lasso-ridge
L1与L2正则化的区别与联系
L1正则化和L2正则化的说明如下:
L1正则化:\(\min _{w} \frac{1}{2 n_{\text {samples}}}\|X w-y\|_{2}^{2}+\alpha\|w\|_{1}\) 绝对值之和
L2正则化:\(\min _{w}\|X w-y\|_{2}^{2}+\alpha\|w\|_{2}^{2}\) 平方和
L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
L1 L2 区别:
相同点:都用于避免过拟合
不同点:L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。
L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况
- L2 regularizer :使得模型的解偏向于 norm 较小的 W,通过限制 W 的 norm 的大小实现了对模型空间的限制,从而在一定程度上避免了 overfitting 。不过 ridge regression 并不具有产生稀疏解的能力,得到的系数 仍然需要数据中的所有特征才能计算预测结果,从计算量上来说并没有得到改观。会选择更多的特征,这些特征都会接近于0。 最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0
- L1 regularizer :** 它的优良性质是能产生稀疏性,因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵, 导致 W 中许多项变成零。** 稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”csdn
L1稀疏性的原因
解空间形状直观理解
带正则项,相当于为目标函数的解空间进行了约束。当参数为2维时,为对于L2正则项,解空间为原型,L1正则项解空间为菱形。最优解必定是有且仅有一个交点。除非目标函数具有特殊的形状,否则和菱形的唯一交点大概率出现在截距处(即对应某一维度参数为0)。而对于圆形的解空间,总存在一个切点,且仅当某些特殊情况下,切点才会位于坐标轴上csdn

而正则化前面的系数α,可以控制L图形的大小。α越小,L的图形越大(上图中的黑色方框);α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)中的w可以取到很小的值。
类似,假设有如下带L2正则化的损失函数:
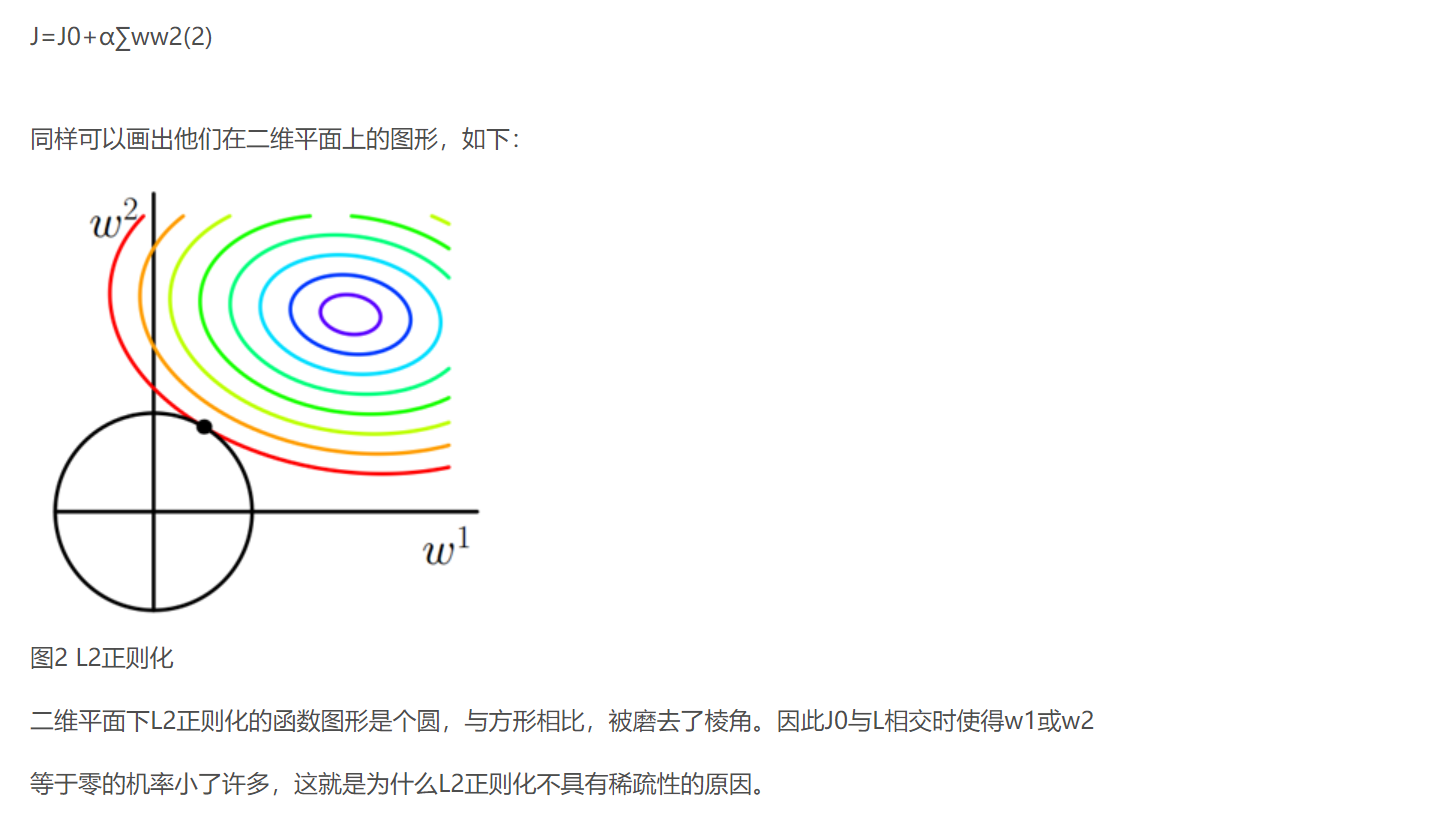

lasso 回归和岭回归(ridge regression)其实就是在标准线性回归的基础上分别加入 L1 和 L2 正则化(regularization)。
正则化
岭回归-Ridge
Loss function = OLS loss function +\(\alpha * \sum_{i=1}^{n} a_{i}^{2}\)
Lasso is great for feature selection, but when building regression models, Ridge regression should be your first choice.
datacamp
# Import necessary modules
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# Setup the array of alphas and lists to store scores
alpha_space = np.logspace(-4, 0, 50)
ridge_scores = []
ridge_scores_std = []
