python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1、问题描述:
爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表
2、思路分析:
发送请求--获取数据--解析数据--存储数据
1、目标网址:https://sz.lianjia.com/ershoufang/
2、利用requests.get()方法向链家深圳二手房首页发送请求,获取首页的HTML源代码
#目标网址
targetUrl = "https://sz.lianjia.com/ershoufang/"
#发送请求,获取响应
response = requests.get(targetUrl).text
3、利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice
(1)首先看一下链家深圳二手房网页的结构,可以很容易发现链家的规则,每个二手房的详细信息都在<li class="clear LOGCLICKDATA">中,所以我们只需要解析出这个class中包含的详细信息即可。

'''利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice'''
soup = BeautifulSoup(response, "html.parser")
houseInfo = soup.find_all("div", class_ = "houseInfo")
priceInfo = soup.find_all("div", class_ = "priceInfo")
floodInfo = soup.find_all("div", class_ = "flood")
name = [house.text.split("|")[0].strip() for house in houseInfo]
houseType = [house.text.split("|")[1].strip() for house in houseInfo]
area = [house.text.split("|")[2].strip() for house in houseInfo]
direction = [house.text.split("|")[3].strip() for house in houseInfo]
flood = [flo.text.split("-")[0] for flo in floodInfo]
href = [house.find("a")["href"] for house in houseInfo]
totalPrice = [(re.findall("\d+", price.text))[0] for price in priceInfo]
unitPrice = [(re.findall("\d+", price.text))[1] for price in priceInfo]
#将爬取到的所有二手房的详细信息整合到house列表中
house = [name, href, houseType, area, direction, flood, totalPrice, unitPrice]
4、将数据存储到Excel表格中
#将二手房的详细信息存储到Excel表格Lianjia_I.xlsx中
workBook = xlwt.Workbook(encoding="utf-8") #创建Excel表,并确定编码方式
sheet = workBook.add_sheet("Lianjia_I") #新建工作表Lianjia_I
headData = ["小区名称", "链接", "户型", "面积", "朝向", "楼层", "价格(万)", "单价"] #表头信息
for col in range(len(headData)):
sheet.write(0, col, headData[col])
for raw in range(1, len(name)):
for col in range(len(headData)):
sheet.write(raw, col, house[col][raw-1])
workBook.save(".\Lianjia_I.xlsx")
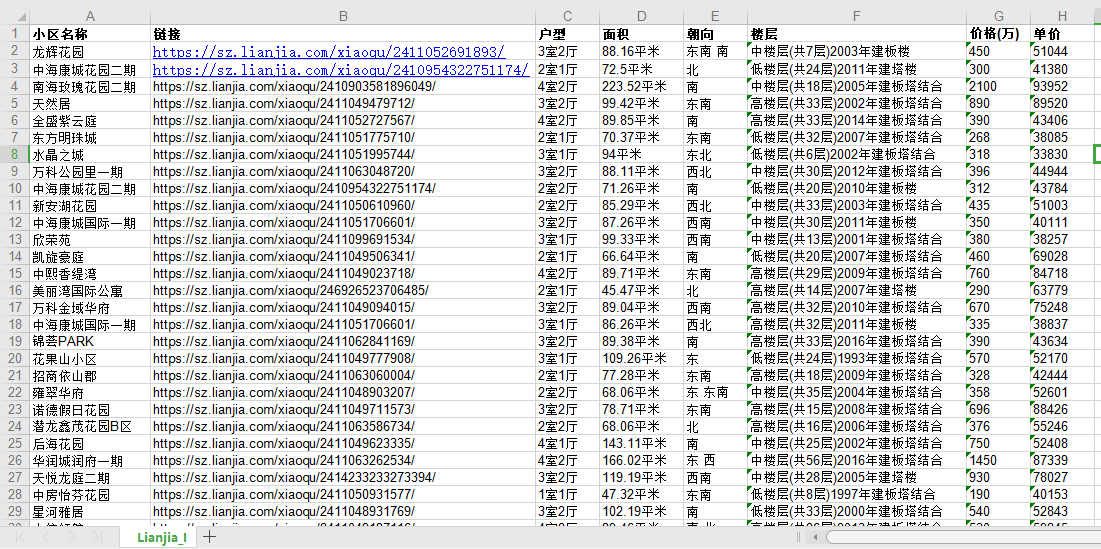
3、效果展示
4、完整代码:
# -* coding: utf-8 *-
# author: wangshx6
# date: 2018-11-04
# description: 爬取链家深圳二手房首页的房子名称、户型、面积、价格等详细信息
import requests
import re
import xlwt
from bs4 import BeautifulSoup
# 目标网址
targetUrl = "https://sz.lianjia.com/ershoufang/"
#发送请求,获取响应
response = requests.get(targetUrl).text
'''利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice'''
soup = BeautifulSoup(response, "html.parser")
houseInfo = soup.find_all("div", class_ = "houseInfo")
priceInfo = soup.find_all("div", class_ = "priceInfo")
floodInfo = soup.find_all("div", class_ = "flood")
name = [house.text.split("|")[0].strip() for house in houseInfo]
houseType = [house.text.split("|")[1].strip() for house in houseInfo]
area = [house.text.split("|")[2].strip() for house in houseInfo]
direction = [house.text.split("|")[3].strip() for house in houseInfo]
flood = [flo.text.split("-")[0] for flo in floodInfo]
href = [house.find("a")["href"] for house in houseInfo]
totalPrice = [(re.findall("\d+", price.text))[0] for price in priceInfo]
unitPrice = [(re.findall("\d+", price.text))[1] for price in priceInfo]
