python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言
作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始。
一、分析观察爬取网站结构
这里以广州链家二手房为例:http://gz.lianjia.com/ershoufang/
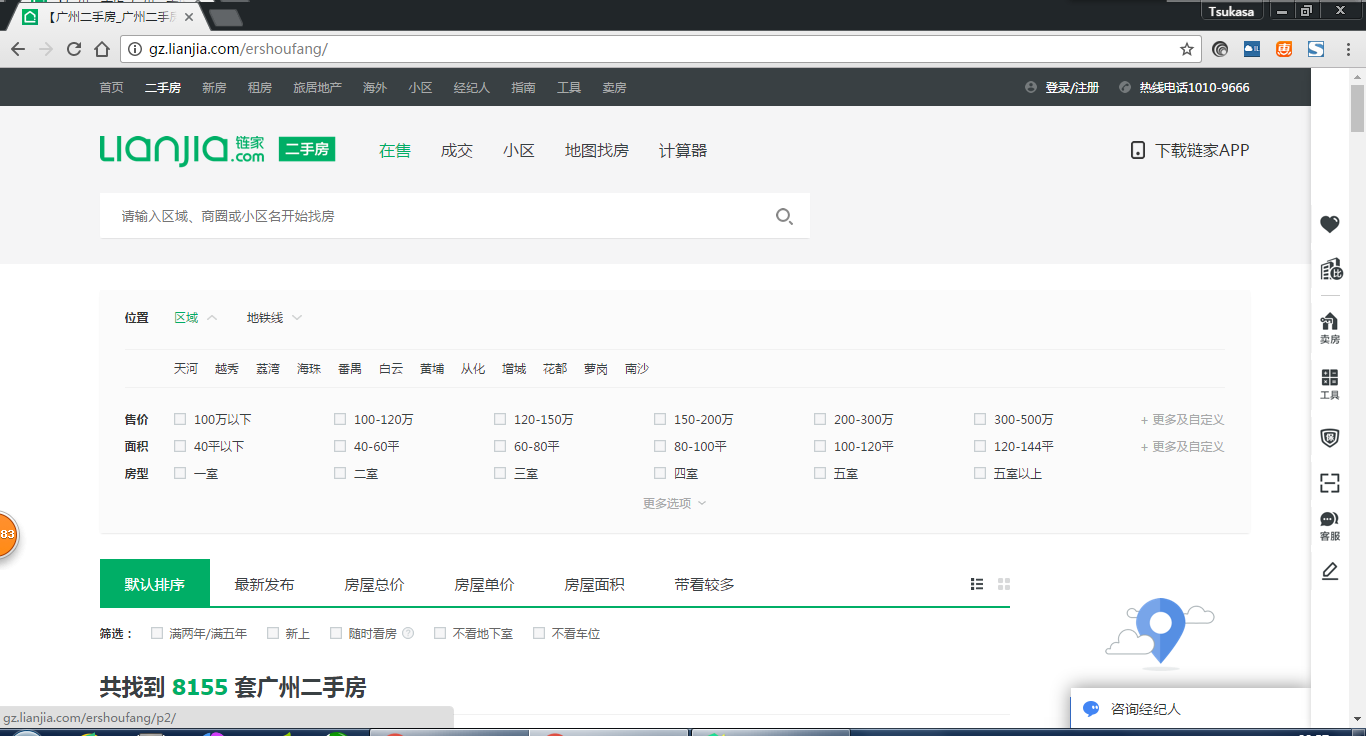
这是第一页,我们看看第二页的url会有什么变化 发现多出来一个/g2,第三页/pg3,那么原始的是不是就是增加/pg1呢,我们测试一下http://gz.lianjia.com/ershoufang/pg1/ == http://gz.lianjia.com/ershoufang/那么问题不大,我们继续分析。
发现多出来一个/g2,第三页/pg3,那么原始的是不是就是增加/pg1呢,我们测试一下http://gz.lianjia.com/ershoufang/pg1/ == http://gz.lianjia.com/ershoufang/那么问题不大,我们继续分析。

这些就是我们想得到的二手房资讯,但是这个是有链接可以点进去的,我们看看:
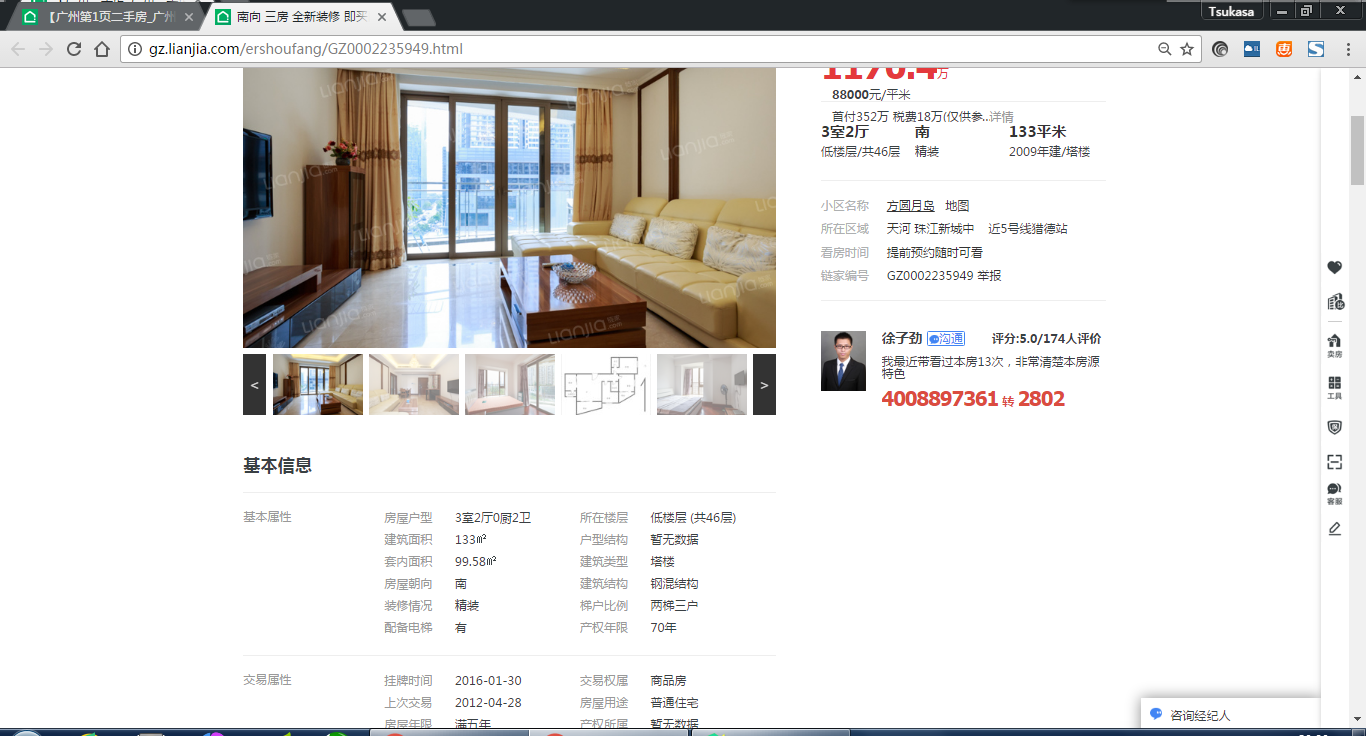
里面的二手房资讯更加全面,那我是想得到这个网页里面的资讯了。
二、编写爬虫
1.得到url
我们先可以得到全部详细的链接,这里有100页,那么我们可以http://gz.lianjia.com/ershoufang/pg1/.../pg2.../pg3.../pg100 先生成全部url,再从这些url得到每一页里面详细的url,再从详细的url分析html得到我想要的资讯。

2.分析 htmlhttp://gz.lianjia.com/ershoufang/pg1/
先打开chrom自带的开发者工具分析里面的network ,把preserve log
,把preserve log 勾上,清空
勾上,清空 ,然后我们刷新一下网页。
,然后我们刷新一下网页。

发现get:http://gz.lianjia.com/ershoufang/pg1/请求到的html
