Tomcat 对 HTTP 协议的实现(下)
在《Tomcat 对 HTTP 协议的实现(上)》一文中,对请求的解析进行了分析,接下来对 Tomcat 生成响应的设计和实现继续分析。本文首发于(微信公众号:顿悟源码)
一般 Servlet 生成响应的代码是这样的:
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
resp.setContentType("text/html");
resp.setCharacterEncoding("utf-8");
PrintWriter writer = resp.getWriter();
writer.println("<html><head><title>Demo</title></head>");
writer.println("<body><div>Hello World!</div></body>");
writer.println("</html>");
writer.flush();
writer.close();
}
像生成响应头和响应体并写入缓冲区,最后写入通道,这些都由 Tomcat 来做,来看下它是怎么设计的(可右键直接打开图片查看大图):
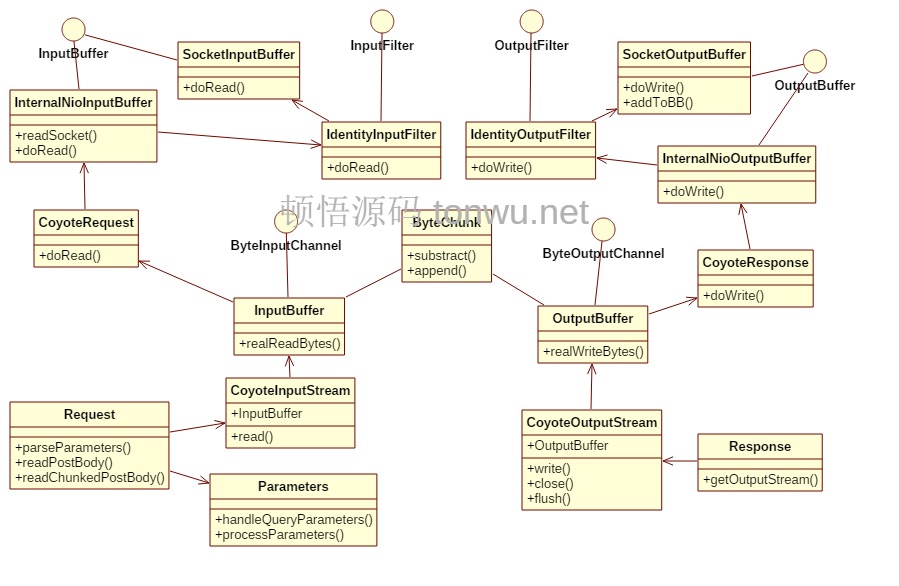
上图大部分类都是相对的,可与请求处理分析中的描述对比理解。重点还是理解 ByteChunk,它内部有一个 byte[] 数组引用,用于输入时,引用的 InternalNioInputBuffer 内的数组,表示一个字节序列的视图;用于输出时,会 new 一个可扩容的数组对象,存储响应体数据。
以上面的代码为例,分析一下,相关类的方法调用,上面的代码生成的是一种动态内容,会使用 chunked 传输编码:
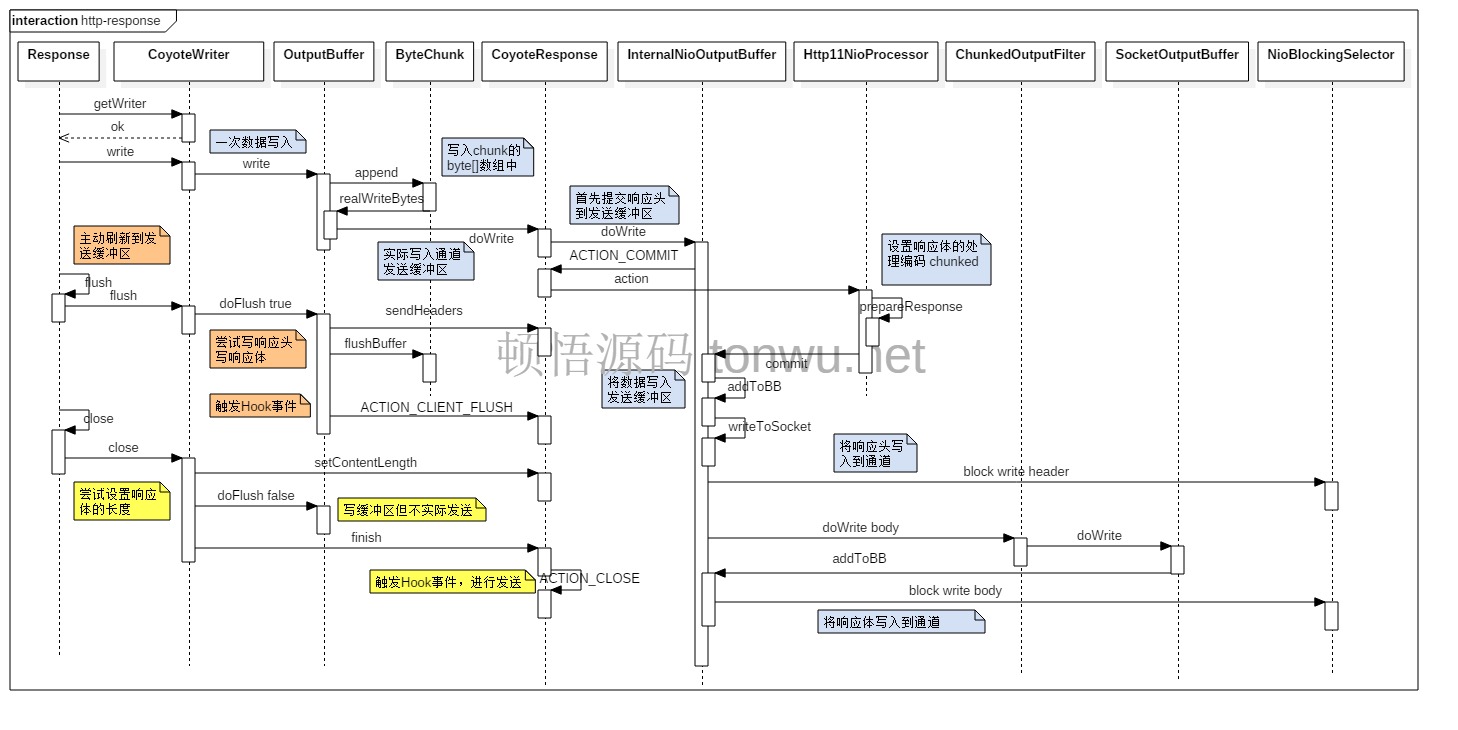
1. 存储响应体数据
调用图中,ByteChunk 调用 append 方法后,为了直观理解,就直接写入了发送缓冲区,真实情况不是这样,只有内部缓冲区满了,或者主动调用 flush、close 才会实际写入和发送,来看下 append 方法的代码:
public void append( byte src[], int off, int len )
throws IOException {
makeSpace( len ); // 扩容,高版本已去掉
// 写入长度超过最大容量,直接往底层数组写
// 如果底层数组也超了,会直接往通道写
if ( optimizedWrite && len == limit && end == start
&& out != null ) {
out.realWriteBytes( src, off, len );
return;
}
// 如果 len 小于剩余空间,直接写入
if( len <= limit - end ) {
System.arraycopy( src, off, buff, end, len );
end+=len;
return;
}
// 否则就循环把长 len 的数据写入下层的缓冲区
int avail=limit-end;
System.arraycopy(src, off, buff, end, avail);
end += avail;
// 把现有数据写入下层缓冲区
flushBuffer();
// 循环写入 len 长的数据
int remain = len - avail;
while (remain > (limit - end)) {
out.realWriteBytes( src, (off + len) - remain, limit - end );
