《大数据日知录》读书笔记-ch3大数据常用的算法与数据结构
布隆过滤器(bloom filter,BF):
二进制向量数据结构,时空效率很好,尤其是空间效率极高。作用:检测某个元素在某个巨量集合中存在。
构造:

查询:

不会发生漏判(false negative),但误判(false positive)存在,因此BF适合允许少量误判的场景。

计数布隆过滤器(counting bloom filter,CBF):
BF基础上支持删除元素操作。数组每个位置1bit扩展为n bits。

另外需要考虑计数溢出问题。
BF应用:
Chrome浏览器判断恶意url;爬虫对爬过的url判重;数据库领域用BF加速join过程等。
BigTable中BF用作提升读效率:在SSTable中查找key。额外增加一次读实际文件操作避免误判。Cassandra也借鉴此法。Google流式系统MillWheel保证记录“恰好送达一次”语义时检测重复记录使用此法。
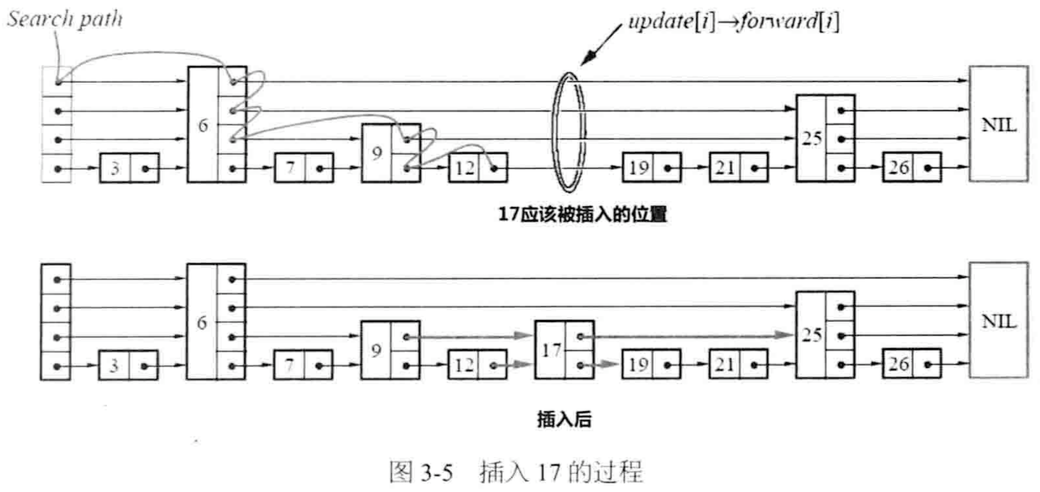
SkipList:
增删改查时间复杂度O(log(n))

LSM树(Log-Structured Merge tree):
将大量的随机写换成批量顺序写,极大提升磁盘数据写入速度。代价是降低读效率,可用BF补偿。
以LevelDB实现为例。

log文件用于系统崩溃恢复:

MemTable满时转换为Immutable MemTable,经Compaction导出为SSTable:


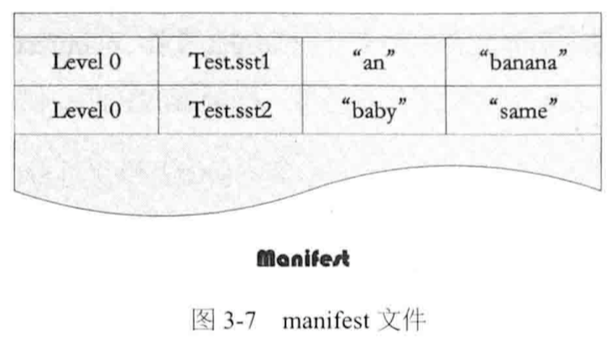
manifest文件:

Current文件:

Compation操作:

