nmon 命令(转)
转载:https://www.cnblogs.com/kongzhongqijing/articles/4057487.html
一、基本使用
nmon目前可支持AIX和LINUX,可到以下地址去免费下载:http://www-941.haw.ibm.com/collaboration/wiki/display/WikiPtype/nmon
nmon的使用比较简单,不用安装,直接将对应版本的安装包放到服务器上的某个目录下,运行即可,例如:
# ./nmon_x86_rhel4

显示CPU可按C,同样,Memory—M,Network I/O----N, Disk I/O---D如下:

按q键可以退出nmon,但是此时的定位符有点乱,最好clear一下。
# ./nmon –f -s 30 –c 100
说明:-f 以文件的形式输出,默认输出是机器名+日期.nmon的格式,也可以用-F指定输出的文件名,例如: # ./nmon_x86_rhel4 –F test.nmon -s 30 –c 100;
-s是采样频率,隔多长时间收集一次,这里我指定的是30秒一次;
-c是采样次数,一共要收集多少次,这里我指定的是100次。
注意:这里单次收集的文件大小最多不能超过65K行(EXCEL里的限制),大约是在nmon中 –c的值不超过330次就OK。
./nmon -f -s 10 -c 150
nmon生成的文件比较大,建议每次收集的次数不要太多,若需要收集很长时间的数据,建议分开收集,也就是生成多个文件,LINUX里可以用建多个job的方式进行,例如:
先创建一个脚本,例如命名为nmon.sh,如下:
#! /bin/sh
./nmon_x86_rhel4 -F 6326081116_6AM.nmon -s 60 -c 240
给这个文件授权:
#chmod 777 nmon.sh
然后建一个job:
# at –f nmon.sh 6:00 January 16
运行完毕如下:
如果要建长期任务可以用crontab命令进行,建议一般不要用这个命令,否则很容易忘记你建过多少任务,造成后台事务消耗资源。
分析:
将生成的.nmon文件转为excel能识别的.csv文件,如下:
# sort test.nmon > test.csv
生成的.csv文件就可以放到windows平台下进行分析了。
通常,我不太建议对稳定性测试用nmon监控,因为需要收集太多的信息生成文件较大,实际上,要对linux/unix的服务端资源进行性能监控,用vmstat和iostat这两个命令去收集足够了。
在/home/software/nmon
nmon.sh 10 1
10指每10秒统计一次,1指共运行1分钟, 每300次会新生成一个文件
二、nmon大文件处理
当监控的时间超过一定时间(如10个小时),产生的.nmon会很大约10M。这时,使用nmon analyser v34.xls分析nmon文件会报错。原因是内存不足。
解决方案:
1.将生成的.nmon文件split成几个小文件。
如执行split -l 65500 result.nmon;
其中65500表示行数;
2.生成得到的xaa、xab、xab等文件。
在xaa文件中找到第一次出现“ZZZZ”的那一行,将这一行以上(不包含这一行)的内容全部copy到xab、xac等文件中。
3.给xaa、xab、xac等文件加上后缀.nmon。
4.使用nmon analyser v33e3.xls继续分析生成对应的excel文件。