那么我们就可以开始生成全部url先了:
def generate_allurl(user_in_nub):
url = 'http://gz.lianjia.com/ershoufang/pg{}/'
for url_next in range(1,int(user_in_nub)):
yield url.format(url_next) def main():
user_in_nub = input('输入生成页数:')
for i in generate_allurl(user_in_nub):
print(i) if __name__ == '__main__':
main()
运行结果: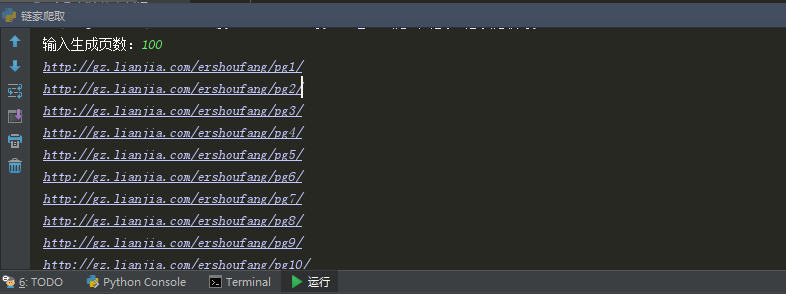
这样我们就生成了100页的url
然后我们就要分析这些url里面的详细每一页的url:
先分析网页结构,
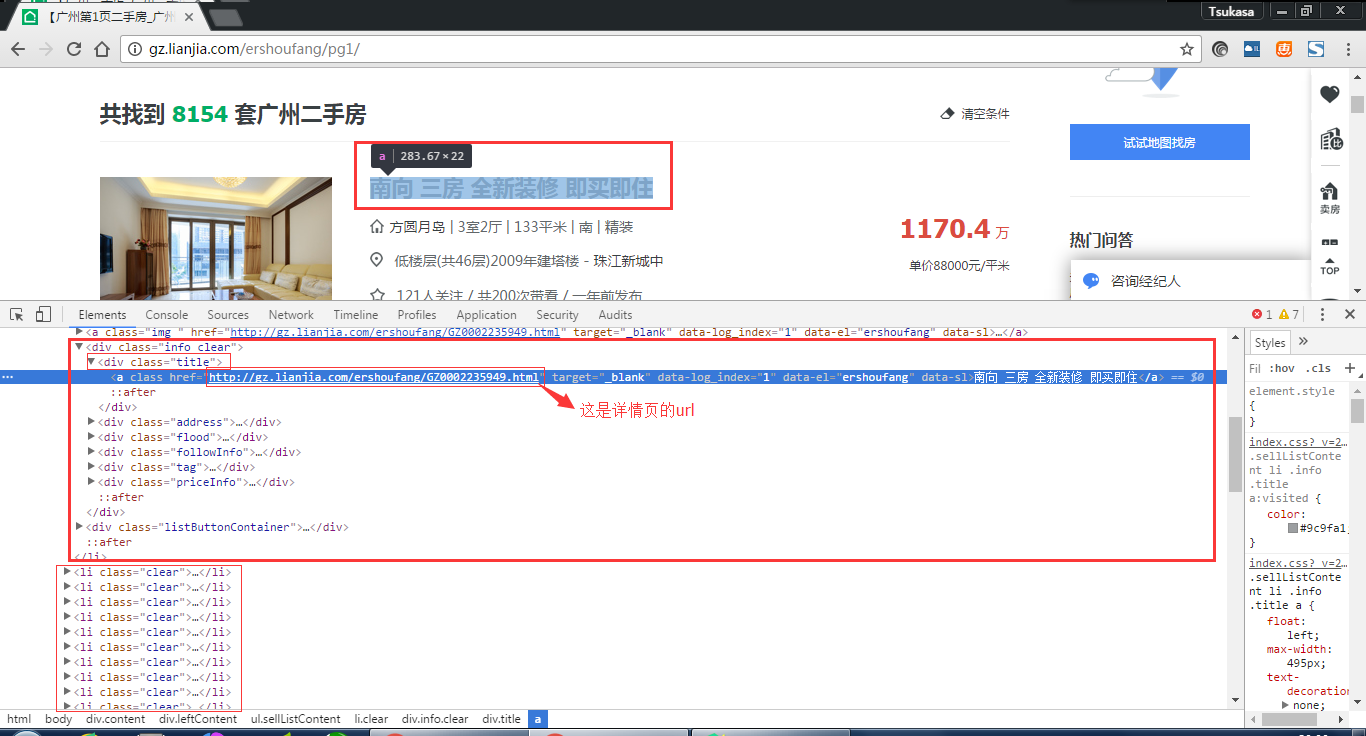
发现我们要的url是再class为title里面的a标签,我们可以使用request来获取html,用正则表达法来分析获取详情页url:
import requests
import re
def一个方法,把得到的generate_allurl传进来再打印一下看看
def get_allurl(generate_allurl):
get_url = requests.get(generate_allurl,)
if get_url.status_code == 200:
re_set = re.compile('<li.*?class="clear">.*?<a.*?class="img.*?".*?href="(.*?)"')
re_get = re.findall(re_set,get_url.text)
print(re_get)
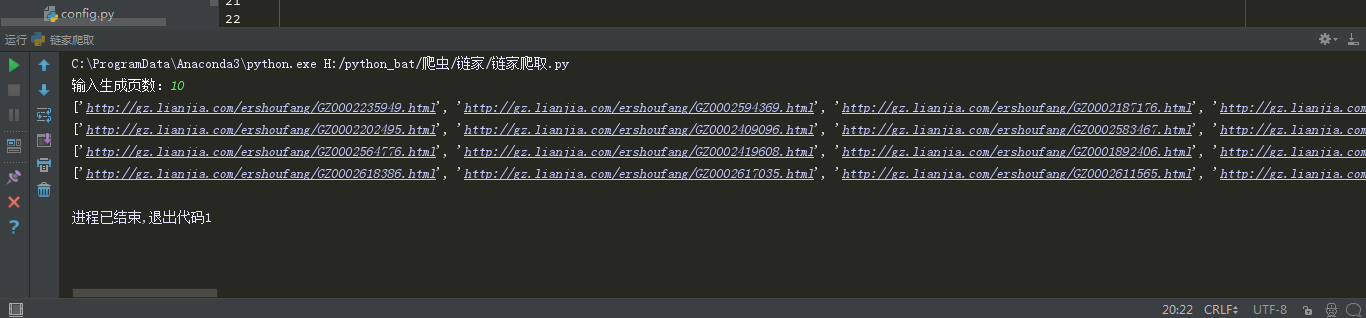
正常获取详细页的链接
下一步我们就要分析这些详细页连接以获取里面的资讯, 使用自带开发者工具点击这个箭头可以选择网页元素:
使用自带开发者工具点击这个箭头可以选择网页元素:

发现资讯在一个class为main里面,可以用BeautifulSoup模块里面的方法得到:
from bs4 import BeautifulSoup
定义一个方法来把详情url链接传进来分析:
def open_url(re_get):
res = requests.get(re_get)
if res.status_code == 200:
info = {}
soup = BeautifulSoup(res.text,'lxml')
info['标题'] = soup.select('.main')[0].text
info['总价'] = soup.select('.total')[0].text + '万'
info['每平方售价'] = soup.select('.unitPriceValue')[0].text
return info
这里把requests.get对象传给res,然后把这个变量传给BeautifulSoup,用lxml解析器解析,再把结果传给soup,然后就可以soup.select方法来筛选,因为上面标题在,main下:
soup.select('.main'),因为这里是一个class,所以前面要加.,如果筛选的是id,则加#。
得到如下结果:

是一个list,所以我们要加[ 0 ]取出,然后可以运用方法 .text得到文本。
def open_url(re_get):
res = requests.get(re_get)
if res.status_code == 200:
soup = BeautifulSoup(res.text,'lxml')
title = soup.select('.main')[0].text
print(title)
得到结果

然后还可以添加到字典,return返回字典:
def open_url(re_get):
res = requests.get(re_get)
if res.status_code == 200:
info = {}
soup = BeautifulSoup(res.text,'lxml')
info['标题'] = soup.select('.main')[0].text
info['总价'] = soup.select('.total')[0].text + '万'
