Transformer 详解
感谢:https://www.jianshu.com/p/04b6dd396d62
Transformer模型由《Attention is all your need》论文中提出,在seq2seq中应用,该模型在Machine Translation任务中表现很好。
动机
常见的seq2seq问题,比如摘要提取,机器翻译等大部分采用的都是encoder-decoder模型。而实现encoder-decoder模型主要有RNN和CNN两种实现;
CNN
cnn 通过进行卷积,来实现对输入数据的特征提取,不同的卷积核对应于不同的特征,通过CNN的层级链接实现对目标从局部到整体的感知。

CNN主要用在图像领域,nlp里也有应用,但是不是主流。
cnn很成熟,也有一些缺陷,比如学习一句话中任意两个词语的关系时,需要多层来实现,这样关系的学习需要对数次
RNN
深度学习最早在cnn上实现了大跃进,但是在一些场景下,比如系统的输出和系统之前的状态也有关系,这就需要网络有一定的记忆功能,这时引入了RNN。RNN在进行预测时,会将系统的历史状态也作为一个输入参与,从而实现利用历史信息进行预测。
RNN 擅长处理变长序列, 在nlp中用的较多。

但是rnn也存在一些问题
- 训练和预测数据依次送入模型,并行化难度大
- 长程依赖虽然通过lstm等有所解决,但是还是不够。
- 对于层次化信息的效果建模不佳
核心问题
针对rnn和cnn的缺陷,怎么解决这些问题呢?(问题如下)
- 并行化
- 提升长程依赖的学习能力
- 层次化建模
Transformer结构
针对于上面rnn和cnn的问题,google的人提出了一种新的网络结构用来解决他们的问题。
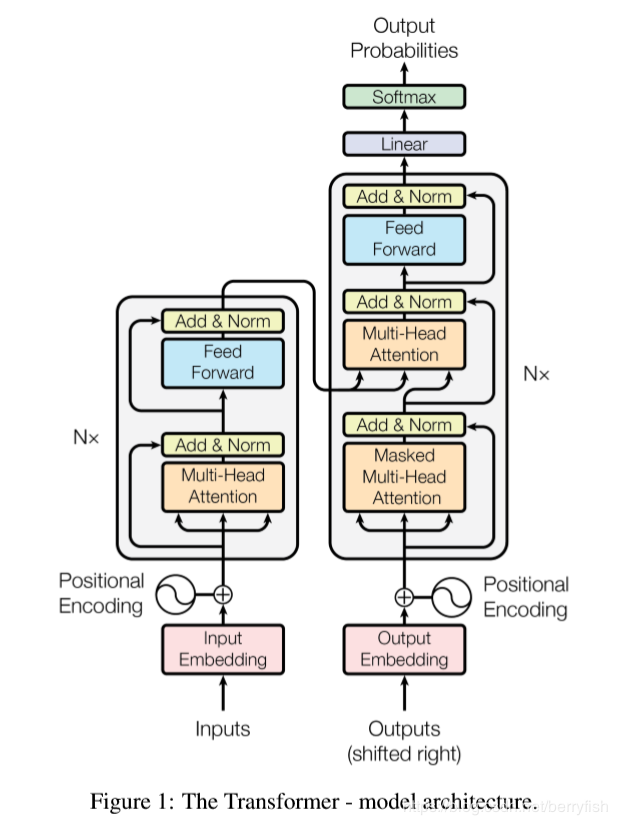
- encoder
途中左侧部分是encoder块,encoder中6层相同结构堆叠而成,在每层中又可以分为2个子层,底下一层是multihead self-attention层,上面是一个FC feed-forward层,每一个子层都有residual connection,,然后在进行Layer Normalization. 为了引入redisual connenction简化计算,每个层的输入维数和embedding层保持一致。 - decoder
同样是一个6层的堆叠,每层有三个子层,其中底下两层都是multihead self-attention层,最底下一层是有mask的,只有当前位置之前的输入有效,中间层是encode和decode的连接层,输出的self-attention层和输入的encoder输出同时作为MSA的输入,实现encoder和decoder的连接,最上层和encoder的最上层是一样的,不在单说,每个子层都有有residual connection,和Layer Normalization
亮点
self-Attention
传统的encoder-decoder实现
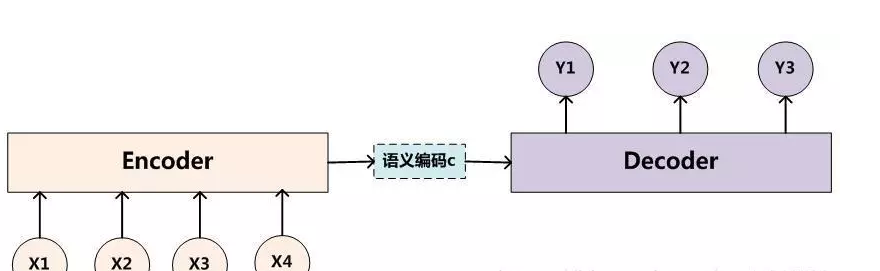