# Create a ridge regressor: ridge
ridge = Ridge(normalize=True)
# Compute scores over range of alphas
# 给出很多a值,调参,就是超参数调参
for alpha in alpha_space:
# Specify the alpha value to use: ridge.alpha
ridge.alpha = alpha
# Perform 10-fold CV: ridge_cv_scores
# 用到了10折交叉验证进行的调参
ridge_cv_scores = cross_val_score(ridge, X, y, cv=10)
# Append the mean of ridge_cv_scores to ridge_scores
ridge_scores.append(np.mean(ridge_cv_scores))
# Append the std of ridge_cv_scores to ridge_scores_std
ridge_scores_std.append(np.std(ridge_cv_scores))
# Display the plot
display_plot(ridge_scores, ridge_scores_std)

Lasso_套索回归(最小绝对值收敛)
Loss function = OLS loss function +\(\alpha * \sum_{i=1}^{n}\left|a_{i}\right|\)
lasso一般用来进行特征选择
- hrinks the coefcients of less important features to exactly 0
# Import Lasso
from sklearn.linear_model import Lasso
# Instantiate a lasso regressor: lasso
lasso = Lasso(alpha=0.4, normalize=True)
# Fit the regressor to the data
lasso.fit(X, y)
# Compute and print the coefficients
lasso_coef = lasso.coef_
print(lasso_coef)
# Plot the coefficients
plt.plot(range(len(df_columns)), lasso_coef)
plt.xticks(range(len(df_columns)), df_columns.values, rotation=60)
plt.margins(0.02)
plt.show()

lasso-ridge的更多相关文章
- 【机器学习】Linear least squares, Lasso,ridge regression有何本质区别?
Linear least squares, Lasso,ridge regression有何本质区别? Linear least squares, Lasso,ridge regression有何本质 ...
- 《机器学习_01_线性模型_线性回归_正则化(Lasso,Ridge,ElasticNet)》
一.过拟合 建模的目的是让模型学习到数据的一般性规律,但有时候可能会学过头,学到一些噪声数据的特性,虽然模型可以在训练集上取得好的表现,但在测试集上结果往往会变差,这时称模型陷入了过拟合,接下来造一些 ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- 变量的选择——Lasso&Ridge&ElasticNet
对模型参数进行限制或者规范化能将一些参数朝着0收缩(shrink).使用收缩的方法的效果提升是相当好的,岭回归(ridge regression,后续以ridge代称),lasso和弹性网络(elas ...