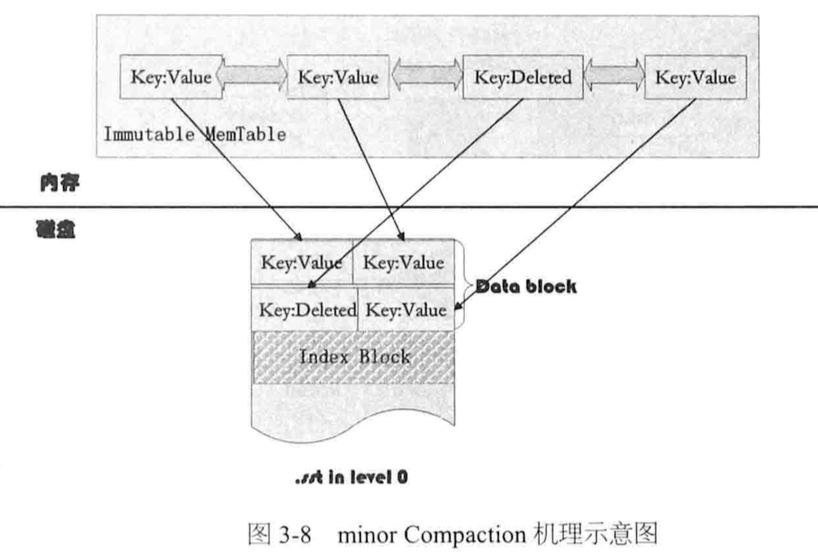
minor Compaction:

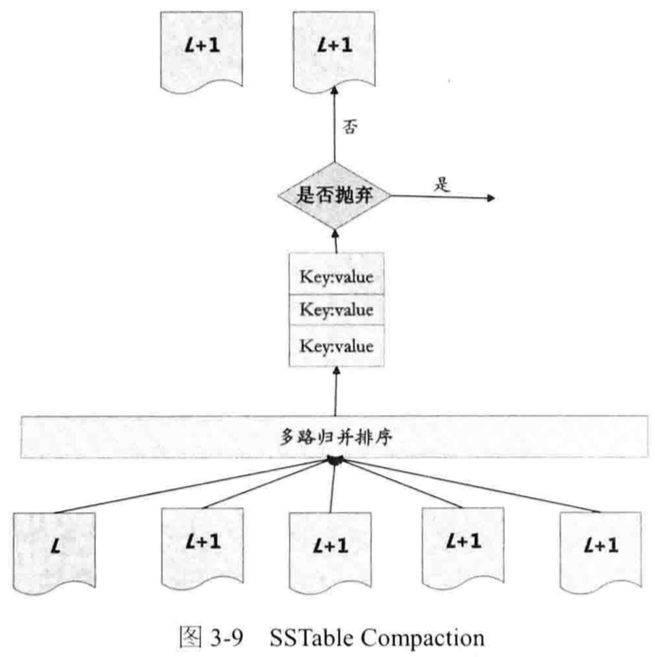
major Compaction:
选择Level:某Level下的SSTable文件数超过设定后,合并此Level和Level+1的SSTable

选择待合并文件:

合并过程:
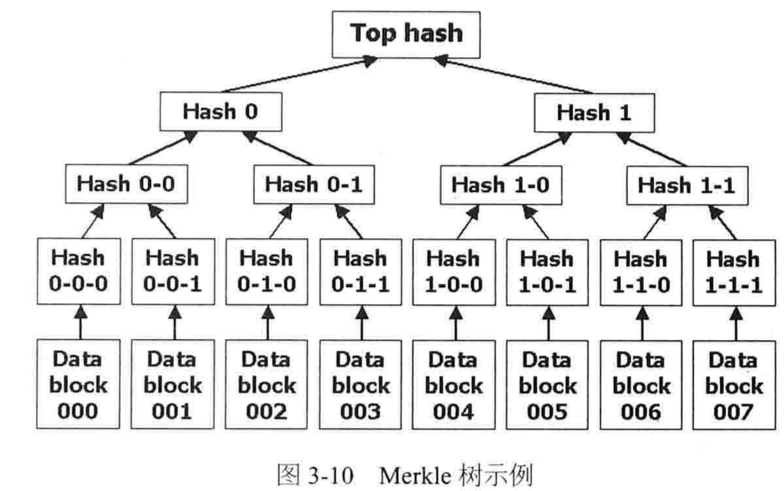
Merkle Hash树(Merkle Hash Tree)
用于定位数据变化(损毁、篡改、正常修改)

