sparkSQL——DataFrame&Datasets
对于新司机,可能看到sc与spark不知道是什么,看图知意

***************************************************************************************************************************************
DataFrame.map(_.split("::"))报错 error: value split is not a member of org.apache.spark.sql.Row
看到下图红框报错处Row,想起DataFrame里的Row对象,虽然每一行是一列数据,但是需要将Row对象转换成String对象,才可以走split方法

看下图,
spark.read.json返回类型是DataFrame
spark.read.textFile返回类型是Dataset

***************************************************************************************************************************************
由于 RDD、DataFrame、DataSets 之间是可以相互转化的,所以可通过多种方式读取数据,并进行互相进行转化
如下图:

***************************************************************************************************************************************
接下来这是另一个错,算是,恩,算是什么呢?

***************************************************************************************************************************************
来看一个join的例子
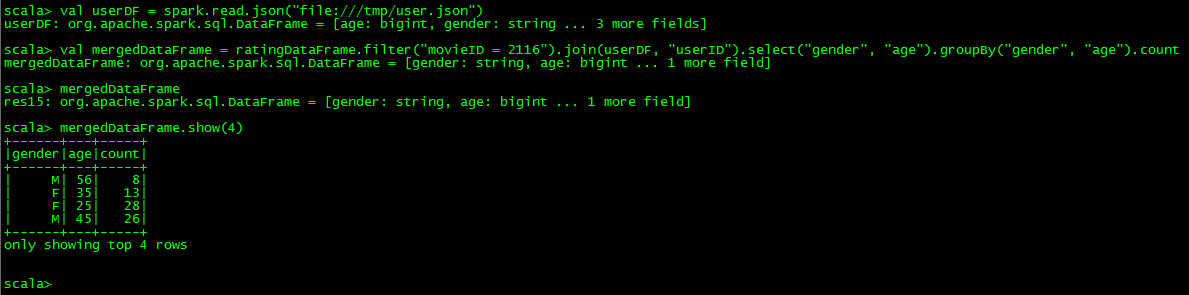
或者使用下面的方式,如果用左联接的话,只需要将inner改为leftouter

***************************************************************************************************************************************
创建临时表

***************************************************************************************************************************************
创建全局表


sparkSQL——DataFrame&Datasets的更多相关文章
- 【Spark-SQL学习之二】 SparkSQL DataFrame创建和储存
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- SparkSQL /DataFrame /Spark RDD谁快?
如题所示,SparkSQL /DataFrame /Spark RDD谁快? 按照官方宣传以及大部分人的理解,SparkSQL和DataFrame虽然基于RDD,但是由于对RDD做了优化,所以性能会优 ...
- SparkSQL 中 RDD 、DataFrame 、DataSet 三者的区别与联系
一.SparkSQL发展: Shark是一个为spark设计的大规模数据仓库系统,它与Hive兼容 Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来(by s ...
- 【Spark篇】---SparkSQL on Hive的配置和使用
一.前述 Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行. 二.具体配置 1.在Spark客户端配置Hive On Spark 在Spark客户端安装包下sp ...
- Spark学习之路 (十八)SparkSQL简单使用
一.SparkSQL的进化之路 1.0以前: Shark 1.1.x开始: SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Dataframe 1.5.x: S ...
- Spark(十二)SparkSQL简单使用
一.SparkSQL的进化之路 1.0以前: Shark 1.1.x开始:SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Datafram ...
- Spark学习之路 (十八)SparkSQL简单使用[转]
SparkSQL的进化之路 1.0以前: Shark 1.1.x开始: SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Dataframe 1.5.x: Spar ...
- DataFrame简介(一)
1. DataFrame 本片将介绍Spark RDD的限制以及DataFrame(DF)如何克服这些限制,从如何创建DataFrame,到DF的各种特性,以及如何优化执行计划.最后还会介绍DF有哪些 ...
- 强者联盟——Python语言结合Spark框架
引言:Spark由AMPLab实验室开发,其本质是基于内存的高速迭代框架,"迭代"是机器学习最大的特点,因此很适合做机器学习. 得益于在数据科学中强大的表现,Python语言的粉丝 ...
随机推荐
- JAVA增删改查XML文件
最近总是需要进行xml的相关操作. 不免的要进行xml的读取修改等,于是上网搜索,加上自己的小改动,整合了下xml的常用操作. 读取XML配置文件 首先我们需要通过DocumentBuilderFac ...
- 杭电 1280 前m大的数
http://acm.hdu.edu.cn/showproblem.php?pid=1280 前m大的数 Time Limit: 2000/1000 MS (Java/Others) Memor ...
- iOS开发之-- 设置启动图片
一.添加启动图片 点击Assets.xcassets进入图片管理,右击,弹出"New Launch Image"或点下面的+号创建Launch Image: 如图,右侧的勾选可以让 ...
- 《C++ Primer Plus》第5章 循环和关系表达式 学习笔记
C++提供了3种循环: for 循环. while 循环 和 do while 循环 .如果循环测试条件为 true 或非零,则循环将重复执行一组指令: 如果测试条件为 false 或 0 , 则结束 ...
- 使用隧道技术进行C&C通信
一.C&C通信 这里的C&C服务器指的是Command & Control Server--命令和控制服务器,说白了就是被控主机的遥控端.一般C&C节点分为两种,C&a ...
- 【黑金原创教程】【Modelsim】【第五章】仿真就是人生
声明:本文为黑金动力社区(http://www.heijin.org)原创教程,如需转载请注明出处,谢谢! 黑金动力社区2013年原创教程连载计划: http://www.cnblogs.com/al ...
- 基于开源博客系统(jpress)搭建网站
基于开源博客系统(jpress)搭建网站 JPress 使用 Java8 开发,基于流行的JFinal和Jboot框架. 目前JPress已经内置的文章和页面其实是两个模块,可以移除和新增其他模块,因 ...
- JsBridge的异步不执行的处理--promise异步变同步
Hybird App:H5内嵌APP,前端用vue,APP之间的交互处理,适配安卓ios, 为了降低开发成本,减少前端适配工作量,三端统一使用 WebViewJavascriptBridge 在进行 ...
- Linux 常用资源
kernel:ftp://kernel.orgcnkernel:http://www.cnkernel.orgoldlinux:http://www.oldlinux.orgminix3:http:/ ...
- Spark源码分析 – Dependency
Dependency 依赖, 用于表示RDD之间的因果关系, 一个dependency表示一个parent rdd, 所以在RDD中使用Seq[Dependency[_]]来表示所有的依赖关系 Dep ...