传统的编解码结构中,将输入输入编码为一个定长语义编码,然后通过这个编码在生成对应的输出序列。它存在的一个问题在于:输入序列不论长短都会被编码成一个固定长度的向量表示,而解码则受限于该固定长度的向量表示。
针对这个问题,《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》这个论文引入了attenion。他的网络结构和传统的区别在与,encoder的输出不是一个语义向量,是一个语义向量的序列,然后在解码阶段,会有选择的从向量序列中选择一个子集,这个子集怎么选取,子集元素占比的多少就是attention解决的问题。


Attention本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射,如下图
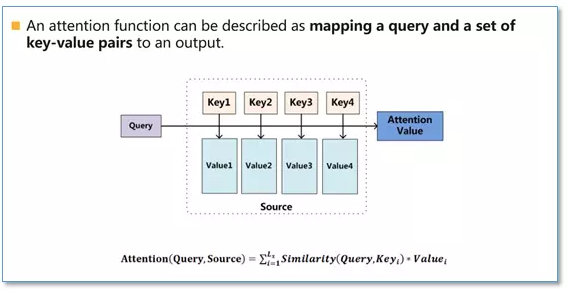
在计算attention时主要分为三步,第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;然后第二步一般是使用一个softmax函数对这些权重进行归一化;最后将权重和相应的键值value进行加权求和得到最后的attention。目前在NLP研究中,key和value常常都是同一个,即key=value。
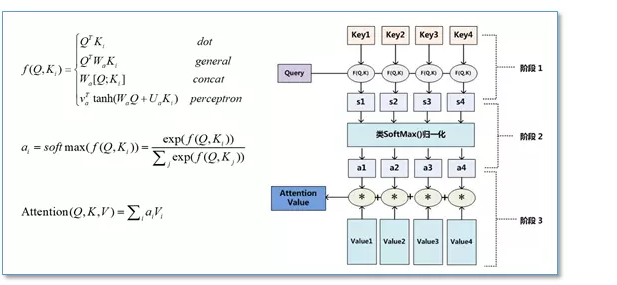
但是在Transformer的Attenion函数称为scaled dot-Product Attention,
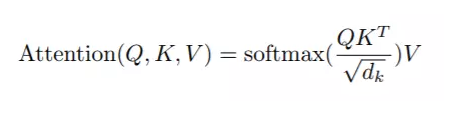
是在点积attension的基础上除了一个 √dk.论文中提到点积和Additive Attension的复杂度差不多,但是借助于优化的Matrix乘法,dot-Product在内存占用和运行速度上更优。之所以引入 √dk, 论文认为如果 key的维数 dk 特别大的话,那么有可能点积有可能变的很大,导致后面的softmax函数进入一个梯度很小的范围,不利于训练。
MultiHead Attention
上面讨论了Transformer中的Attentioin的原理,但是会有一个问题,就是计算时会分为两个阶段,第一个阶段计算出softmax部分,第二部分是在乘以 Value部分,这样还是串行化的,并行化不够。
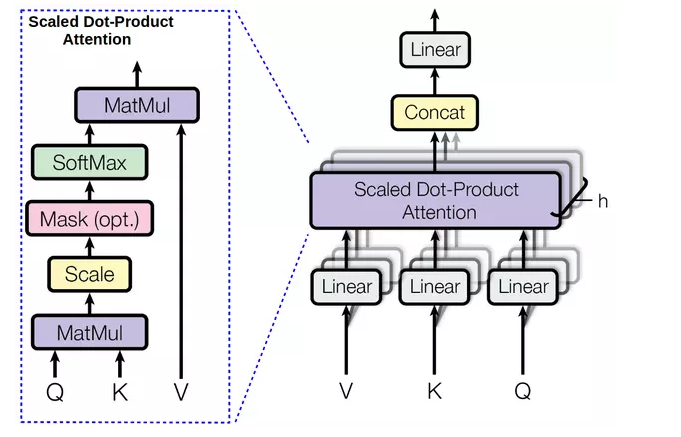
论文中采用MultiHeadAttention,对query,key,value各自进行一次不同的线性变换,然后在执行一次softmax操作,这样可以提升并行度,论文中的head数是8个。
同时不同的head学习到词语间的不同关系
position Encoding
语言是有序的,在cnn中,卷积的形状包含了位置信息,在rnn中,位置的先后顺序其实是通过送入模型的先后来保证。transformer抛弃了cnn和rnn,那么数据的位置信息怎么提供呢?