Snappy与LZSS算法:
应用:BigTable,MapReduce,RPC,Hadoop,HBase,Cassandra,Avro等
压缩/解压缩:用时间换空间;Snappy追求高压缩/解压缩速度
LZ77优化得到LZSS,Snappy基于LZSS

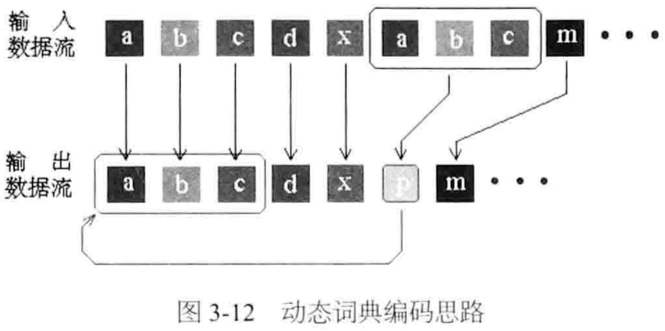
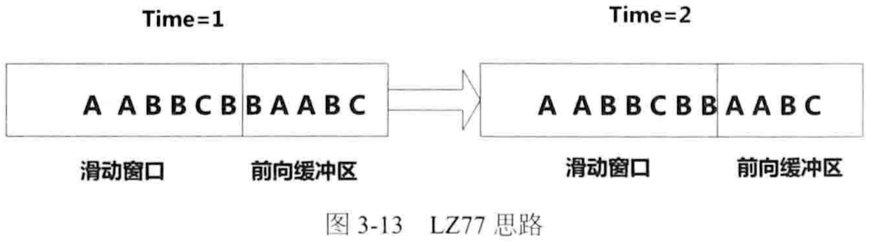
LZSS改进LZ77:字符串小于最小匹配长度不压缩

Snappy改进LZSS:设定最小匹配长度=4,hash表内字符串片段固定长度=4,数据切割成32KB的块,滑动窗口每次后移4
Cuckoo Hashing:
解决hash冲突(collisions)问题,O(1)时间删、查,O(c)时间增。空间利用率50%。