house = [name, href, houseType, area, direction, flood, totalPrice, unitPrice]
# print(href, name, houseType, area, direction, totalPrice, unitPrice)
#将数据列表存储到Excel表格Lianjia_I.xlsx中
workBook = xlwt.Workbook(encoding="utf-8")
sheet = workBook.add_sheet("Lianjia_I")
headData = ["小区名称", "链接", "户型", "面积", "朝向", "楼层", "价格(万)", "单价"]
for col in range(len(headData)):
sheet.write(0, col, headData[col])
for raw in range(1, len(name)):
for col in range(len(headData)):
sheet.write(raw, col, house[col][raw-1])
workBook.save(".\Lianjia_I.xlsx")
python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息的更多相关文章
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- python爬虫:爬取链家深圳全部二手房的详细信息
1.问题描述: 爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文件中 2.思路分析: (1)目标网址:https://sz.lianjia.com/ershoufang/ (2)代码结构 ...
- python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言 作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始. 一.分析观察爬取网站结构 这里以广州链家二手房为例:http:/ ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- 43.scrapy爬取链家网站二手房信息-1
首先分析:目的:采集链家网站二手房数据1.先分析一下二手房主界面信息,显示情况如下: url = https://gz.lianjia.com/ershoufang/pg1/显示总数据量为27589套 ...
- python 爬虫 requests+BeautifulSoup 爬取巨潮资讯公司概况代码实例
第一次写一个算是比较完整的爬虫,自我感觉极差啊,代码low,效率差,也没有保存到本地文件或者数据库,强行使用了一波多线程导致数据顺序发生了变化... 贴在这里,引以为戒吧. # -*- coding: ...
- <爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库
网页情况: 代码: import requests from requests.exceptions import RequestException from bs4 import Beautiful ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
- python爬虫——利用BeautifulSoup4爬取糗事百科的段子
import requests from bs4 import BeautifulSoup as bs #获取单个页面的源代码网页 def gethtml(pagenum): url = 'http: ...
随机推荐
- Oracle数据库分割字符串function方法
下面我直接上传一串代码源码, create or replace function strsplit(p_value varchar2, p_split varchar2 := ',') --usag ...
- c#真正判断文件类型
//真正判断文件类型的关键函数 public static bool IsAllowedExtension2(FileUpload hifile) { if (hifile != null) { Sy ...
- .Net Core 应用框架。
1.分布式系统框架 https://github.com/MassTransit/MassTransit 2.搜索引擎 https://github.com/XiLife-OSPC/Masuit. ...
- ionic1跨域问题
在使用ionic是遇到跨域问题 我自己尝试简单的单间一个能返回数据的后台服务器,ionic的www目录我使用一个ionic的livereload 来当做一个简易的web服务器,在使用ionic ser ...
- Promise对象(异步编程)
Promise对象解决函数的异步调用(跟回调函数一样) 三种状态: 未完成(pending)已完成(fulfilled)失败(rejected) 通过then函数来链式调用 目前市面上流行的一些类库:
- 【翻译】Best Practices for User interface android 适配不同屏幕、不同分辨率
地址:http://developer.android.com/training/multiscreen/screendensities.html#TaskProvideAltBmp 安卓支持不同的屏 ...
- c语言函数指针的几种使用方式
1.直接定义函数指针赋值并使用. #include <stdio.h> int max(int x, int y) { if (x > y) return x; else retur ...
- GitHub教程(三) 本地仓库托管到GitHub
本文开头先特别声明一下:由于GitHub教程属于Git系列教程的GitHub子篇章,因此GitHub教程中将不再详细介绍Git操作命令及其用法,我会根据实际需要穿插着回顾Git操作命令.如果读者需要学 ...
- 开源时序服务器influxdb使用
文档 https://influxdb.com/docs/v0.9/introduction/overview.html 配置文件 /etc/opt/influxdb/influxdb.conf re ...
- Sleep 和 Wait 关于锁释放的区别
sleep和wait的区别是一个老生常谈的问题.Sleep 是 Thread类的方法, wait是Object类的方法.但是关键的区别是对锁的操作问题. 当我们调用sleep的时候,线程进入休眠,但是 ...