基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升。
1. 系统架构层面。
DataPipeline引入DataPipeline Manager的概念,主要用于优化Source和Sink的全局化生命周期管理。当任务出现异常时,可以实现对目的端和全局生命周期的管理。例如,处理源端到目的端读取速率不匹配以及暂停等状态的协同。
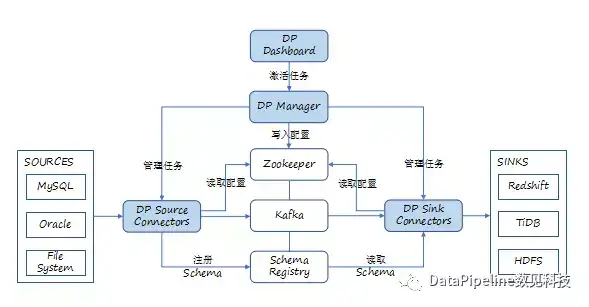
为了加强系统的健壮性,我们把Connector任务的参数保存在ZooKeeper中,方便任务重启后读取配置信息。
DataPipeline Connector通过JMX Client将统计信息上报Dashboard。在Connector中在技术上进行一些封装,把一些通用信息,比如说Connector历史读取信息,跟管理相关的信息都采集到Dashboard里面,提供给客户。
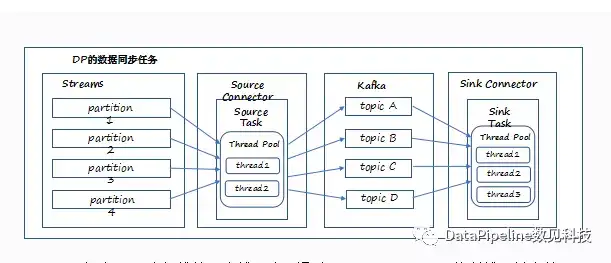
2. 任务并行模式。
DataPipeline在任务并行方面做了一些加强。我们在具体服务客户的时候也遇到这样的问题,需要同步数十张表。在DataPipeline Connector中,我们允许每个Task内部可以定义和维护一个线程池,通过控制线程并发数,并且每个Task允许设置行级别的IO控制。而对于JDBC类型的Task,我们额外允许配置连接池的大小,减少上游和下游资源的开销。
3. 规则引擎。
DataPipeline在基于Kafka Connect做应用时的基本定位是数据集成。数据集成过程中,不应当对数据进行大量的计算,但是又不可避免地要对一些字段进行过滤,所以在产品中我们也在考虑怎样提供一种融合性。

虽然Kafka Connect提供了一个Transformation接口可以与Source Connector和Sink Connector进行协同,对数据进行基本的转换。但这是以Connector为基本单位的,企业客户需要编译后部署到所有集群的节点,并且缺乏良好的可视化动态编译调试环境支持。
基于这种情况,DataPipeline产品提供了两种可视化配置环境:基本编码引擎(Basic Code Engine)和高级编码引擎(Advanced Code Engine)。前者提供包括字段过滤、字段替换和字段忽略等功能,后者基于Groovy可以更加灵活地对数据处理、并且校验处理结果的Schema一致性。对于高级编码引擎,DataPipeline还提供了数据采样和动态调试能力。
4. 错误队列机制。
我们在服务企业客户的过程中也看到,用户源端的数据永远不会很“干净”。不“干净”的数据可能来自几个方面,比如当文件类型数据源中的“脏记录”、规则引擎处理特定数据产生未预期的异常、因为目的端Schema不匹配导致某些值无法写入等各种原因。
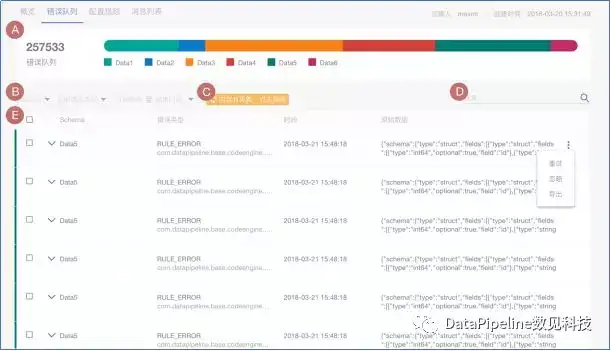
面对这些情况,企业客户要么把任务停下来,要么把数据暂存到某处后续再处理。而DataPipeline采取的是第二种方式,通过产品中错误队列预警功能指定面对错误队列的策略,支持预警和中断策略的设置和实施等,比如错误队列达到某个百分比的时候任务会暂停,这样的设置可以保证任务不会因少量异常数据而中断,被完整记录下来的异常数据可以被管理员非常方便地进行追踪、排查和处理。企业客户认为,相比以前通过日志来筛查异常数据,这种错误队列可视化设置功能大大提升管理员的工作效率。
在做数据集成的过程中,确实不应该对原始数据本身做过多的变换和计算。传统ETL方案把数据进行大量的变换之后,虽然会产生比较高效的输出结果,但是当用户业务需求发生变化时,还需要重新建立一个数据管道再进行一次原始数据的传输。这种做法并不适应当前大数据分析的需求。
基于这种考虑,DataPipeline会建议客户先做少量的清洗,尽量保持数据的原貌。但是,这并不是说,我们不重视数据质量。未来的重要工作之一,DataPipeline将基于Kafka Streaming将流式计算用于数据质量管理,它不对数据最终输出的结果负责,而是从业务角度去分析数据在交换过程中是否发生了改变,通过滑动窗口去判断到底数据发生了什么问题,判断条件是是否超出一定比例历史均值的记录数,一旦达到这个条件将进一步触发告警并暂停同步任务。
总结一下,DataPipeline经过不断地努力,很好地解决了企业数据集成过程需要解决异构性、动态性、可伸缩性和容错性等方面的问题;基于Kafka Connect的良好基础支撑构建了成熟的企业级数据集成平台;基于Kafka Connect进行二次封装和扩展,优化了应用Kafka Connect时面临的挑战:包括Schema映射和演进,任务并行策略和全局化管理等。未来,Datapipeline将会基于流式计算进一步加强数据质量管理。
更多关于实时数据集成和Kafka Connect的问题,欢迎直接访问官方网址申请试用:www.datapipeline.com
基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?的更多相关文章
- 基于Kafka Connect框架DataPipeline可以更好地解决哪些企业数据集成难题?
