python--IO模块
IO模块
一 IO模型 分为:
1 阻塞IO (accept recv)
2 非阻塞IO
3 IO多路复用(监听多个链接)
4 异步IO
5 驱动信号模型(不经常使用)
1 阻塞IO (blocking IO)
特点:全程阻塞(进程不能干其他的事儿)
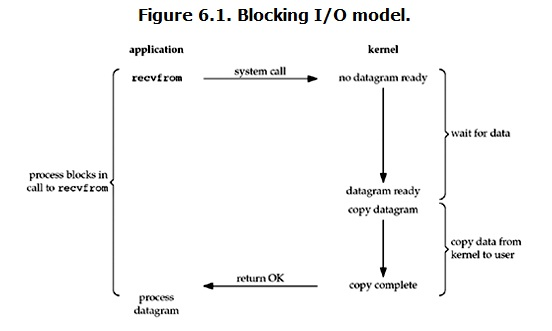
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达,这个时候kernel就要等待足够的数据到来,而在用户进程这边,整个进程会被阻塞。
当kernel直等到数据准备好了,他就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
2 非阻塞IO(non-blocking IO)
特点:发送多次系统调用
优点:wait for data时无阻塞
缺点:多次系统调用,消耗,不能第一时间拿取数据
两个阶段:wait for data非阻塞
cope data是阻塞的
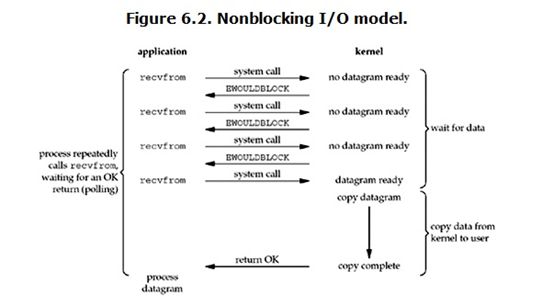
注意:在网络IO时候,非阻塞IO也会进行recvfrom系统调用,检查数据是否准备好,与阻塞IO不一样,”非阻塞将大的整片时间的阻塞分成N多的小的阻塞,所以进程不断地有机会’被CPU光顾’”。即每次recvfrom系统调用之间,cpu的权限还在进程手中,这段时间可以做其他事情。
也就是说非 阻塞的recvfrom系统调用,进程并没有被阻塞,内核马上返回给进程,如果数据还没有准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后在发起recvfrom系统调用,重复上面的过程。不断重复进行recvfrom系统调用,这个过程被称为轮询,轮询检查内核数据,直到数据被准备好,再拷贝数据到进程,进行数据处理,需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
#服务端
import socket
sk=socket.socket()
sk.bind(("127.0.0.1",8000))
sk.listen(5)
sk.setblocking(False)
while True:
try:
print("waiting.........")
conn,addr=sk.accept()
print("++++",conn)
data=conn.recv(1024)
print(data.decode("utf8")) except Exception as e:
print(e)
time.sleep(4) #客户端
import time
import socket
sk=socket.socket()
sk.connect(("127.0.0.1",8000))
while True:
data=input(">>")
sk.send(data.encode("utf-8"))
time.sleep(2) 执行结果:
waiting.........
[WinError 10035] 无法立即完成一个非阻止性套接字操作。
waiting.........
[WinError 10035] 无法立即完成一个非阻止性套接字操作。
waiting.........
[WinError 10035] 无法立即完成一个非阻止性套接字操作。
waiting.........
