CUDA学习(四)之使用全局内存进行归约求和(一个包含N个线程的线程块)
问题:使用CUDA进行数组元素归约求和,归约求和的思想是每次循环取半。
详细过程如下:
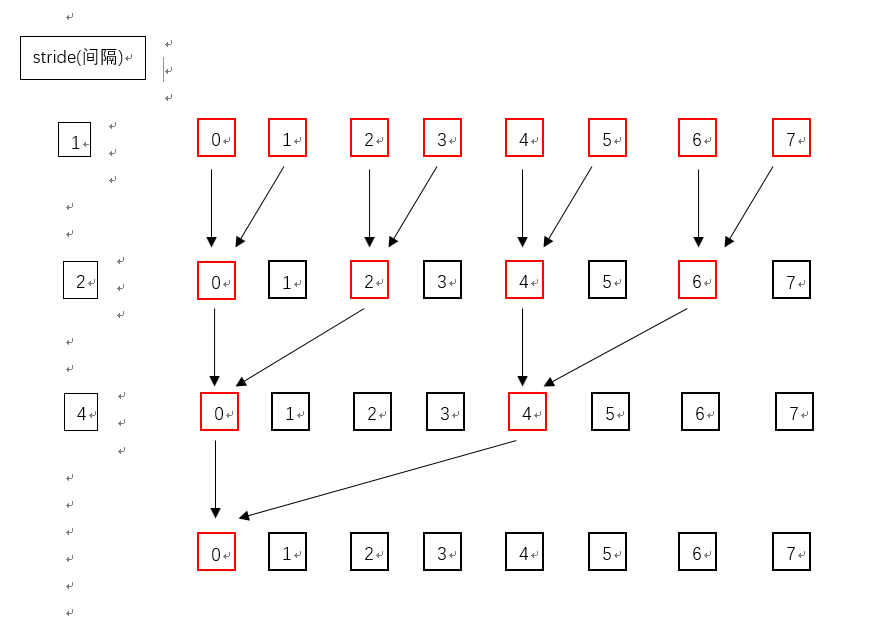
假设有一个包含8个元素的数组,索引下标从0到7,现通过3次循环相加得到这8个元素的和,使用一个间隔变量,该间隔变量随循环次数改变(累乘)。
第一次循环,间隔变量stride等于1,将0与1号元素、2与3号元素、4与5号元素、6与7号元素相加并将结果分别保存在0、2、4、6号元素中(图中红色框所示)。
第二次循环,间隔变量stride等于2,将0与2号元素、4与6号元素相加并将结果分别保存在0、4号元素中(图中红色框所示)。
第三次循环,间隔变量stride等于4,将0与4号元素相加并将结果保存在0号元素中(图中红色框所示)。
三次循环过后,整个数组元素相加之和就保存在数组0号元素中。
代码如下:
#pragma once
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "device_functions.h" #include <iostream> using namespace std; const int N = 128; //数组长度 __global__ void d_ParallelTest(double *Para)
{
int tid = threadIdx.x;
//----随循环次数的增加,stride逐次翻倍(乘以2)-----------------------------------------------------
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if (tid % (2 * stride) == 0)
{
Para[tid] += Para[tid + stride]; //对应上图中红色框的元素
}
__syncthreads();
} } void ParallelTest()
{
double *Para;
cudaMallocManaged((void **)&Para, sizeof(double) * N); //统一内存寻址,CPU和GPU都可以使用的数组 double ParaSum = 0;
for (int i = 0; i<N; i++)
{
Para[i] = (i + 1) * 0.1; //数组赋值
ParaSum += Para[i]; //CPU端数组累加
} cout << " CPU result = " << ParaSum << endl; //显示CPU端结果
double d_ParaSum; d_ParallelTest << < 1, N >> > (Para); //调用核函数(一个包含N个线程的线程块) cudaDeviceSynchronize(); //同步
d_ParaSum = Para[0]; //从累加过后数组的0号元素得出结果
cout << " GPU result = " << d_ParaSum << endl; //显示GPU端结果 } int main() {
//并行归约
ParallelTest(); //调用归约函数 system("pause");
return 0;
}
结果如下所示(CPU和GPU计算结果一致):

CUDA学习(四)之使用全局内存进行归约求和(一个包含N个线程的线程块)的更多相关文章
- 【CUDA 基础】4.0 全局内存
title: [CUDA 基础]4.0 全局内存 categories: - CUDA - Freshman tags: - 全局内存 - CUDA内存模型 - CUDA内存管理 - 全局内存编程 - ...
