机器学习-kNN-数据归一化
一、为什么需要数据归一化
不同数据之间因为单位不同,导致数值差距十分大,容易导致预测结果被某项数据主导,所以需要进行数据的归一化。
解决方案:将所有数据映射到同一尺度
二、最值归一化 normalization
最值归一化:把所有数据映射到0-1之间
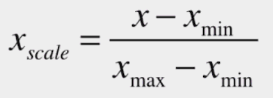
适用于分布有明显边界的情况;受outlier影响较大
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0,100,100)
# 一维矩阵的最值归一化
print((x - np.min(x)) / (np.max(x) - np.min(x))) #最值归一化
# 二维矩阵中分别对每列进行最值归一化
x = np.random.randint(0,100,(50,2))
x = np.array(x,dtype=float)
x[:,0] = (x[:,0] - np.min(x[:,0])) / (np.max(x[:,0]) - np.min(x[:,0]))
x[:,1] = (x[:,1] - np.min(x[:,1])) / (np.max(x[:,1]) - np.min(x[:,1]))
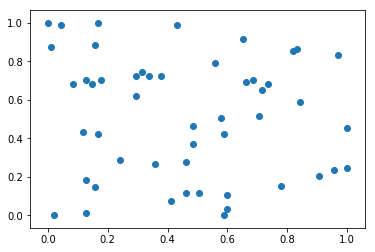
# 绘制散点图
plt.scatter(x[:,0],x[:,1])
plt.show()
# 第0列的均值和方差
print(np.mean(x[:,0]))
print(np.std(x[:,0]))
# 第1列的均值和方差
print(np.mean(x[:,1]))
print(np.std(x[:,1]))
输出结果:
[0.37373737 0.77777778 0.47474747 0.17171717 0.82828283 0.13131313
0.66666667 1. 0.73737374 0.26262626 0.3030303 0.88888889
0.85858586 0.80808081 0.92929293 0.64646465 0.97979798 0.16161616
0.7979798 0.64646465 0.95959596 0.29292929 0.90909091 0.8989899
0.29292929 0.62626263 0.65656566 0.35353535 0.85858586 0.8989899
0.03030303 0.76767677 0.75757576 0.8989899 0.26262626 0.82828283
0.72727273 0.77777778 0.16161616 0.18181818 0.81818182 0.19191919
0.11111111 0.90909091 0.17171717 0.04040404 0.52525253 0.
0.34343434 0.88888889 0.07070707 0.82828283 0.01010101 0.63636364
0.56565657 0.1010101 0.05050505 0.15151515 0.91919192 0.03030303
0.96969697 0.26262626 0.06060606 0.06060606 0.66666667 0.74747475
0.14141414 0.64646465 0.77777778 0.90909091 0.47474747 0.72727273
0.96969697 0.76767677 0.23232323 0.26262626 0.54545455 0.41414141
0.11111111 0.38383838 0.66666667 0.12121212 0.64646465 0.27272727
0.21212121 0.21212121 0.84848485 0.71717172 0.5959596 0.56565657
0.07070707 0.77777778 0.95959596 0.90909091 0.42424242 0.
0.94949495 0.95959596 0.41414141 0.68686869]
0.4574736842105262
0.29314011096016795
0.5129896907216495
0.3081736973516696
三、均值方差归一化 standardization
均值方差归一化:把所有数据归一到均值为0方差为1的分布中
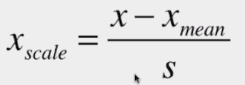
适用于数据分布没有明显的边界,有可能存在极端数据值
import numpy as np
import matplotlib.pyplot as plt
# 二维矩阵中分别对每列进行均值方差归一化
x2 = np.random.randint(0,100,(50,2))
x2 = np.array(x2,dtype=float)
x2[:,0] = (x2[:,0] - np.mean(x2[:,0])) / np.std(x2[:,0])
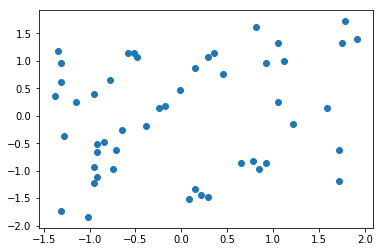
x2[:,1] = (x2[:,1] - np.mean(x2[:,1])) / np.std(x2[:,1])
plt.scatter(x2[:,0],x2[:,1])
plt.show()
#打印对应列的均值和方差
print(np.mean(x2[:,0]))
print(np.std(x2[:,0]))
print(np.mean(x2[:,1]))
print(np.std(x2[:,1]))
运行结果:
7.348288644237755e-17
1.0
8.104628079763643e-17
0.9999999999999999
四、对测试数据进行归一化
利用scikit-learn中的StandardScaler对数据进行均值方差归一化演示:
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
#创建训练数据集和测试数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state = 666)
from sklearn.preprocessing import StandardScaler
# 构造均值方差归一化对象
standardScaler = StandardScaler()
# 把自身返回回来,现在standardScaler中存放了计算均值方差归一化的关键信息
standardScaler.fit(x_train)
# 均值
print('训练数据均值:',standardScaler.mean_ )
# 描述数据分布范围 包括:方差 标准差等
print('训练数据方差:',standardScaler.scale_)
# 对训练数据进行归一化处理
x_train = standardScaler.transform(x_train)
# 对测试数据进行归一化处理,并赋值给 x_test_standard
x_test_standard = standardScaler.transform(x_test)
from sklearn.neighbors import KNeighborsClassifier
# 创建一个kNN分类器
knn_clf = KNeighborsClassifier(n_neighbors=3)
# 将均值方差归一化后的数据进行写入
knn_clf.fit(x_train,y_train)
# 计算分类器准确度
print("测试数据经过均值方差归一化后 准确度:",knn_clf.score(x_test_standard,y_test))
# 测试数据集没有进行归一化处理
print("测试数据未经过均值方差归一化后 准确度:",knn_clf.score(x_test,y_test))
运行结果:
训练数据均值: [5.83416667 3.0825 3.70916667 1.16916667]
训练数据方差: [0.81019502 0.44076874 1.76295187 0.75429833]
测试数据经过均值方差归一化后 准确度: 1.0
测试数据未经过均值方差归一化后 准确度: 0.3333333333333333
机器学习-kNN-数据归一化的更多相关文章
- 机器学习:数据归一化(Scaler)
数据归一化(Feature Scaling) 一.为什么要进行数据归一化 原则:样本的所有特征,在特征空间中,对样本的距离产生的影响是同级的: 问题:特征数字化后,由于取值大小不同,造成特征空间中样本 ...
