全文检索Lucene框架---查询索引
一、 Lucene索引库查询
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
可通过两种方法创建查询对象:
1)使用Lucene提供Query子类
2)使用QueryParse解析查询表达式
二、 TermQuery
TermQuery,通过项查询,TermQuery不使用分析器所以建议匹配不分词的Field域查询,比如订单号、分类ID号等。
指定要查询的域和要查询的关键词。
1、代码实现
package com.zn; import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.jupiter.api.Test; import java.io.File;
import java.io.IOException; /**
* 查询索引
*/
public class QueryTest { /**
* 根据域或关键词进行搜索
*/
@Test
public void termQuery() throws IOException {
Directory directory= FSDirectory.open(new File("E:\\accp\\Y2\\进阶内容\\Lucene\\Lucene\\Index").toPath());
IndexReader indexReader= DirectoryReader.open(directory);
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建查询条件
Query query=new TermQuery(new Term("fieldName","spring"));
//执行查询
TopDocs topDocs=indexSearcher.search(query,10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
}
//关闭
indexReader.close();
}
}
2、查询效果
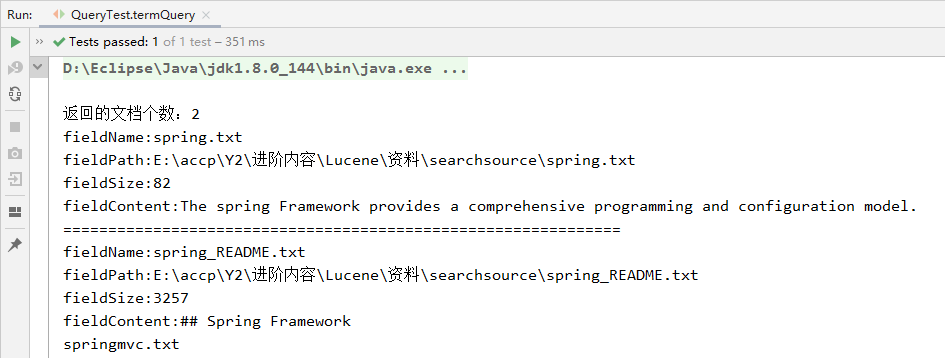
三、 RangeQuery数值查询
1、代码实现
package com.zn; import org.apache.lucene.document.Document;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.jupiter.api.Test; import java.io.File;
import java.io.IOException; /**
* 查询索引
*/
public class QueryTest { /**
* RangeQuery:范围搜索
*/
@Test
public void rangeQuery() throws IOException {
Directory directory= FSDirectory.open(new File("E:\\accp\\Y2\\进阶内容\\Lucene\\Lucene\\Index").toPath());
IndexReader indexReader= DirectoryReader.open(directory);
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建查询条件
//设置范围搜索的条件 参数一范围所在的域
Query query= LongPoint.newRangeQuery("fieldSize",0,50);
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
} //关闭
indexReader.close();
} }
2、查询效果
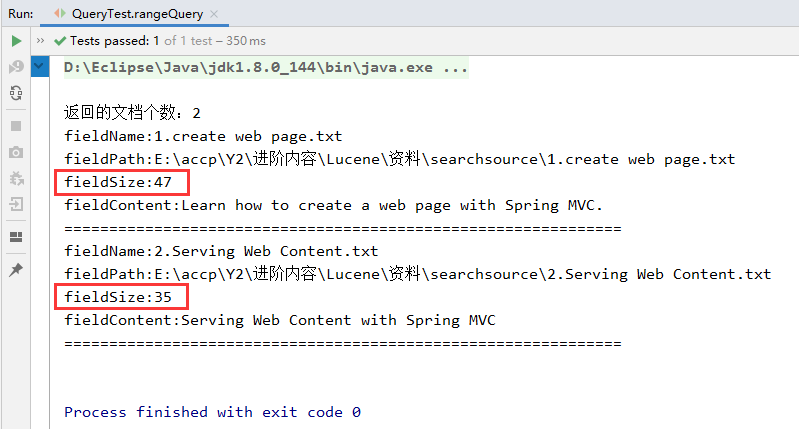
四、 QueryParser
通过QueryParser也可以创建Query,QueryParser提供一个Parse方法,此方法可以直接根据查询语法来查询。Query对象执行的查询语法可通过System.out.println(query);查询。
需要使用到分析器。建议创建索引时使用的分析器和查询索引时使用的分析器要一致。
需要加入queryParser依赖的jar包。
1、导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.4.0</version>
</dependency>
2、代码实现
package com.zn; import org.apache.lucene.document.Document;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.jupiter.api.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.File;
import java.io.IOException; /**
* 查询索引
*/
public class QueryTest { /**
* QueryParser:将搜索条件分词
*/
@Test
public void queryParser() throws IOException, ParseException {
Directory directory= FSDirectory.open(new File("E:\\accp\\Y2\\进阶内容\\Lucene\\Lucene\\Index").toPath());
IndexReader indexReader= DirectoryReader.open(directory);
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建QueryParser对象 参数一范围所在的域 参数二:使用哪种分析器
QueryParser parser=new QueryParser("fieldContent",new IKAnalyzer());
//设置匹配的数据条件
Query query = parser.parse("新添加的文档的内容");
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
} //关闭
indexReader.close();
} }
3、效果展示

全文检索Lucene框架---查询索引的更多相关文章
- Lucene之查询索引
Query子类 TermQuery:根据域和关键词进行搜索 /** * termQuery根据域和关键词进行搜索 */ @Test public void termQuery() throws IOE ...