3 IO多路复用(IO multiplexing)
特点:1全程阻塞(wait for data, copy data)
2 能监听多个文件描述符
实现并发
select, epoll,poll
select发起系统调用(监听多个连接 实行并发)
对于文件描述符(套接字对象):
1 是一个非零整数,不会变
2 收发数据的时候,对于接收端而言,数据先到内核空间,然后通过copy到用户空间,同时,内核空间数据清空。
IO multiplexing这个词可能有点陌生,但是如果说select,epoll,大概就都能明白了,有些地方也称这用IO方式为event driven IO。我们知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO,它的基本原理就是selet/epoll这个function会不断的轮询所有的socket,当某个socket有数据到达了,就通知用户进程。
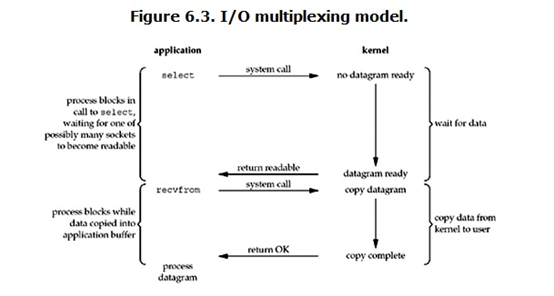
当用户进程调用了select,那么整个进程会被block,而同时,kernel会”监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就回返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
需要使用两个system call(select和recvfrom),而blocking IO只调用了一个system call(recvfrom)。
注意1:select函数返回结果中如果有文件可读了,那么进程就可以通过调用accept()或recv()
来让kernel将位于内核中准备到数据copy到用户区。
注意2:select的优势在于可以处理多个连接,不适用于单个连接
#服务端
import socket
import select
sock=socket.socket()
sock.bind(("127.0.0.1",8000))
sock.listen(5) # sock.setblocking(False)
inputs=[sock,]
while True:
r,w,e=select.select(inputs,[],[]) #监听有变化的套接字, for obj in r:
if obj==sock:
conn,addr=obj.accept()
inputs.append(conn) #l=[sock,conn]
else:
data=obj.recv(1024)
print(data.decode("utf8"))
send_data=input(">>>")
obj.send(send_data.encode("utf8")) #客户端
import socket
sock=socket.socket()
sock.connect(("127.0.0.1",8000)) while True:
data=input(">>>")
sock.send(data.encode("utf8"))
res=sock.recv(1024)
print(res.decode("utf8")) sock.close()
4 异步IO(Asynchronous I/O)
特点:全程无阻塞
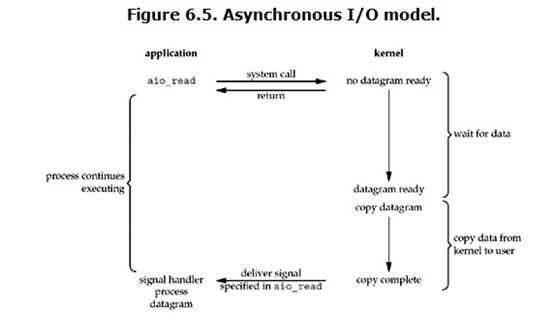
用户进程发起read操作之后,立刻就可以开始去做其他的事儿,从另一方面,从kernel的角度,当它收到一个asynchronous read 之后,首先它会立刻返回,所以不会对用户进程产生任何block,然后,kernel会 数据准备完成 ,然后将数据拷贝到用户内存,当着一切都完成之后,kernel就给用户进程发送一个signal,告诉它read操作完成了。
同步阻塞:包括(阻塞IO,非阻塞IO,IO多路复用)
异步阻塞:无阻塞 包括(异步IO)
各个IO Model的比较如果所示:
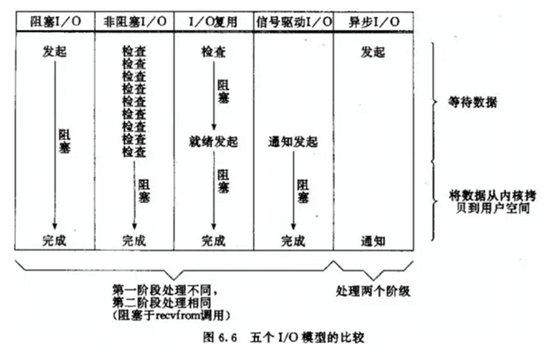
python--IO模块的更多相关文章
- [Python] io 模块之 open() 方法
io.open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True) 打开file ...
- python io 模块之 open() 方法(好久没写博客了)
io.open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True),打开file ...