remain = remain - (limit - end);
}
System.arraycopy(src, (off + len) - remain, buff, end, remain);
end += remain;
}
逻辑就是,首先写入自己的缓冲区,满了或不足使用 realWriteBytes 再写入下层的缓冲区中,下层的缓冲区实际就是 NioChannel 中的 WriteBuffer,写入之前首先会把响应头写入 InternalNioInputBuffer 内部的 HeaderBuffer,再提交到 WriteBuffer 中,接着就会调用响应的编码处理器写入响应体,编码处理通常有两种:identity 和 chunked。
2. identity 写入
当明确知道要响应资源的大小,比如一个css文件,并且调用了 resp.setContentLength(1) 方法时,就会使用 identity 写入指定长度的内容,核心代码就是 IdentityOutputFilter 的 doWrite 方法,这里不在贴出,唯一值得注意的是,它内部的 buffer 引用是 InternalNioInputBuffer 内部的 SocketOutputBuffer。
3. chunked 写入
当不确定长度时,会使用 chunked 传输编码,跟解析相反,就是要生成请求分析一文中介绍的 chunked 协议传输格式,写入逻辑如下:
public int doWrite(ByteChunk chunk, Response res)
throws IOException {
int result = chunk.getLength();
if (result <= 0) {
return 0;
}
// 生成 chunk-header
// 从7开始,是因为chunkLength后面两位已经是\r\n了
int pos = 7;
// 比如 489 -> 1e9 -> ['1','e','9'] -> [0x31,0x65,0x39]
// 生成 chunk-size 编码,将 int 转为16进制字符串的形式
int current = result;
while (current > 0) {
int digit = current % 16;
current = current / 16;
chunkLength[pos--] = HexUtils.HEX[digit];
}
chunkHeader.setBytes(chunkLength, pos + 1, 9 - pos);
// 写入 chunk-szie 包含 \r\n
buffer.doWrite(chunkHeader, res);
// 写入实际数据 chunk-data
buffer.doWrite(chunk, res);
chunkHeader.setBytes(chunkLength, 8, 2);
// 写入 \r\n
buffer.doWrite(chunkHeader, res);
return result;
}
所有数据块写入完成后,最后再写入一个大小为0的 chunk,格式为 0\r\n\r\n。至此整个写入完毕。
4. 阻塞写入通道
上层所有数据的实际写入,最后都是由 InternalNioInputBuffer 的 writeToSocket 方法完成,代码如下:
private synchronized int writeToSocket(ByteBuffer bytebuffer,
boolean block, boolean flip) throws IOException {
// 切换为读模式
if ( flip ) bytebuffer.flip();
int written = 0;// 写入的字节数