- lucene入门查询索引——(三)
1.用户接口(lucene不提供)
- 搜索引擎学习(三)Lucene查询索引
一.查询理论 创建查询:构建一个包含了文档域和语汇单元的文档查询对象.(例:fileName:lucene) 查询过程:根据查询对象的条件,在索引中找出相应的term,然后根据term找到对应的文档i ...
- lucene查询索引库、分页、过滤、排序、高亮
2.查询索引库 插入测试数据 xx.xx. index. ArticleIndex @Test public void testCreateIndexBatch() throws Exception{ ...
- lucene&solr学习——创建和查询索引(代码篇)
1. Lucene的下载 Lucene是开发全文检索功能的工具包,从官网下载Lucene4.10.3并解压. 官网:http://lucene.apache.org/ 版本:lucene7.7.0 ( ...
- lucene&solr学习——创建和查询索引(理论)
1.Lucene基础 (1) 简介 Lucene是apache下的一个开放源代码的全文检索引擎工具包.提供完整的查询引擎和索引引擎:部分文本分析引擎. Lucene的目的是为软件开发人员提供一个简单易 ...
- Lucene查询索引(分页)
分页查询只需传入每页显示记录数和当前页就可以实现分页查询功能 Lucene分页查询是对搜索返回的结果进行分页,而不是对搜索结果的总数量进行分页,因此我们搜索的时候都是返回前n条记录 package c ...
- Lucene查询索引
索引创建 以新闻文档为例,每条新闻是一个document,新闻有news_id.news_title.news_source.news_url.news_abstract.news_keywords这 ...
- 学习笔记CB011:lucene搜索引擎库、IKAnalyzer中文切词工具、检索服务、查询索引、导流、word2vec
影视剧字幕聊天语料库特点,把影视剧说话内容一句一句以回车换行罗列三千多万条中国话,相邻第二句很可能是第一句最好回答.一个问句有很多种回答,可以根据相关程度以及历史聊天记录所有回答排序,找到最优,是一个 ...
随机推荐
- mysql复习2
-- 1. 创建和管理表 CREATE TABLE -- 方式一:CREATE TABLE emp1( id INT(10), `name` VARCHAR(20), salary DOUBLE(10 ...
- 实战_Spring_Cloud
目录 前言 开发环境 源码地址 创建工程 服务注册中心(Eureka) Eureka Server Eureka Client 注册中心高可用 小结 负载均衡(Ribbon) RestTemplate ...
- Nest.js你学不会系列-初识Nest
前言 最近在学习研究 Nest 框架,但是在学习过程中除了参考翻阅官方文档外国内几乎没有多少资料能系统的讲解 Nest 的相关内容,所以打算想通过我自己学习的角度讲解下 Nest 框架,不知道能坚持多 ...
- 机器学习回顾篇(15):集成学习之GDBT
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- Python 之redis操作
Redis 是一个高性能的key-value数据库,是一种非关系型的数据库.有以下三个特点: Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用. Redis不 ...
- Python的条件控制及循环
一.条件控制: 1.If语句的使用: Python中if语句的一般形式如下所示: 上图中: 如果 "score>=90" 为 True 将执行 "print(‘优秀 ...
- Celery异步处理
1.Celery概述 1.1问题抛出 我们在做网站后端程序开发时,会碰到这样的需求:用户需要在我们的网站填写注册信息,我们发给用户一封注册激活邮件到用户邮箱,如果由于各种原因,这封邮件发送所需时间较长 ...
- python3操作MySQL的模块pymysql
本文介绍Python3连接MySQL的第三方库--PyMySQL的基本使用. PyMySQL介绍 PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中 ...
- 从App.config中读取数据库连接字符串
1.首先在App.config文件中添加如下代码注意<connectionStrings>插入位置. <connectionStrings> <add name=&quo ...
- 基于 HTML5 WebGL 的智慧城市(一)
前言 中共中央.国务院在今年12月印发了<长江三角洲区域一体化发展规划纲要>(下文简称<纲要>),并发出通知,要求各地区各部门结合实际认真贯彻落实. <纲要>强调, ...