- 再谈Lasso回归 | elastic net | Ridge Regression
前文:Lasso linear model实例 | Proliferation index | 评估单细胞的增殖指数 参考:LASSO回歸在生物醫學資料中的簡單實例 - 生信技能树 Linear le ...
- PRML读书会第三章 Linear Models for Regression(线性基函数模型、正则化方法、贝叶斯线性回归等)
主讲人 planktonli planktonli(1027753147) 18:58:12 大家好,我负责给大家讲讲 PRML的第3讲 linear regression的内容,请大家多多指教,群 ...
- 7 Types of Regression Techniques you should know!
翻译来自:http://news.csdn.net/article_preview.html?preview=1&reload=1&arcid=2825492 摘要:本文解释了回归分析 ...
- 机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho
机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho 总述 本书是 2014 ...
- 深入理解:Linear Regression及其正则方法
这是最近看到的一个平时一直忽略但深入研究后发现这里面的门道还是很多,Linear Regression及其正则方法(主要是Lasso,Ridge, Elastic Net)这一套理论的建立花了很长一段 ...
- Kaggle竞赛 —— 房价预测 (House Prices)
完整代码见kaggle kernel 或 Github 比赛页面:https://www.kaggle.com/c/house-prices-advanced-regression-technique ...
随机推荐
- spring中获取bean的方式
获取bean的方式 1.可以通过上下文的getBean方法 2.可以通过@Autowired注入 定义controller @RestController @RequestMapping(" ...
- Go语言实现:【剑指offer】字符流中第一个不重复的字符
该题目来源于牛客网<剑指offer>专题. 请实现一个函数用来找出字符流中第一个只出现一次的字符.例如,当从字符流中只读出前两个字符"go"时,第一个只出现一次的字符是 ...
- 青石巷-小L的爸爸
小L有一个和谐的家. 爸爸具体职业不明,在统战部工作,刚开始和妈妈在一起工作. 妈妈是个会跳舞的语文老师. 奶奶之前也是个老师. 爷爷是个建筑师. 爸爸是最有文采的一个.在小L看来,他的一言一行,一举 ...
- 【redis】-- redis的持久化(作为数据库)
目录 1.RDB rdb持久化的方式 rdb方式的优点: aof的优点 3.持久化的其他特性 日志重写 工作原理 rdb和aof混合使用 redis是一个基于内存的数据库,故在redis正在运行的数据 ...
- php 搭建webSocket
<?php //2.设计一个循环挂起WebSocket通道,进行数据的接收.处理和发送 //对创建的socket循环进行监听,处理数据 function run(){ //死循环,直到socke ...
- VFP日期时间转中文日期时间
本函数原为VFP中取日期转中文日期方式,后增加日期时间处理,并改用Iif及ICase修改原代码.Function DateTime2CHNParameters pdDate,plTime*!* pdD ...
- MSFVENOM SHELLCODE生成备忘录
MSFVENOM SHELLCODE生成 通用Shellcode msfvenom -a x86 --platform windows -p windows/shell_reverse_tcp LHO ...
- IntelliJ 更改项目使用的 JDK 版本
在当前使用的 IntelliJ 中的 JDK 版本为 1.8,如何修改 IntelliJ 使用的 JDK 版本为 1.11 呢? 你可以在 IntelliJ 中进行修改. 选择 File 后,然后选择 ...
- xmppmini 项目详解:一步一步从原理跟我学实用 xmpp 技术开发 2.登录的实现
第二章登录的实现 金庸<倚天屠龙记> 张三丰缓缓摇头,说道:“少林派累积千年,方得达成这等绝技,决非一蹴而至,就算是绝顶聪明之人,也无法自创.”他顿了一顿,又道:“我当年在少林寺中住过,只 ...
- 开源工作流管理系统节点接收人设置“指定节点处理人”系列讲解
关键字: 驰骋工作流程快速开发平台 工作流程管理系统 工作流引擎 asp.net工作流引擎 java工作流引擎. 开发者表单 拖拽式表单 工作流系统CCBPM节点访问规则接收人规则 适配数据库: o ...