info['每平方售价'] = soup.select('.unitPriceValue')[0].text
return info
得到结果:
还可以储存到xlsx文档里面:
def pandas_to_xlsx(info):
pd_look = pd.DataFrame(info)
pd_look.to_excel('链家二手房.xlsx',sheet_name='链家二手房')
ok基本完成,可能有没有说清楚的,留言我继续更新
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author;Tsukasa import json
from multiprocessing import Pool
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import pymongo def generate_allurl(user_in_nub, user_in_city): # 生成url
url = 'http://' + user_in_city + '.lianjia.com/ershoufang/pg{}/'
for url_next in range(1, int(user_in_nub)):
yield url.format(url_next) def get_allurl(generate_allurl): # 分析url解析出每一页的详细url
get_url = requests.get(generate_allurl, 'lxml')
if get_url.status_code == 200:
re_set = re.compile('<li.*?class="clear">.*?<a.*?class="img.*?".*?href="(.*?)"')
re_get = re.findall(re_set, get_url.text)
return re_get def open_url(re_get): # 分析详细url获取所需信息
res = requests.get(re_get)
if res.status_code == 200:
info = {}
soup = BeautifulSoup(res.text, 'lxml')
info['标题'] = soup.select('.main')[0].text
info['总价'] = soup.select('.total')[0].text + '万'
info['每平方售价'] = soup.select('.unitPriceValue')[0].text
info['参考总价'] = soup.select('.taxtext')[0].text
info['建造时间'] = soup.select('.subInfo')[2].text
info['小区名称'] = soup.select('.info')[0].text
info['所在区域'] = soup.select('.info a')[0].text + ':' + soup.select('.info a')[1].text
info['链家编号'] = str(re_get)[33:].rsplit('.html')[0]
for i in soup.select('.base li'):
i = str(i)
if '</span>' in i or len(i) > 0:
key, value = (i.split('</span>'))
info[key[24:]] = value.rsplit('</li>')[0]
for i in soup.select('.transaction li'):
i = str(i)
if '</span>' in i and len(i) > 0 and '抵押信息' not in i:
key, value = (i.split('</span>'))
info[key[24:]] = value.rsplit('</li>')[0]
print(info)
return info def update_to_MongoDB(one_page): # update储存到MongoDB
if db[Mongo_TABLE].update({'链家编号': one_page['链家编号']}, {'$set': one_page}, True): #去重复
print('储存MongoDB 成功!')