关于详细的参考:http://www.cnblogs.com/ermao0927/p/3650422.html
摘取内容如下:
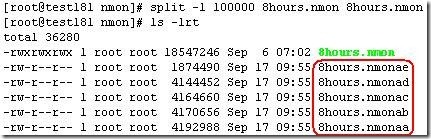
3.5.1 使用split命令如何减小.nmon文件的大小呢?其实操作系统已经提供了很有用的文件分割命令,即split。 split是Linux/Unix自带的系统命令,一般的使用语法如下: split [-<行数>][-b <字节>][-C <字节>][-l <行数>][分割的文件名][输出的文件名] 参数: -<行数>或-l <行数> 指定每多少行要切成一个小文件。 -b <字节> 指定每多少字节要切成一个小文件。支持单位m,k。 -C <字节> 与-b参数类似,但切割时尽量维持每行的完整性。 下面以一个大小为18M左右的8hours.nmon文件为例,详细介绍如何使用split命令把它分割成Nmon_analyser工具可以解析的文件,并且最终合并成为一个完整的Excel报告。 首先登录Linux系统,在8hours.nmon文件所在目录下,执行“split -l 100000 8hours.nmon 8hours.nmon”命令,生成的文件如下:
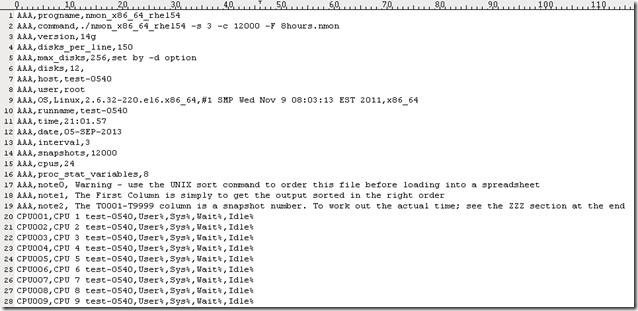
可以看到,18M大小的结果文件,分割成每个文件10W行,总计生成5个子文件。分割的子文件个数不宜太多,子文件太多的话,合并时工作量比较大;子文件太少的话,单个子文件过大,Nmon_analyser还是无法处理。 把生成的子文件拷贝到Windows系统下,将子文件导入Nmon_analyser工具进行解析,第一个文件8hours.nmonaa没有问题,可以成功生成报告,但从第二个开始报错,解析失败。使用UltraEdit或其他文本工具打开8hours.nmonaa和8hours.nmonab两个文件,比较它们的内容,发现第一个文件里面有完整的头文件:
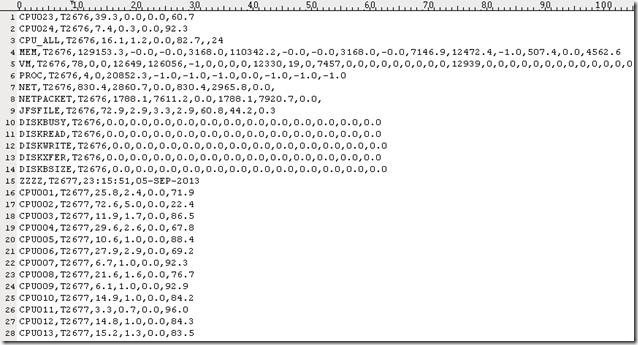
第二个文件里面只有数据文件,没有头文件:
按照第3.1节的介绍,没有头文件的.nmon是无法被解析的,处理的方法也很简单,把头文件拷贝到除了第一个文件外的所有文件即可。需要注意的头文件的内容有哪些,我们看一下第一个文件的内容:
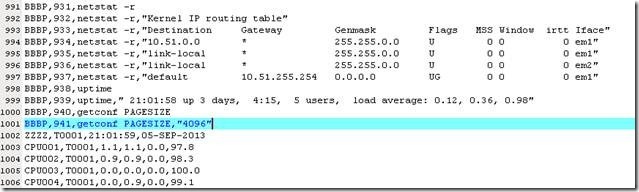
从上图可以看到,从第1002行开始,已经是具体的监控数据信息了,所以从第1行到1001行就是头文件的内容,将该内容拷贝到其他几个.nmon文件中,然后使用解析工具Nmon_anaylzer生成子报告。 打开生成的Excel报告文件,发现监控的各个时间点都变成无法识别的数字,如下图:
再次检查各个子文件的区别,发现由于之前把一个监控数据文件分割成了多个,所以每个数据文件都不是完整的,虽然添加了头文件,但是除了第一个文件外,其他文件的起始时间可能是在上一个子文件里的,所以就造成了子文件无法获取监控时间起点的问题。比如第一个结果文件最后的数据如下:
第二个结果文件最开始的数据如下图:
注意上图的第一行,只有监控数据,没有监控时间,这样在Nmon_analyser解析该文件时,由于没有监控的起始时间,导致后面的监控时间出现混乱,所以除了第一个子文件外,后面每个子文件都需要添加监控的起始时间。方法是将前一个数据文件最后一次出现的时间数据直接拷贝到当前文件第一行(不包括头文件)即可。 所有的子文件都生成结果报告后,下面的工作就是合并各个报告,生成一个完整的监控结果报告。根据目前实验室性能测试报告的数据要求,仅进行CPU和内存数据的合并。 CPU数据的合并涉及SYS_SUMM和CPU_ALL两个sheet,首先按照数据产生的先后顺序,把所有子文件CPU_ALL的数据拷贝到第一个子文件的CPU_ALL,记录拷贝之后的数据总行数,本例中是3061行,同时计算各列的平均值和最大值(实际按照报告要求,只计算CPU%一列即可),如下图:
SYS_SUMM中的CPU的AVG和MAX值即来自上图中的数据。下面介绍如何生成SYS_SUMM中的CPU坐标图,在拷贝所有CPU_ALL的数据到第一个子文件之后,查看SYS_SUMM中的CPU坐标图:
可以看到,横轴的时间没有变化,还是第一个子文件的时段,需要根据CPU_ALL的数据进行调整,直接点击CPU曲线,可以看到sheet表格上方出现了CPU曲线的生成公式:
显然曲线的生成公式没有包含合并的CPU数据,所以需要修改公式,修改最大行数为合并后的行数,即3061行,修改后的公式如下: =SERIES(CPU_ALL!$F$1,CPU_ALL!$A$2:$A$3061,CPU_ALL!$F$2:$F$3061,1) 生成的CPU曲线图如下:
可以看到,曲线图已经包含了所有的CPU监控数据,再修改Avg和Max的值为实际值,即完成了CPU监控数据的整合。 内存监控数据的合并比较简单,将所有的数据拷贝到第一个子文件中名为MEM的sheet中,然后计算Max、Min和Average的值即可。 3.5.2 使用文本编辑器在实际的工作中,还有一种比较简单的替代split的方法。由于.nmon是一种类.txt格式的文件,所以可以使用市面常用的txt编辑器直接打开进行分割和编辑。这里不用windows自带的txt工具打开是因为.nmon文件一般都比较大,打开比较慢,而且自带的txt工具编辑功能较差,不推荐使用,建议使用Ultraedit或Editplus等工具。 另外,之所以把split命令作为第一种解决问题的方法,是因为在外出工作时,客户的办公场所很可能限制外来U盘和外网的接入,所以如果测试机上未安装Ultraedit或Editplus等编辑工具,使用Linux/Unix自带的split命令便成了第一选择。 3.6 规避方法遇到问题时,如果暂时无法解决,在以后的工作中尝试规避问题,也是解决问题的一种方式。在使用Nmon命令行收集系统资源时,加大收集数据的间隔,从而减小收集频率,就能控制生成的数据文件的规模,从而规避无法生成结果文件的问题。但是在实际操作时,由于测试时间、测试环境及操作等很多原因,生成大文件有时无法避免,所以掌握处理大文件的方法还是很有必要的。 |
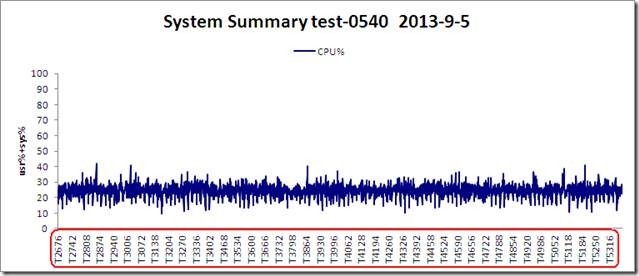
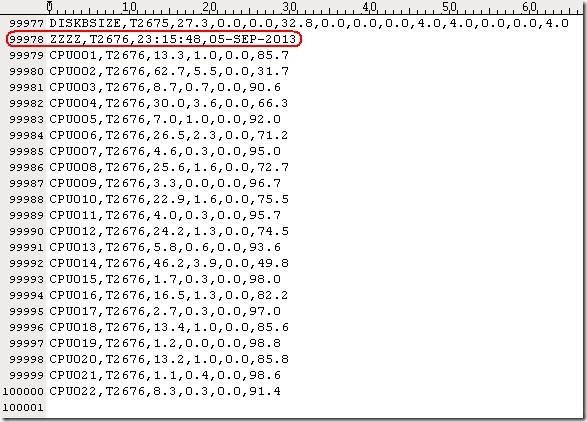
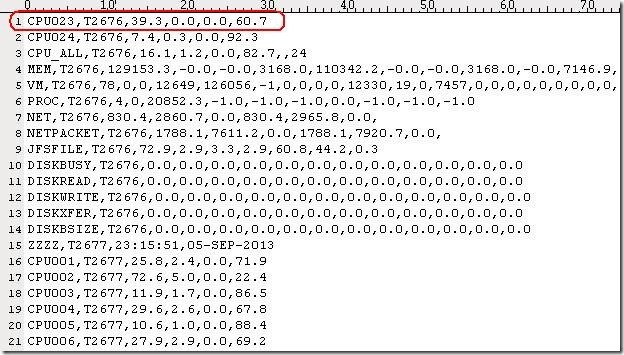
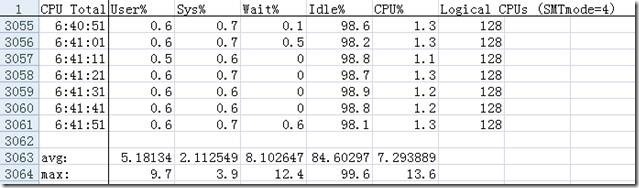

对多台linux服务器使用nmon如何监控,服务器数量多时,每台机器都执行nmon命令会比较麻烦。方法比较多。
1、shell脚本,各服务器之间建立信任关系。
2、负载机上使用ant工具,在build.xml文件中配置各服务器的信息。可实现对远程服务器的nmon命令的执行,nmon文件的下载与删除。
3、手工编写工具实现。
nmon 命令(转)的更多相关文章
- nmon命令用法
用途 以交互方式显示本地系统统计信息并以记录方式记录系统统计信息. 语法 交互方式: nmon [ -h ] nmon [ -s < seconds > ] [ -c < count ...