Transformer通过position Encoding来额外的提供位置信息,每一个位置对应一个向量,这个向量和word embedding求和后作为 encoder和decoder的输入。这样,对于同一个词语来说,在不同的位置,他们送入encoder和decoder的向量不同。
Transformer中的
PE(pos,2i) = sin(pos / 100002i/dmodel )
PE(pos,2i+i) = cos(pos / 100002i/dmodel )
总结一下
- 最后在看一下整个Transformer
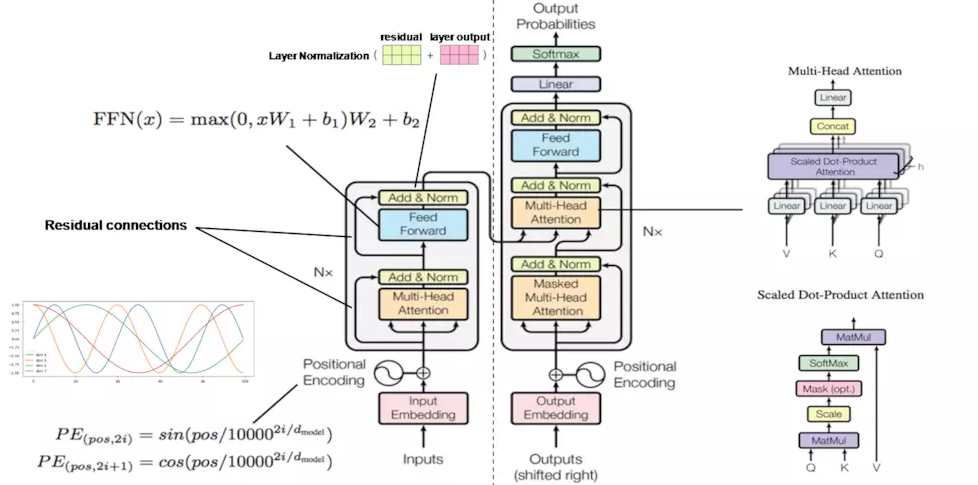
- 整体的训练过程

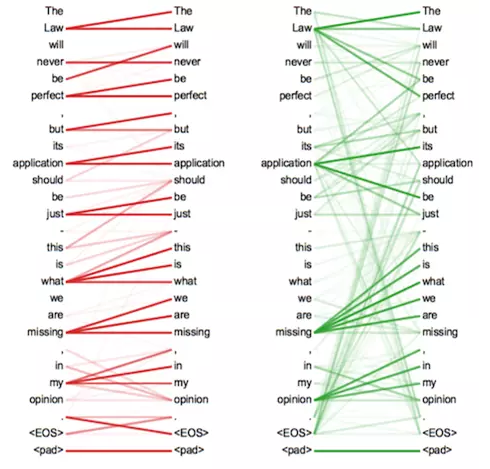
self-attension的一个效果
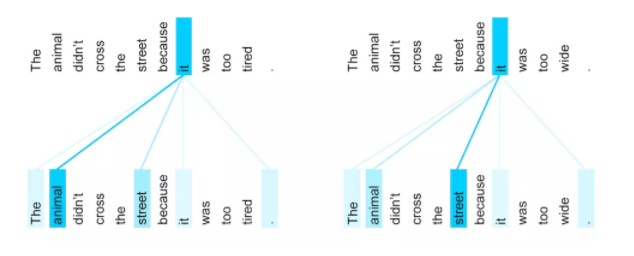
- 从效果上来看it在两个很相似的句子中,能够发现自己和不同的词语关系的变化。
Transformer 详解的更多相关文章
- Transformer详解:各个特征维度分析推导
谷歌在文章<Attention is all you need>中提出的transformer模型.如图主要架构:同样为encoder-decoder模式,左边部分是encoder,右边部 ...