Cuckoo Hashing应用:SILT存储系统(Partial Key Cuckoo Hashing,SILT hashing)
内存建立外存数据的索引。

疑问地方应该是:读出h_1(x)的内容并用其值(即b)替换掉哈希空间位置b的内容,即用b替换掉位置b原先的内容。


| BigTable | MillWheel | LevelDB | Redis | Lucene | SILT | RAMCloud | Cassandra | BitTorrent | Git | Dynamo | Riak | Cassandra | |
| 介绍 | flash memory | Amazon,NoSQL | 模仿Dynamo | NoSQL | |||||||||
| 算法 | bloom filter | bloom filter | SkipList | SkipList | SkipList | LSM tree | LSM tree | LSM tree | Merkle tree | Merkle tree | Merkle tree | Merkle tree | Merkle tree |
| LSM tree | LSM tree | partial key cuckoo hashing | Gossip |
《大数据日知录》读书笔记-ch3大数据常用的算法与数据结构的更多相关文章
- 一. 数据分片和路由 <<大数据日知录>> 读书笔记
本章主要讲解大数据下如何做数据分片,所谓分片,即将大量数据分散在不同的节点,同时每个存储节点还要做副本备份. 而一般的抽象分片方法是, 先将数据映射到一个分片空间,这是多对一的关系,即一个数据分片区间 ...
- 二. 大数据常用的算法和数据结构 <<大数据日知录>> 读书笔记
基本上是hash实用的各种举例 布隆过滤器 Bloom Filter 常用来检测某个原色是否是巨量数据集合中的成员,优势是节省空间,不会有漏判(已经存在的数据肯定能够查找到),缺点是有误判(不存在的数 ...
- 读<大数据日知录:架构与算法>有感
前一段时间, 一个老师建议我能够学学 '大数据' 和 '机器学习', 他说这必定是今后的热点, 学会了, 你就是香饽饽.在此之前, 我对大数据, 机器学习并没有非常深的认识, 总觉得它们是那么的缥缈, ...
- 《大数据日知录》读书笔记-ch2数据复制与一致性
CAP理论:Consistency,Availability,Partition tolerance 对于一个分布式数据系统,CAP三要素不可兼得,至多实现其二.要么AP,要么CP,不存在CAP.分布 ...
- 《大数据日知录》读书笔记-ch1数据分片与路由
目前主流大数据存储使用横向扩展(scale out)而非传统数据库纵向扩展(scale up)的方式.因此涉及数据分片.数据路由(routing).数据一致性问题 二级映射关系:key-partiti ...
- 《大数据日知录》读书笔记-ch16机器学习:分布式算法
计算广告:逻辑回归 千次展示收益eCPM(Effective Cost Per Mille) eCPM= CTR * BidPrice 优化算法 训练数据使用:在线学习(online learning ...
- 《大数据日知录》读书笔记-ch15机器学习:范型与架构
机器学习算法特点:迭代运算 损失函数最小化训练过程中,在巨大参数空间中迭代寻找最优解 比如:主题模型.回归.矩阵分解.SVM.深度学习 分布式机器学习的挑战: - 网络通信效率 - 不同节点执行速度不 ...
- 《大数据日知录》读书笔记-ch11大规模批处理系统
MapReduce: 计算模型: 实例1:单词统计 实例2:链接反转 实例3:页面点击统计 系统架构: 在Map阶段还可以执行可选的Combiner操作,类似于Reduce,但是在Mapper sid ...
- [转载] leveldb日知录
原文: http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html 对leveldb非常好的一篇学习总结文章 郑重声明:本篇博客是自己学 ...
随机推荐
- CSS中的三种基本的定位机制(普通流、定位、浮动)
一.普通流 普通流中元素框的位置由元素在XHTML中的位置决定.块级元素从上到下依次排列,框之间的垂直距离由框的垂直margin计算得到.行内元素在一行中水平布置. 普通流就是html文档中的元素如块 ...
- access函数使用
调用open函数时,是以有效用户而不是实际用户的身份去验证进程对要打开的文件的读写权限.但是有时候我们想知道的是实际用户而非有效用户对某一文件的权限,此时就要用到access函数. 函数原型:in ...
- xml构建
<a target="_blank" href="http://wpa.qq.com/msgrd?v=3&uin=346252320&site=qq ...
- 查看linux ssh服务信息及运行状态
关于ssh服务端配置有不少文章,例如 linux下ssh服务配置,这里仅列举出一些查看ssh服务相关信息的常用命令. rpm -qa | grep ssh 可以看到系统中ssh安装包 rpm -ql ...
- Open Interface Service WCF三种通信模式
WCF三种通信模式 一.请求响应模式: 概念:客户端发送请求,一直等待服务端响应,在此期间处于等待(假死)状态:直到服务器响应,才能继续执行其他的操作: 即使返回值是void 也属于请求与答复模式. ...
- 8 个用于生产环境的 SQL 查询优化调整
在没有数据仓库或单独的分析数据库的组织中,报告的唯一来源和最新的数据可能是在现场生产数据库中. 在查询生产数据库时,优化是关键.一个低效的查询可能会对生产数据库产生大量的资源消耗,如果查询有错误会引发 ...
- 语法解析 rs.next()
ResultSet.next()方法将指针从当前位置下移一行.ResultSet 指针最初位于第一行之前:第一次调用 next 方法使第一行成为当前行:第二次调用使第二行成为当前行,依此类推. 如果新 ...
- [Maven实战-许晓斌]-[第二章]-2.3安装目录分析
bin boot conf settings.xml非常重要 这个是maven安装包自带的settings.xml 通常我们会放在习惯路径,C:\Users\admin\.m2\下面 即 用户路径\ ...
- linux的档案权限和目录配置
Linux一般将档案可存取的身份分为三个类别,分别是 owner/group/others /etc/passwd 账号信息 /etc/shadow 个人密码 /etc/group 组名记录 ...
- is 与 == 的区别;小数据池; 编码与解码
1, is 与 == 的区别 == 比较的是两边的值 is 比较的是两边的地址 id () 2,小数据池(在终端中) 数字小数据池的范围 -5 ~ 256 字符串中如果有特殊字符他们的内存地址 ...