_COOKIE_AGE = 60 * 10 # 设置过期时间10分钟,默认为两周 SESSION_SAVE_EVERY_REQUEST = ...
- devops与CICD
前言 devops的概念已经在前一章已经说过了,下面介绍CICD的概念. CI(Continuous Integration,持续集成) 持续集成中,开发人员将会频繁地向主干提交代码,这些新提交的代码 ...
- Informatica在linux下安装搭建
安装介质清单准备 介质名称 版本信息 描述 Informatica Powercenter 9.5.1 for Linux 64 bit 必须 Java Jdk 1.6.0_45 for Linux ...
- 关于远程办公,微软MVP 15年研发团队的经验分享
今天是2月5日,春节假期结束后的第三天了.为了能够应对来势汹汹的疫情,众多互联网企业纷纷开启了远程办公模式.不知道各团队前两天的远程办公效果如何,我们 Worktile 管理层在大年初四就开始讨论远程 ...
- Vue中的计算属性
一.什么是计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的.在模板中放入太多的逻辑会让模板过重且难以维护. 二.计算属性的用法 在一个计算属性里可以完成各种复杂的逻辑,包括运算.函 ...
- Springboot | Failed to execute goal org.springframework.boot:spring-boot-maven-plugin
案例 今天搭建spring boot 环境时,使用mvn install ,出现Failed to execute goal org.springframework.boot:spring-boot- ...
- 手把手实操教程!使用k3s运行轻量级VM
前 言 k3s作为轻量级的Kubernetes发行版,运行容器是基本功能.VM的管理原本是IaaS平台的基本能力,随着Kubernetes的不断发展,VM也可以纳入其管理体系.结合Container和 ...
- ubuntu 如何添加alias
公司的nx 上面一般使用gvim 编辑文件.并且为gvim 增加了alias,只要敲 g 就是gvim 的意思,这样编辑一个文件只需要 g xxx.v 就可以了.非常方便. 在自己电脑上安装了ubun ...
- go net包简记
TCP服务端 go语言中可以每次建立一次链接就创建一个goroutine去处理,使用goroutine实现并发非常方便和高效. TCP服务端程序的一般处理流程1.建立并绑定 Socket:首先服务端使 ...
- 如何高效地远程部署?自动化运维利器 Fabric 教程
关于 Python 自动化的话题,在上一篇文章中,我介绍了 Invoke 库,它是 Fabric 的最重要组件之一.Fabric 也是一个被广泛应用的自动化工具库,是不得不提的自动化运维利器,所以,本 ...