- Attention和Transformer详解
目录 Transformer引入 Encoder 详解 输入部分 Embedding 位置嵌入 注意力机制 人类的注意力机制 Attention 计算 多头 Attention 计算 残差及其作用 B ...
- Transformer详解
0 简述 Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行. 并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提 ...
- Transformer各层网络结构详解!面试必备!(附代码实现)
1. 什么是Transformer <Attention Is All You Need>是一篇Google提出的将Attention思想发挥到极致的论文.这篇论文中提出一个全新的模型,叫 ...
- seq2seq模型详解及对比(CNN,RNN,Transformer)
一,概述 在自然语言生成的任务中,大部分是基于seq2seq模型实现的(除此之外,还有语言模型,GAN等也能做文本生成),例如生成式对话,机器翻译,文本摘要等等,seq2seq模型是由encoder, ...
- 无所不能的Embedding6 - 跨入Transformer时代~模型详解&代码实现
上一章我们聊了聊quick-thought通过干掉decoder加快训练, CNN-LSTM用CNN作为Encoder并行计算来提速等方法,这一章看看抛开CNN和RNN,transformer是如何只 ...
- 78. Android之 RxJava 详解
转载:http://gank.io/post/560e15be2dca930e00da1083 前言 我从去年开始使用 RxJava ,到现在一年多了.今年加入了 Flipboard 后,看到 Fli ...
- 给 Android 开发者的 RxJava 详解
我从去年开始使用 RxJava ,到现在一年多了.今年加入了 Flipboard 后,看到 Flipboard 的 Android 项目也在使用 RxJava ,并且使用的场景越来越多 .而最近这几个 ...
- Fiddler界面详解
Statistics 页签 完整页签如下图: Statistics 页签显示当前用户选择的 Sessions 的汇总信息,包括:选择的 Sessions 总数.发送字节数.接收字节数.响应类型的汇总表 ...
随机推荐
- 大白话原型模式(Prototype Pattern)
意图 原型模式是创建型设计模式,可以复制已存在的对象而无需依赖它的类. 问题 假如现在有一个对象,我们想完全复制一份新的,我们该如何做? 创建同一个类的新对象 遍历所有已存在对象的值,然后将他们的值复 ...
- 各种小的 dp (精)
Q~ 抛一枚硬币 n 次,每次可能是正面或者反面向上,求没有连续超过 k 次硬币向上的方案数 A : dp[ i ] 表示到 i 位置的方案数, 1 . 当 i < k 时, dp[i] = d ...
- Java 集合源代码——ArrayList
(1)可以查看大佬们的 详细源码解析 : 连接地址为 : https://blog.csdn.net/zhumingyuan111/article/details/78884746 (2) Array ...
- hdu6638 线段树求最大子段和
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6638 Problem Description There are n pirate chests bu ...
- 换装WIN10(windows)那点儿事,换装操作系统一文通,玩转安装操作系统
目录 1. 按 2. win10对电脑配置的要求 3. 原版镜像下载 4. 制作U盘系统盘 5. 硬盘分区调整 6. 设置开机时从U盘启动 7. 安装win10 8. 如何激活WIN10 9. 如何给 ...
- 月经贴 】 Csharp in depth
让你 真正 喜欢 上 C# 编译器 准备 为你 上演 的 奇迹. C# 3 中 相对 乏味 的 一些 特性 开始. 自动 实现 的 属性 和 简化 的 初始化, 有一个 私 有的 无 参 构造 函 ...
- Java学习笔记(二) 面向对象---构造函数
面向对象---构造函数 特点 函数名与类名相同 不用定义返回值类型 不写return语句 作用 对象一建立,就对象进行初始化. 具体使用情况 class Student { Student(){ Sy ...
- 时间序列数据库(TSDB)初识与选择
时间序列数据库(TSDB)初识与选择 本文作者由 MageByte 团队的 「借来方向」编写,关注公众号 给你更多硬核技术 背景 这两年互联网行业掀着一股新风,总是听着各种高大上的新名词.大数据.人工 ...
- Redhat6.7 切换Centos yum源
转自:http://inlhx.iteye.com/blog/2336729 RedHat 更换Yum源 1.检查yum包 rpm -qa |grep yum 2.删除自带包 rpm -aq | gr ...
- hash算法与拉链法解决冲突
<?php class HashNode { public $key; public $value; public $nextNode; public function __construct( ...