- CUDA学习(五)之使用共享内存(shared memory)进行归约求和(一个包含N个线程的线程块)
共享内存(shared memory)是位于SM上的on-chip(片上)一块内存,每个SM都有,就是内存比较小,早期的GPU只有16K(16384),现在生产的GPU一般都是48K(49152). ...
- 【CUDA 基础】5.3 减少全局内存访问
title: [CUDA 基础]5.3 减少全局内存访问 categories: - CUDA - Freshman tags: - 共享内存 - 归约 toc: true date: 2018-06 ...
- CUDA学习(七)之使用CUDA内置API计时
问题:对于使用GPU计算时,都想知道kernel函数运行所耗费的时间,使用CUDA内置的API可以方便准确的获得kernel运行时间. 在CPU上,可以使用clock()函数和GetTickCount ...
- CUDA学习笔记(四)——CUDA性能
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5h.html 四.CUDA性能 CUDA中的block被划分成一个个的warp,在GeForce880 ...
- CUDA学习笔记(三)——CUDA内存
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5f.html 结合lec07_intro_cuda.pptx学习 内存类型 CGMA: Compute ...
- cuda学习3-共享内存和同步
为什么要使用共享内存呢,因为共享内存的访问速度快.这是首先要明确的,下面详细研究. cuda程序中的内存使用分为主机内存(host memory) 和 设备内存(device memory),我们在这 ...
- 【CUDA 基础】5.4 合并的全局内存访问
title: [CUDA 基础]5.4 合并的全局内存访问 categories: - CUDA - Freshman tags: - 合并 - 转置 toc: true date: 2018-06- ...
- CUDA学习(六)之使用共享内存(shared memory)进行归约求和(M个包含N个线程的线程块)
在https://www.cnblogs.com/xiaoxiaoyibu/p/11402607.html中介绍了使用一个包含N个线程的线程块和共享内存进行数组归约求和, 基本思路: 定义M个包含N个 ...
随机推荐
- SpringBoot Starter机制 - 自定义Starter
目录 前言 1.起源 2.SpringBoot Starter 原理 3.自定义 Starter 3.1 创建 Starter 3.2 测试自定义 Starter 前言 最近在学习Sp ...
- appium工作流程解析
为什么选择appium app自带测试框架,为什么要选择appium这个测试框架呢? Ios9.3以前使用的是UIAutomation,Ios9.3以后使用XCUITest.如果只使用Apple的 ...
- CEF编译遇到的问题记录
在使用vs2015编译cef官方代码的时候遇到很奇怪的问题, 我用官方的demo cefsimple例子程序编译debug版本 可以正常编译打开网页 正常的打开 我把官方的例子单独创建一个新的项目编译 ...
- 洛谷$P$2522 $Problem\ b\ [HAOI2011]$ 莫比乌斯反演
正解:莫比乌斯反演 解题报告: 传送门! 首先看到这个显然就想到莫比乌斯反演$QwQ$? 就先瞎搞下呗$QwQ$ $gcd(x,y)=k$,即$gcd(\left \lfloor \frac{x}{k ...
- Ceph14.2.5 RBD块存储的实战配置和详细介绍,不看后悔! -- <3>
Ceph RBD介绍与使用 RBD介绍 RBD即RADOS Block Device的简称,RBD块存储是最稳定且最常用的存储类型.RBD块设备类似磁盘可以被挂载. RBD块设备具有快照.多副本.克隆 ...
- Web漏洞总结: OWASP Top 10
本文原创,更多内容可以参考: Java 全栈知识体系.如需转载请说明原处. 开发安全 - OWASP Top 10 在学习安全需要总体了解安全趋势和常见的Web漏洞,首推了解OWASP,因为它代表着业 ...
- Oracle表空间概述及其基本管理
最近在工作中遇到有同事对Oracle表空间的理解有问题,所以写了这篇文章.我会从概念,管理及特别需要关注的点等几个维度对表空间进行一些介绍.本文以介绍表空间为主,涉及到的其他概念不展开描述.有问题的地 ...
- 动态规划,以LeetCode-CombinationSumIV问题为例
简介: 动态规划问题面试中经常遇到的问题之一,按照动态规划的一般定义,其一般解法在于将大问题分解为很多小问题去解决,但是我在遇到很多实际的问题时,想法都是强行的去将问题分解,而忽略了分解的必要性和途径 ...
- String字符串,输入一串字符判断其中数字,字母,其他的字符的个数
public class StringClassTest { public static void main(String[] args) { //遍历字符串 String str = "H ...
- 6、使用基元类型而不要使用 FCL 类型
基元类型: int string object uint long ulong 等 ; FCL (Framework Class Library ) System.Int32 等. 一些定义在一些语言 ...