NioEndpoint.KeyAttachment att = (NioEndpoint.KeyAttachment)
socket.getAttachment(false);
if ( att == null ) throw new IOException("Key must be cancelled");
long writeTimeout = att.getTimeout();
Selector selector = null;
try { // 获取模拟阻塞使用的 Selector
// 通常是单例的 NioBlockingSelector
selector = getSelectorPool().get();
} catch ( IOException ignore ) { }
try {
// 阻塞写入
written = getSelectorPool().write(bytebuffer, socket, selector,
writeTimeout, block,lastWrite);
do {
if (socket.flush(true,selector,writeTimeout,lastWrite)) break;
}while ( true );
}finally {
if ( selector != null ) getSelectorPool().put(selector);
}
if ( block ) bytebuffer.clear(); //only clear
this.total = 0;
return written;
}
模拟阻塞的具体实现,已在 Tomcat 对 NIO 模型实现一文中介绍,这里不再赘述。
5. 缓冲区设计
缓冲区直接关系到内存使用的大小,还影响着垃圾收集。在整个HTTP处理过程中,总共有以下几种缓冲区:
- NioChannel 中的读写 ByteBuffer
- NioInputBuffer 和 NioOutputBuffer 内部使用的消息头字节数组
- ByteChunk 用于写入响应体时内部使用的字节数组
- 解析请求参数时,如果长度过小会使用内部缓存的一个 byte[] 数组,否则新建
以上缓冲区均可重复利用。
6. 小结
为了更好的理解HTTP的解析,尽可能的使用简洁的代码仿写了这部分功能。
源码地址:https://github.com/tonwu/rxtomcat 位于 rxtomcat-http 模块
Tomcat 对 HTTP 协议的实现(下)的更多相关文章
- tomcat配置https协议
tomcat配置https协议 1.找到本地jdk底下的bin目录,bin目录底下存在文件keytool.exe(在bin目录下空白处,按住shift右击,打开命令窗口,如下图) 2.在cmd的命令窗 ...
- 配置Tomcat使用https协议(配置SSL协议)
配置Tomcat使用https协议(配置SSL协议) 2014-01-20 16:38 58915人阅读 评论(3) 收藏 举报 转载地址:http://ln-ydc.iteye.com/blog/1 ...
- SMTP协议--在cmd下利用bat命令行发送邮件
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议 选择‘开始’-‘运行’,输入cmd,进入命令提示符窗口. Windows7默认没有开始Telnet服务,请在运 ...
- Tomcat配置https协议访问
Tomcat9配置https协议访问: https://blog.csdn.net/weixin_42273374/article/details/81010203 配置Tomcat使用https协议 ...