- Python——IO多路复用之select模块epoll方法
Python——IO多路复用之select模块epoll方法 使用epoll方法实现IO多路复用,使用方法基本与poll方法一致,epoll效率要高于select和poll. .├── epoll_c ...
- Python——IO多路复用之select模块poll方法
Python——IO多路复用之select模块poll方法 使用poll方法实现IO多路复用 .├── poll_client.py├── poll_server.py└── settings.py ...
- Python——IO多路复用之select模块select方法
Python——IO多路复用之select模块select方法 使用select模块的select方法实现Python——IO多路复用 实现同时将终端输入的文本以及客户端传输的文本写入文本文件中: w ...
- Python之模块IO
目录 Python之模块IO io概叙 io类层次结构 io模块的类图 io模块的3种I/O 原始I/O,即RawIOBase及其子类 文本I/O,即TextIOBase及其子类 字节I/O(缓存I/ ...
- Python标准模块--threading
1 模块简介 threading模块在Python1.5.2中首次引入,是低级thread模块的一个增强版.threading模块让线程使用起来更加容易,允许程序同一时间运行多个操作. 不过请注意,P ...
- Python Logging模块的简单使用
前言 日志是非常重要的,最近有接触到这个,所以系统的看一下Python这个模块的用法.本文即为Logging模块的用法简介,主要参考文章为Python官方文档,链接见参考列表. 另外,Python的H ...
- Python标准模块--logging
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同 ...
- Day05 - Python 常用模块
1. 模块简介 模块就是一个保存了 Python 代码的文件.模块能定义函数,类和变量.模块里也能包含可执行的代码. 模块也是 Python 对象,具有随机的名字属性用来绑定或引用. 下例是个简单的模 ...
随机推荐
- wim命令删除后重新安装
个人原创博客,转载请注明,否则追究法律责任 2017-09-30-09:51:20 1,删除vim命令.模拟错误 [root@localhost ~]# which vim/usr/bin/vim[r ...
- 初识Selenium以及Selenium常用工具的简单介绍
一.为什么要学习自动化测试? 在互联网行业中敏捷开发小步快跑,快速迭代,测试环节中回归测试任务大繁琐,手工测试容易漏测,自动化测试可以提高测试效率保证产品质量. 二.学习的层次模型 1.单元自动化测试 ...
- 常用到的html页面布局和组件: 自己用
1. 用div当作圆 <div style="border: 1px solid blue;height: 100px; width: 100px; border-radius: 20 ...
- MYSQL数据库学习十四 存储过程和函数的操作
14.1 为什么使用存储过程和函数 一个完整的操作会包含多条SQL语句,在执行过程中需要根据前面SQL语句的执行结果有选择的执行后面的SQL语句. 存储过程和函数的优点: 允许标准组件式编程,提高了S ...
- 【openvpn】转载:烂泥:ubuntu 14.04搭建OpenVPN服务器
地址:http://www.cnblogs.com/ilanni/p/4681740.html (1)安装openVpn软件后.在openVpn的配置目录下添加配置文件: ca.crt client ...
- 【Flask】 WTForm表单编程
WTForm表单编程 在网页中,为了和用户进行信息交互总是不得不出现一些表单.flask设计了WTForm表单库来使flask可以更加简便地管理操作表单数据.WTForm中最重要的几个概念如下: Fo ...
- spring-boot-devtools
Create a new Maven Project and we have two class under the package com.example.demo like below scr ...
- linux挂载windows共享文件夹
1.建立共享文件夹 2.在linux中挂载共享目录 #mount -t cifs -o username=administrator,password=你的系统账号密码 //192.168.0.22/ ...
- C语言中数据类型的取值范围
C语言中数据类型的取值范围如下:char -128 ~ +127 (1 Byte)short -32767 ~ + 32768 (2 Bytes)unsigned short 0 ~ 65536 (2 ...
- Spring MVC的handlermapping之RequestMappingHandlerMapping初始化
RequestMappingHandlerMapping:这个handlerMapping是基于注解的同样,先上类图: 通过类图可以看到,同样是继承父类 AbstractHandlerMapping来 ...