sparkSQL——DataFrame&Datasets
对于新司机,可能看到sc与spark不知道是什么,看图知意

***************************************************************************************************************************************
DataFrame.map(_.split("::"))报错 error: value split is not a member of org.apache.spark.sql.Row
看到下图红框报错处Row,想起DataFrame里的Row对象,虽然每一行是一列数据,但是需要将Row对象转换成String对象,才可以走split方法

看下图,
spark.read.json返回类型是DataFrame
spark.read.textFile返回类型是Dataset

***************************************************************************************************************************************
由于 RDD、DataFrame、DataSets 之间是可以相互转化的,所以可通过多种方式读取数据,并进行互相进行转化
如下图:

***************************************************************************************************************************************
接下来这是另一个错,算是,恩,算是什么呢?

***************************************************************************************************************************************
来看一个join的例子
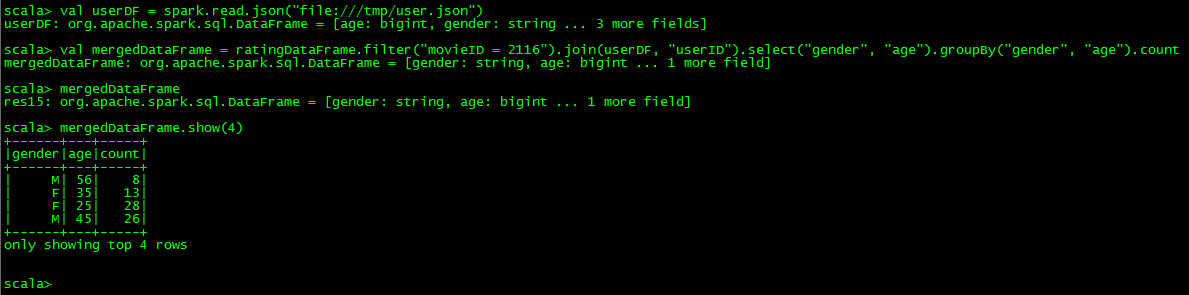
或者使用下面的方式,如果用左联接的话,只需要将inner改为leftouter

***************************************************************************************************************************************
创建临时表

***************************************************************************************************************************************
创建全局表


sparkSQL——DataFrame&Datasets的更多相关文章
- 【Spark-SQL学习之二】 SparkSQL DataFrame创建和储存
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- SparkSQL /DataFrame /Spark RDD谁快?
如题所示,SparkSQL /DataFrame /Spark RDD谁快? 按照官方宣传以及大部分人的理解,SparkSQL和DataFrame虽然基于RDD,但是由于对RDD做了优化,所以性能会优 ...
- SparkSQL 中 RDD 、DataFrame 、DataSet 三者的区别与联系
一.SparkSQL发展: Shark是一个为spark设计的大规模数据仓库系统,它与Hive兼容 Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来(by s ...
- 【Spark篇】---SparkSQL on Hive的配置和使用
一.前述 Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行. 二.具体配置 1.在Spark客户端配置Hive On Spark 在Spark客户端安装包下sp ...
- Spark学习之路 (十八)SparkSQL简单使用
一.SparkSQL的进化之路 1.0以前: Shark 1.1.x开始: SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Dataframe 1.5.x: S ...
- Spark(十二)SparkSQL简单使用
一.SparkSQL的进化之路 1.0以前: Shark 1.1.x开始:SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Datafram ...
- Spark学习之路 (十八)SparkSQL简单使用[转]
SparkSQL的进化之路 1.0以前: Shark 1.1.x开始: SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Dataframe 1.5.x: Spar ...
- DataFrame简介(一)
1. DataFrame 本片将介绍Spark RDD的限制以及DataFrame(DF)如何克服这些限制,从如何创建DataFrame,到DF的各种特性,以及如何优化执行计划.最后还会介绍DF有哪些 ...
- 强者联盟——Python语言结合Spark框架
引言:Spark由AMPLab实验室开发,其本质是基于内存的高速迭代框架,"迭代"是机器学习最大的特点,因此很适合做机器学习. 得益于在数据科学中强大的表现,Python语言的粉丝 ...
随机推荐
- Android动态禁用或开启屏幕旋转工具
package com.gwtsz.gts2.util; import android.content.Context; import android.provider.Settings; impor ...
- STM32 PWM的输出与Keil软件仿真
导读:PWM(Pulse Width Modulation)控制——脉冲宽度调制技术,通过对一系列脉冲的宽度进行调制,来等效地获得所需要波形(含形状和幅值). PWM控制技术在逆变电路中应用最广,应用 ...
- webpack报错no postcss config...
终端里运行的错误: 查了好多资料,最后找到解决办法,改为: const webpack = require('webpack'); // const autoprefixer = require('a ...
- 【BZOJ5074】[Lydsy十月月赛]小B的数字 数学
[BZOJ5074][Lydsy十月月赛]小B的数字 题解:题目是问你ai*bi>=sum,bi>=0这个不等式组有没有解.因为a<=10,容易想到取ai的lcm,然后变成lcm*b ...
- 02.ZooKeeper的Java客户端使用
1.ZooKeeper常用客户端比较 1.ZooKeeper常用客户端 zookeeper的常用客户端有3种,分别是:zookeeper原生的.Apache Curator.开源的zkclie ...
- R中K-Means、Clara、C-Means三种聚类的评估
R中cluster中包含多种聚类算法,下面通过某个数据集,进行三种聚类算法的评估 # ============================ # 评估聚类 # # ================= ...
- JavaScript学习(6)-文档对象模型基础
JavaScript学习6-文档对象模型基础 1.节点方法 节点对象方法(W3C DOM Level2) 方法 说明 appendChild(newChild) 添加子节点到当前节点的末端 clone ...
- OKEX量化分析报告[2017-12-08]
[生成时间]2017-12-08 21:07:46 [报告内容]DASH_USDT短期 3.0中期 1.0长期 —— LRC_USDT短期 4.0中期 —— ...
- python学习笔记(五)— 内置函数
我们常用的‘’int,str,dict,input,print,type,len‘’都属于内置函数 print(all([1,2,3,4]))#判断可迭代的对象里面的值是否都为真 print(any( ...
- 剑指Offer——求1+2+3+...+n
题目描述: 求1+2+3+...+n,要求不能使用乘除法.for.while.if.else.switch.case等关键字及条件判断语句(A?B:C). 分析: 递归实现. 代码: class So ...