- tomcat中如何禁止列目录下的文件
tomcat中如何禁止列目录下的文件在{tomcat_home}/conf/web.xml中,把listings参数设置成false即可,如下: <servlet> <servlet ...
- tomcat在conf/Catalina/localhost目录下配置项目路径
转自:http://wangyl93-dl-cn.iteye.com/blog/1508517 在tomcat的conf/Catalina/localhost目录下配置项目路径,tomcat启动是会直 ...
- Tomcat 没有自动解压webapp下的war项目文件问题
默认选择的tomcat安装在了C盘下的C:\Program Files下 所以webapp文件也在C盘下 选择启动tomcat时 我选择了 bin下的 Tomcat.exe 显示成功启动 打开项目网站 ...
- 利用SSH协议在Windows下使用PuTTY连接Ubuntu
利用SSH协议在Windows下使用PuTTY连接Ubuntu Ubuntu部分 首先我们要为Ubuntu配置一下环境,让它支持ssh服务,我们要做的其实也很简单,就一下两步: 安装OpenSSH软件 ...
- SSL/TLS协议详解(下)——TLS握手协议
本文转载自SSL/TLS协议详解(下)--TLS握手协议 导语 在博客系列的第2部分中,对证书颁发机构进行了深入的讨论.在这篇文章中,将会探索整个SSL/TLS握手过程,在此之前,先简述下最后这块内容 ...
随机推荐
- BZOJ_2440_[中山市选2011]完全平方数_容斥原理+线性筛
BZOJ_2440_[中山市选2011]完全平方数_容斥原理 题意: 求第k个不是完全平方数倍数的数 分析: 二分答案,转化成1~x中不是完全平方数倍数的数的个数 答案=所有数-1个质数的平方的倍数+ ...
- [Usaco2009 Jan]安全路经Travel BZOJ1576 Dijkstra+树链剖分+线段树
分析: Dijkstra求最短路树,在最短路树上进行操作,详情可见上一篇博客:http://www.cnblogs.com/Winniechen/p/9042937.html 我觉得这个东西不压行写出 ...
- 在Jenkins中使用sonar进行静态代码检查
要解决的问题 jenkins自动构建完成后,希望能通过sonar静态代码检查生成一份报告,给与开发人员对当前代码的做一个质量评估和修改意见 1.安装并配置sonar服务器 懒得说,跟着官方文档走就行, ...
- C++ bitset用法
概念: bitset是用来存储位的(其中的元素只有两种形式) 这个类通常用来模拟一个布尔数组,但对空间分配上进行了优化:通常,每个元素只占用一个bit ,而通常char类型是它的八倍 每个位置上的位都 ...
- python环境下实现OrangePi Zero寄存器访问及GPIO控制
最近入手OrangePi Zero一块,程序上需要使用板子上自带的LED灯,在网上一查,不得不说OPi的支持跟树莓派无法相比.自己摸索了一下,实现简单的GPIO控制方法,作者的Zero安装的是Armb ...
- 同源策略 & 高效调试CORS实现
# 目录 为什么有同源策略? 需要解决的问题 CORS跨域请求方案 preflight withCredentials 附:高效.优雅地调试CORS实现 ----------------------- ...
- 购物网站首页(学习ING)
这几天在学着做购物网站,初步的完成了首页的框架吧,记录下.慢慢加强.主要难点,是样式的设置问题,如果自己想,自己摸索,可能会需要很长的调试.也是一个孰能生巧的过程吧,有些部分没有按照学习资料的方法也做 ...
- 阿里云卸载自带的JDK,安装JDK完成相关配置
0.预备工作 笔者的云服务器购买的是阿里云的轻量应用服务器,相比于云服务器ECS,轻量应用服务器是固定流量但是网络带宽较高,对于服务器来说,网络带宽是非常昂贵的,而带宽也决定了你的应用访问的流畅度,带 ...
- 在已有的Asp.net MVC项目中引入Taurus.MVC
Taurus.MVC是一个优秀的框架,如果要应用到已有的Asp.net MVC项目中,需要修改一下. 1.前提约定: 走Taurus.MVC必须指定后缀.如.api 2.原项目修改如下: web.co ...
- .Net 特性 attribute 学习 ----自定义特性
什么是特性? [Obsolete("不要用无参构造函数",true)] 放在方式上, 该方法就不能使用了 [Serializable]放在类上面.该类就是可以序列化和反序列化使用 ...