return True
return False def pandas_to_xlsx(info): # 储存到xlsx
pd_look = pd.DataFrame(info)
pd_look.to_excel('链家二手房.xlsx', sheet_name='链家二手房') def writer_to_text(list): # 储存到text
with open('链家二手房.text', 'a', encoding='utf-8')as f:
f.write(json.dumps(list, ensure_ascii=False) + '\n')
f.close() def main(url): writer_to_text(open_url(url)) #储存到text文件
# update_to_MongoDB(list) #储存到Mongodb if __name__ == '__main__':
user_in_city = input('输入爬取城市:')
user_in_nub = input('输入爬取页数:') Mongo_Url = 'localhost'
Mongo_DB = 'Lianjia'
Mongo_TABLE = 'Lianjia' + '\n' + str('zs')
client = pymongo.MongoClient(Mongo_Url)
db = client[Mongo_DB]
pool = Pool()
for i in generate_allurl('', 'zs'):
pool.map(main, [url for url in get_allurl(i)])
源码地址:https://gist.github.com/Tsukasa007/660fce644b7dd33afc57998fdc6c376a
python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码的更多相关文章
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- python爬取链家二手房信息,确认过眼神我是买不起的人
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 python免费学习资 ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
- 【nodejs 爬虫】使用 puppeteer 爬取链家房价信息
使用 puppeteer 爬取链家房价信息 目录 使用 puppeteer 爬取链家房价信息 页面结构 爬虫库 pupeteer 库 实现 打开待爬页面 遍历区级页面 方法一 方法二 遍历街道页面 遍 ...
- python爬虫:爬取链家深圳全部二手房的详细信息
1.问题描述: 爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文件中 2.思路分析: (1)目标网址:https://sz.lianjia.com/ershoufang/ (2)代码结构 ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
随机推荐
- ZOJ 3774 Fibonacci的K次方和
In mathematics, Fibonacci numbers or Fibonacci series or Fibonacci sequence are the numbers of the f ...
- Python学习笔记(十八)@property
# 请利用@property给一个Screen对象加上width和height属性, # 以及一个只读属性resolution: # -*- coding: utf-8 -*- class Scree ...
- 最常用的8款 PHP 调试工具,你用过吗?
Web 开发并不是一项轻松的任务,有超级多服务端脚本语言提供给开发者,但是当前 PHP 因为具有额外的一些强大的功能而越来越流行.PHP 是最强大的服务端脚本语言之一,同时也是 Web 开发者和设计者 ...
- 【leetcode 简单】 第五十一题 有效电话号码
给定一个包含电话号码列表(一行一个电话号码)的文本文件 file.txt,写一个 bash 脚本输出所有有效的电话号码. 你可以假设一个有效的电话号码必须满足以下两种格式: (xxx) xxx-xxx ...
- Redis数据类型之散列(hash)
1. 什么是散列 散列类似于一个字典,是一个<K, V>对的集合,不过这个key和value都只能是字符串类型的,不能嵌套,可以看做Java中的Map<String, String& ...
- nth-child,nth-last-child,only-child,nth-of-type,nth-last-of-type,only-of-type,first-of-type,last-of-type,first-child,last-child伪类区别和用法
我将这坨伪类分成三组,第一组:nth-child,nth-last-child,only-child第二组:nth-of-type,nth-last-of-type,第三组:first-of-tpye ...
- Window 平台安装 Python:
Window 平台安装 Python: 打开WEB浏览器访问http://www.python.org/download/ 在下载列表中选择Window平台安装包,包格式为:python-XYZ.ms ...
- sniffer简单使用
跟wireshark类似. 只是说显示的容易忘记所以丢张图记录一下. 该工具还是很坑爹的,不是比赛要用到所以都不是很想弄.一般机器运行不起来.不是蓝屏就是装了运行不了各种闪退,找了学校一台内网服务器才 ...
- 关于parse_str变量覆盖分析
这个漏洞有两个姿势.一个是不存在的时候一个是存在的时候. 经过测试该漏洞只在php5.2中存在,其余均不存在. 倘若在parse_str函数使用的代码上方未将其定义那么即存在变量覆盖漏洞否则不行. 还 ...
- apache2启动失败(Failed to start The Apache HTTP Server.)解决方案
不知道如何启动apache2就启动不来了. 如下图所示: 即使卸载了重新装也是如此 经过测试卸载并清除软件包的配置即可解决 sudo apt-get purge apache2 sudo apt-g ...