PYTHON HTML.PARSER库学习小结--转载
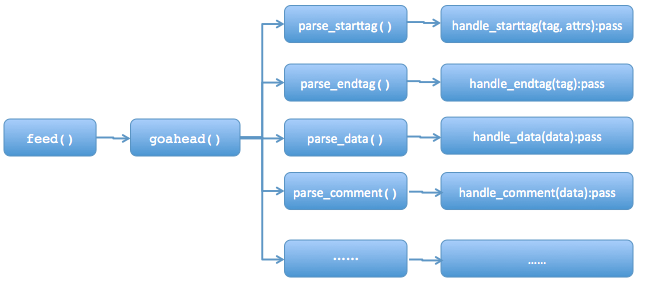
- feed(data):主要用于接受带html标签的str,当调用这个方法时并提供相应的data时,整个实例(instance)开始执行,结束执行close()。
- handle_starttag(tag, attrs): 这个方法接收Parse_starttag返回的tag和attrs,并进行处理,处理方式通常由使用者进行覆盖,本身为空。例如,连接的start tag是<a>,那么对应的参数tag=’a’(小写)。attrs是start tag <>中的属性,以元组形式(name, value)返回(所有这些内容都是小写)。例如,对于<A HREF="http://www.baidu.com“>,那么内部调用形式为:handle_starttag(’a’,[(‘href’,’http://www.baidu.com)]).
- handle_endtag(tag):跟上述一样,只是处理的是结束标签,也就是以</开头的标签。
- handle_data(data):处理的是网页的数据,也就是开始标签和结束标签之间的内容。例如:<script>...</script>的省略号内容
- reset():将实例重置,包括作为参数输入的数据进行清空。
</h3>
<p class="tb-subtitle">
【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】 【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】 【金冠信誉+顺丰包邮+全国联保---多重保障】
</p>
<div id="J_TEditItem" class="tb-editor-menu"></div>
【现货增强/标准】MIUI/小米 红米手机2红米2移动联通电信4G双卡
</h3>
<p class="tb-subtitle">
[红米手机2代颜色版本较多,请亲们阅读购买说明按需选购---感谢光临] 【金皇冠信誉小米手机集市销量第一】【购买套餐送高清钢化膜+线控通话耳机+ 剪卡器(含还原卡托)+ 防辐射贴+专用高清贴膜+ 擦机布+ 耳机绕线器+手机电影支架+ 一年延保服务+ 默认享受顺丰包邮 !
</p>
<div id="J_TEditItem" class="tb-editor-menu"></div>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#定义一个MyParser继承自HTMLParserclass MyParser(HTMLParser): re=[]#放置结果 flg=0#标志,用以标记是否找到我们需要的标签 def handle_starttag(self, tag, attrs): if tag=='h3':#目标标签 for attr in attrs: if attr[0]=='class' and attr[1]=='tb-main-title':#目标标签具有的属性 self.flg=1#符合条件则将标志设置为1 break else: pass def handle_data(self, data): if self.flg==1: self.re.append(data.strip())#如果标志为我们需要的标志,则将数据添加到列表中 self.flg=0#重置标志,进行下次迭代 else: passmy=MyParser()my.feed(html) |

PYTHON HTML.PARSER库学习小结--转载的更多相关文章
- Python html.parser库学习小结
分类路径:/Datazen/DataMining/Crawler/ 前段时间,一朋友让我做个小脚本,抓一下某C2C商城上竞争对手的销售/价格数据,好让他可以实时调整自己的营销策略.自己之前也有过写 ...
- python爬虫解析库学习
一.xpath库使用: 1.基本规则: 2.将文件转为HTML对象: html = etree.parse('./test.html', etree.HTMLParser()) result = et ...
- Python之matplotlib库学习
matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地进行制图.而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中. 它的文档相当完备, ...
- python 之Requests库学习笔记
1. Requests库安装 Windows平台安装说明: 直接以管理员身份打开cmd运行界面,使用pip管理工具进行requests库的安装. 具体安装命令如下: >pip instal ...
- Python之matplotlib库学习:实现数据可视化
1. 安装和文档 pip install matplotlib 官方文档 为了方便显示图像,还使用了ipython qtconsole方便显示.具体怎么弄网上搜一下就很多教程了. pyplot模块是提 ...
- 基于Windows平台的Python多线程及多进程学习小结
python多线程及多进程对于不同平台有不同的工具(platform-specific tools),如os.fork仅在Unix上可用,而windows不可用,该文仅针对windows平台可用的工具 ...
- Python之Pandas库学习(二):数据读写
1. I/O API工具 读取函数 写入函数 read_csv to_csv read_excel to_excel read_hdf to_hdf read_sql to_sql read_json ...
- Python之Pandas库学习(一):简介
官方文档 1. 安装Pandas windos下cmd:pip install pandas 导入pandas包:import pandas as pd 2. Series对象 带索引的一维数组 创建 ...
- python的pandas库学习笔记
导入: import pandas as pd from pandas import Series,DataFrame 1.两个主要数据结构:Series和DataFrame (1)Series是一种 ...
随机推荐
- vue学习之五生命周期
一.vue生命周期图解 下图展示了实例的生命周期.你不需要立马弄明白所有的东西,不过随着你的不断学习和使用,它的参考价值会越来越高. 二.vue钩子函数使用 2.1beforeCreate 在实例初始 ...
- postman 安装,对elasticsearch进行请求
1 使用postman对elasticsearch进行测试 :下载插件: https://www.getpostman.com/apps ,下载时exe文件,双击自动安装,首次打开注册.下面就可以使 ...
- mac shell终端编辑命令行快捷键
Ctrl + d 删除一个字符,相当于通常的Delete键(命令行若无所有字符,则相当于exit:处理多行标准输入时也表示eof) Ctrl + h 退格删除一个字符,相当 ...
- HDU1180:诡异的楼梯(bfs+优先队列)
http://acm.hdu.edu.cn/showproblem.php?pid=1180 Problem Description Hogwarts正式开学以后,Harry发现在Hogwarts里, ...
- JavaScript加强
1.Aptana简介 Aptana是一个非常强大,开源,专注于JavaScript的Ajax开发IDE它的特性包括 1.JavaScript,JavaScript函数,HTML,CSS语言的Code ...
- 找出numpy array数组的最值及其索引
在list列表中,max(list)可以得到list的最大值,list.index(max(list))可以得到最大值对应的索引 但在numpy中的array没有index方法,取而代之的是where ...
- EF5.0区别于EF4.0的增删改写法
// 实现对数据库的添加功能,添加实现EF框架的引用 public T AddEntity(T entity) { //EF4.0的写法 添加实体 //db.CreateObjectSet<T& ...
- Linux (RHEL)修改时区
1.修改配置文件修改为上海时区 vi /etc/sysconfig/clock ZONE="Asia/Shanghai" 2.创建上海时区的软连接 ln -sf /usr/shar ...
- 搭建私有npm私库(使用verdaccio)
搭建 npm 离线服务器 为什么要搭建npm 服务器 原因: 公司内部开发的私有包,统一管理,方便开发和使用 安全性,由于公司内部开发的模块和一些内容并不希望其他无关人员能够看到,但是又希望内部能方便 ...
- Leetcode: Repeated DNA Sequence
All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: "ACG ...