在Spark程序中使用压缩
当大片连续区域进行数据存储并且存储区域中数据重复性高的状况下,数据适合进行压缩。数组或者对象序列化后的数据块可以考虑压缩。所以序列化后的数据可以压缩,使数据紧缩,减少空间开销。
1. Spark对压缩方式的选择
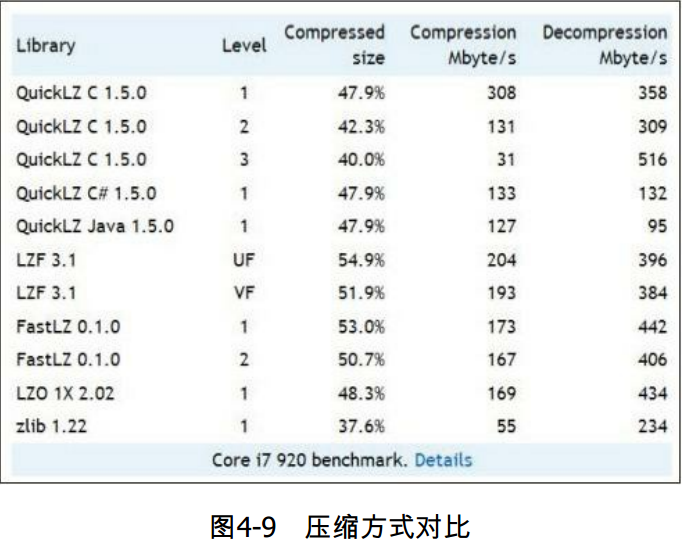
压缩采用了两种算法:Snappy和LZF,底层分别采用了两个第三方库实现,同时可以自定义其他压缩库对Spark进行扩展。Snappy提供了更高的压缩速度,LZF提供了更高的压缩比,用户可以根据具体需求选择压缩方式。
压缩格式及解编码器如下。
·LZF:org.apache.spark.io.LZFCompressionCodec。
·Snappy:org.apache.spark.io.SnappyCompressionCodec。
压缩算法的对比,如图4-9所示。
(1)Ning-Compress
Ning-compress是一个对数据进行LZF格式压缩和解压缩的库,这个库是TatuSaloranta(tatu.saloranta@iki .fi)书写的。用户可以在Github地址:https://github.com/ning/compress下载,进行学习和研究。
(2)snappy-java
Snappy算法的前身是Zippy,被Google用于MapReduce、BigTable等许多内部项目。snappy-java由谷歌开发,是以C++开发的Snappy压缩解压缩库的Java分支。Github地址为:https://github.com/xerial /snappy-java。
Snappy的目标是在合理的压缩量情况下,提供高压缩速度的库。因此Snappy的压缩比和LZF差不多,并不是很高。根据数据集的不同,压缩比能达到20%~100%。有兴趣的读者可以看一个压缩算法Benchmark,它对基于JVM运行语言的压缩库进行对比。这个Benchmark对snappy-java和其他压缩工具LZO-java/LZF/Qui ckLZ/Gzip/Bzip2进行了比较。地址为Github:https://github.com/ning/jvm-compressor-benchmark/wiki。这个Benchmark是由Tatu Saloranta@cotowncoder开发的。Snappy通常在达到相当压缩的情况下,要比同类的LZO、LZF、FastLZ和Qui ckLZ等快速的压缩算法快。它对纯文本的压缩比大概是1.5~1.7x,对HTML网页是2~4x,对图片等二进制数据基本没有压缩,为1x。Snappy分别对64位和32位处理器进行了优化,不论是32位处理,还是64位处理器,都能达到很高的效率。据官方介绍,Snappy经过PB级别的大数据的考验,稳定性方面没有问题,Google的map reduce、rpc等很多框架都用到了Snappy压缩算法。
压缩是在时间和空间上的一种权衡。更长的压缩和解压缩时间会节省更多的空间。而空间占用少意味着可以缓存更多的数据,节省I/O时间和网络传输时间。不同的压缩算法是在不同情境的一种权衡,而且对不同数据类型文件进行压缩又会产生差异。可以参考图4-9,对不同算法的使用进行权衡。
2. 在Spark程序中使用压缩
用户可以通过下面两种方式配置压缩。
(1)在Spark-env.sh文件中配置
用户可以在启动前配置文件spark-env.sh设定压缩配置的参数。
export SPARK_JAVA_OPTS="-Dspark.broadcast.compress"
(2)在应用程序中配置
sc是SparkContext对象,conf是SparkConf对象。
val conf=sc.getConf
1)获取压缩的配置。
conf.getBoolean("spark.broadcast.compress",true)
2)压缩的配置。
conf.set("spark.broadcast.compress",true)
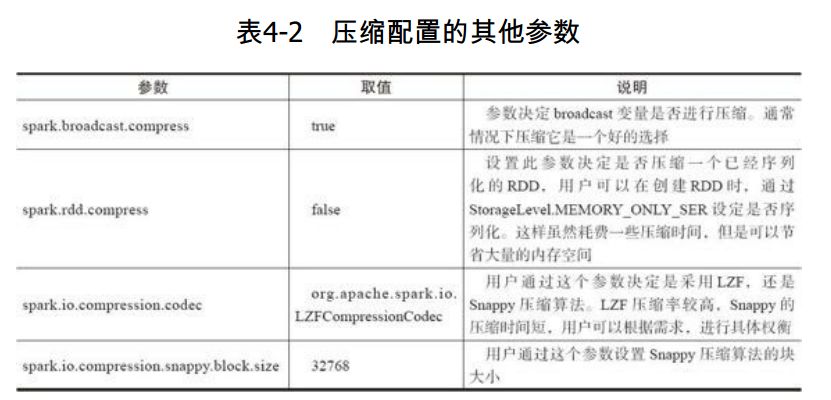
其他参数如表4-2所示:
在分布式计算中,序列化和压缩是两个重要的手段。Spark通过序列化将链式分布的数据转化为连续分布的数据,这样就能够进行分布式的进程间数据通信,或者在内存进行数据压缩等操作,提升Spark的应用性能。通过压缩,能够减少数据的内存占用,以及IO和网络数据传输开销。
在Spark程序中使用压缩的更多相关文章
- [Spark性能调优] 第四章 : Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified Mem ...
- Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified M ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- 程序中使用7-zip(7z)压缩文件
Email:longsu2010 at yeah dot net 工作中难免遇到需要压缩文件的情况,比如有一千万个小文件,每个文件约100k,如果使用7-zip压缩后可能十几k,可以节省很多磁盘空间. ...
- IntelliJ IDEA在Local模式下Spark程序消除日志中INFO输出
在使用Intellij IDEA,local模式下运行Spark程序时,会在Run窗口打印出很多INFO信息,辅助信息太多可能会将有用的信息掩盖掉.如下所示 要解决这个问题,主要是要正确设置好log4 ...
- 在编译器中调试spark程序处理
在IDEA中调试spark程序会报错 18/05/16 07:33:51 WARN NativeCodeLoader: Unable to load native-hadoop library for ...
- Guava com.google.common.base.Stopwatch Spark程序在yarn中 MethodNotFound
今天在公司提交一个Spark 读取hive中的数据,写入JanusGraph 的app,自己本地调试没有问题,放入环境中提交到yarn 中时,发现app 跑不起. yarn 中日志,也比较明显,app ...
- 在IntelliJ IDEA中创建和运行java/scala/spark程序
本文将分两部分来介绍如何在IntelliJ IDEA中运行Java/Scala/Spark程序: 基本概念介绍 在IntelliJ IDEA中创建和运行java/scala/spark程序 基本概念介 ...
随机推荐
- Delphi idHttpServer接收Http Get请求解码问题
引用 Httpapp单元,使用Httpdecode函数进行解码 procedure TFrmMain.HTTPServerCommandGet(AThread: TIdPeerThread; AReq ...
- Loadrunner中cookie解释与用法
loadrunner对于cookie的处理loadrunner中与cookie处理相关的常用函数如下: web_add_cookie():添加新的cookie或者修改已经存在的cookie web_r ...
- Redis 在Centos7下配置开机自启动
设置Redis开机启动需要如下几个步骤: 编写配置脚本 [ vim /etc/init.d/redis ] #!/bin/sh # # Simple Redis init.d script conce ...
- 尝试php命令行脚本多进程并发执行
php不支持多线程,但是我们可以把问题转换成“多进程”来解决.由于php中的pcntl_fork只有unix平台才可以使用,所以本文尝试使用popen来替代. 下面是一个例子: 被并行调用的子程序 ...
- NOIP2012 D2 T2借教室
先上题目 题目描述 在大学期间,经常需要租借教室.大到院系举办活动,小到学习小组自习讨论,都需要向学校申请借教室.教室的大小功能不同,借教室人的身份不同,借教室的手续也不一样. 面对海量租借教室的信息 ...
- mySQL 的 2个分类
1.将如下表中的每门成绩都大于80分的人名? 张三 语文 81 张三 数学 75 李四 语文 76 李四 数学 90 王五 语文 81 王五 数学 100 王五 英语 90 select * from ...
- Python开发基础-Day32 进程间通信、进程池、协程
进程间通信 进程彼此之间互相隔离,要实现进程间通信(IPC),multiprocessing模块支持两种形式:队列和管道,这两种方式都是使用消息传递的. 进程队列queue 不同于线程queue,进程 ...
- 【BZOJ 2595】2595: [Wc2008]游览计划 (状压DP+spfa,斯坦纳树?)
2595: [Wc2008]游览计划 Time Limit: 10 Sec Memory Limit: 256 MBSec Special JudgeSubmit: 1572 Solved: 7 ...
- 【BZOJ 2749】 2749: [HAOI2012]外星人 (数论-线性筛?类积性函数)
2749: [HAOI2012]外星人 Description Input Output 输出test行,每行一个整数,表示答案. Sample Input 1 2 2 2 3 1 Sample Ou ...
- [待码][BZOJ1858]SCOI2010序列操作 jzyzoj1655
待码的线段树.....太长了看上去不是很想写 [ 什么破理由啊摔,不要脸 ] 嗯先水几道再写