- 第四十九篇 入门机器学习——数据归一化(Feature Scaling)
No.1. 数据归一化的目的 数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用. No.2. 数据归一化的方法 数据归一化的方法主要 ...
- 数据归一化Scaler-机器学习算法
//2019.08.03下午#机器学习算法的数据归一化(feature scaling)1.数据归一化的必要性:对于机器学习算法的基础训练数据,由于数据类型的不同,其单位及其量纲也是不一样的,而也正是 ...
- 机器学习PAL数据预处理
机器学习PAL数据预处理 本文介绍如何对原始数据进行数据预处理,得到模型训练集和模型预测集. 前提条件 完成数据准备,详情请参见准备数据. 操作步骤 登录PAI控制台. 在左侧导航栏,选择模型开发和训 ...
- 数据处理:2.异常值处理 & 数据归一化 & 数据连续属性离散化
1.异常值分析 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 异常值分析 → 3σ原则 / 箱型图分析异常值处理方法 → 删除 / 修正填补 ...
- matlab将矩阵数据归一化到[0,255]
matlab将矩阵数据归一化到[0,255] function OutImg = Normalize(InImg) ymax=255;ymin=0; xmax = max(max(InImg) ...
- 数据归一化Feature Scaling
数据归一化Feature Scaling 当我们有如上样本时,若采用常规算欧拉距离的方法sqrt((5-1)2+(200-100)2), 样本间的距离被‘发现时间’所主导.尽管5是1的5倍,200只是 ...
- R学习:《机器学习与数据科学基于R的统计学习方法》中文PDF+代码
当前,机器学习和数据科学都是很重要和热门的相关学科,需要深入地研究学习才能精通. <机器学习与数据科学基于R的统计学习方法>试图指导读者掌握如何完成涉及机器学习的数据科学项目.为数据科学家 ...
- MATLAB实例:聚类初始化方法与数据归一化方法
MATLAB实例:聚类初始化方法与数据归一化方法 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. 聚类初始化方法:init_methods.m f ...
随机推荐
- 【Biocode】产生三行的seq+01序列
代码说明: sequence.txt与site.txt整合 如下图: sequence.txt: site.txt: 整理之后如下: 蛋白质序列中发生翻译后修饰的位置标记为“1”,其他的位置标记为“0 ...
- TeamCity编译执行selenium上传窗口脚本缺陷
2015-07-04 18:05 编写本文 TeamCity编译selenium脚本,对于上传窗口处理只支持sendKeys的使用,不支持模拟人为按下Enter键和使用autoIt等操作,即使本地调试 ...
- 怎么用JavaScript实现tab切换
先看一下代码实现后的最终效果: 用JavaScript实现思路很简单,就是先把所有的内容隐藏,点击标题对应的内容显示, css代码如下: <style type="text/css&q ...
- es6中对象转数组,转map
//对象转数组let array = Object.keys(userPermission).map(key=> userPermission[key]) console.log(array) ...
- java 父类的引用调用自己的属性 但是调用的方法必须是重写过的父类的方法 因为编译时候把他当作父类 运行时候才是他自己 所以必须重写父类得方法
- 2月4日 考试——迟到的 ACX
迟到的 ACX 时限:1s 内存限制:128MB题目描述: 今天长沙下雪了,小 ACX 在上学路上欣赏雪景,导致上学迟到,愤怒的佘总给 ACX 巨佬出了一个题目想考考他,现在他找到你,希望你能帮帮他. ...
- Qt 事件处理机制
Qt 事件处理机制 因为这篇文章写得特别好,将Qt的事件处理机制能够阐述的清晰有条理,并且便于学习.于是就装载过来了(本文做了排版,并删减了一些冗余的东西,希望原主勿怪),以供学习之用. 简介 在Qt ...
- 转:评估指标MAP
转:http://www.zhenv5.com/?p=1079 MAP可以由它的三个部分来理解:P,AP,MAP 先说P(Precision)精度,正确率.在信息检索领域用的比较多,和正确率一块出现的 ...
- 【MVVM Dev】多个具有依赖性质的ComboBox对数据的过滤
一.前言 在界面编程中,我们常常会遇到具有依赖性质的ComboBox框,比如最常见的: 省/直辖市 => 地级市/区 => 区/街道 今天就说一下在WPF的MVVM模式中如何实现该功能 二 ...
- NOI2013 矩阵游戏 【数论】
题目描述 婷婷是个喜欢矩阵的小朋友,有一天她想用电脑生成一个巨大的n行m列的矩阵(你不用担心她如何存储).她生成的这个矩阵满足一个神奇的性质:若用F[i][j]来表示矩阵中第i行第j列的元素,则F[i ...