DataPipeline已经完成了很多优化和提升工作,可以很好地解决当前企业数据集成面临的很多核心难题. 1. 任务的独立性与全局性. 从Kafka设计之初,就遵从从源端到目的的解耦性.下游可以有很多 ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- 以Kafka Connect作为实时数据集成平台的基础架构有什么优势?
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的.可靠的流式传输数据的工具,可以更快捷和简单地将大量数据集合移入和移出Kafka的连接器.Kafka Connect为DataPi ...
- DataPipeline丨构建实时数据集成平台时,在技术选型上的考量点
文 | 陈肃 DataPipeline CTO 随着企业应用复杂性的上升和微服务架构的流行,数据正变得越来越以应用为中心. 服务之间仅在必要时以接口或者消息队列方式进行数据交互,从而避免了构建单一数 ...
- Kafka ETL 之后,我们将如何定义新一代实时数据集成解决方案?
上一个十年,以 Hadoop 为代表的大数据技术发展如火如荼,各种数据平台.数据湖.数据中台等产品和解决方案层出不穷,这些方案最常用的场景包括统一汇聚企业数据,并对这些离线数据进行分析洞察,来达到辅助 ...
- 基于 WebSocket 实现 WebGL 3D 拓扑图实时数据通讯同步(二)
我们上一篇<基于 WebSocket 实现 WebGL 3D 拓扑图实时数据通讯同步(一)>主要讲解了如何搭建一个实时数据通讯服务器,客户端与服务端是如何通讯的,相信通过上一篇的讲解,再配 ...
- 基于 WebSocket 实现 WebGL 3D 拓扑图实时数据通讯同步(一)
今天没有延续上一篇讲的内容,穿插一段小插曲,WebSocket 实时数据通讯同步的问题,今天我们并不是很纯粹地讲 WebSocket 相关知识,我们通过 WebGL 3D 拓扑图来呈现一个有趣的 De ...
- Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性
摘要:对于 PostgreSQL 的实时数据采集, 业界经常遇到了包括:对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂等等问题.Tapdata 在解决 Pos ...
- DataPipeline丨瓜子二手车基于Kafka的结构化数据流
文 |彭超 瓜子大数据架构师 交流微信 | datapipeline2018 一.为什么选择Kafka 为什么选Kafka?鉴于庞大的数据量,需要将其做成分布式,这时需要将Q里面的数据分到许多机器 ...
随机推荐
- 【翻译】Ext JS 4——Ajax和Rest代理处理服务器端一场和消息的方法
原文:EXTJS4 - Handle Server-side exceptions and message from an Ajax or Rest proxy 作者:Raja 可能要处理的情况:su ...
- (二十)即时通信的聊天气泡的实现I
Tip:通过xib和storyboard不可能将一个控件作为ImageView的子控件,只能通过代码的addSubview方法实现. 设置图片的细节:如果button比图片大(为了方便对齐),将图片设 ...
- 数据结构基础(1) --Swap & Bubble-Sort & Select-Sort
Swap的简单实现 //C语言方式(by-pointer): template <typename Type> bool swapByPointer(Type *pointer1, Typ ...
- C语言实现ifconfig获取网卡接收和发送流量统计
在Windows下我们可以利用ipconfig命令获取网卡的相关信息,在Linux下命令是ifconfig 我们可以获取的信息更为丰富,其中包括网卡接收和发送的流量,用C语言实现这个命令并不是一件简单 ...
- STL - queue(队列)
Queue简介 queue是队列容器,是一种"先进先出"的容器. queue是简单地装饰deque容器而成为另外的一种容器. #include <queue> queu ...
- TrueType和Bitmap字体的区别
只要标签的文本从不变化,在cocos2D中渲染TrueType和bitmap字体的性能是相同的.它们都仅仅像精灵那样绘制. 如果你希望大量的标签使用相同字体,则bitmap字体将更快.因为bitmap ...
- mybatis源码之PreparedStatementHandler
/** * @author Clinton Begin */ public class PreparedStatementHandler extends BaseStatementHandler { ...
- 数据结构-C语言递归实现树的前中后序遍历
#include <stdio.h> #include <stdlib.h> typedef struct tree { int number ; struct tree *l ...
- javascript中如何让类工厂和构造函数变成同一个函数
我们知道在js中可以用一个函数来定义对象的类,该函数称之为对象的构造函数,我们在需要create对象的时候直接调用这个构造函数即可: var Man = funciton(name){ this.na ...
- Fullpage.js全屏滚动jQuery插件
兼容性: 支持 IE8+ 及其他现代浏览器. 主要功能: 1.支持鼠标滚动: 2.支持前进后退键盘控制; 3.多个回调函数; 4.支持手机.移动设备; 5.支持窗口缩放自动调整; 6.可设置滚动宽度. ...