- nmon 命令
nmon 命令 用途 以交互方式显示本地系统统计信息并以记录方式记录系统统计信息. 语法 交互方式: nmon [ -h ] nmon [ -s < seconds >] [ -c < ...
- Nmon命令行:Linux系统性能的监测利器
如果你眼下正在寻找一款非常易于使用的Linux性能监测工具,那么我强烈推荐安装和使用Nmon命令行实用工具. Nmon监测工具 Nmon是一款面向系统管理员的调优和基准测量工具,可以用来显示关于下列方 ...
- linux 操作系统级别监控 nmon命令
nmon是IBM公司开发的Linux性能监控工具,可以实时展示系统性能情况,也可以将监控数据写入文件中,并使用nmon分析器做数据展示 实时监控 命令 ./nmon c 代表CPU m 代表Memor ...
- Linux nmon 命令
nmon 是一个资源监控工具,能够监控 Linux 系统资源( cpu,memory,network,disks )的使用情况,常见用法如下: [root@localhost ~]$ yum inst ...
- Linux下使用NMON监控、分析系统性能
一.下载nmon. 根据CPU的类型选择下载相应的版本:http://nmon.sourceforge.net/pmwiki.php?n=Site.Downloadwget http://source ...
- nmon工具的安装及简单使用
1.工具的安装 下载rpm包安装即可http://mirror.ghettoforge.org/distributions/gf/el/6/gf/x86_64/nmon-14i-1.gf.el6.x8 ...
- 【原创】使用Nmon_Analyzer处理较大nmon文件的方法
1 编写目的 进行性能测试时,测试服务器使用的操作系统是Linux或Unix时,我们一般会使用Nmon工具进行操作系统资源监控数据的收集.Nmon工具是一款非常优秀的性能监控和分析工具,它能够实时地收 ...
- Linux下使用NMON监控、分析系统性能 -转载
原帖地址:http://blog.itpub.net/23135684/viewspace-626439/ 谢谢原帖大人 一.下载nmon. 根据CPU的类型选择下载相应的版本:http://nmon ...
随机推荐
- DateFormat 线程安全
SimpleDateformat 线程不安全 SimpleDateFormat 继承自 DateFormat, SimpleDateFormat中的parse方法override父类DateForma ...
- asp.net core集成MongoDB
0.目录 整体架构目录:ASP.NET Core分布式项目实战-目录 一.前言及MongoDB的介绍 最近在整合自己的框架,顺便把MongoDBD的最简单CRUD重构一下作为组件化集成到asp.net ...
- hdu 1253
D - 胜利大逃亡 Time Limit:2000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit St ...
- 【8.30校内测试】【找规律模拟】【DP】【二分+贪心】
对于和规律或者数学有关的题真的束手无策啊QAQ 首先发现两个性质: 1.不管中间怎么碰撞,所有蚂蚁的相对位置不会改变,即后面的蚂蚁不会超过前面的蚂蚁或者落后更后面的蚂蚁. 2.因为所有蚂蚁速度一样,不 ...
- bzoj 3872: [Poi2014]Ant colony -- 树形dp+二分
3872: [Poi2014]Ant colony Time Limit: 30 Sec Memory Limit: 128 MB Description There is an entranc ...
- bzoj 3437: 小P的牧场 -- 斜率优化
3437: 小P的牧场 Time Limit: 10 Sec Memory Limit: 128 MB Description 小P在MC里有n个牧场,自西向东呈一字形排列(自西向东用1…n编号), ...
- bzoj 1670: [Usaco2006 Oct]Building the Moat护城河的挖掘 -- 凸包
1670: [Usaco2006 Oct]Building the Moat护城河的挖掘 Time Limit: 3 Sec Memory Limit: 64 MB Description 为了防止 ...
- 并查集--CSUOJ 1601 War
并查集的经典题目: CSUOJ 1601: War Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 247 Solved: 70[Submit][Sta ...
- Educational Codeforces Round 11 E. Different Subsets For All Tuples 动态规划
E. Different Subsets For All Tuples 题目连接: http://www.codeforces.com/contest/660/problem/E Descriptio ...
- 二叉树遍历-JAVA实现
二叉树遍历分为前序.中序.后序递归和非递归遍历.还有层序遍历. //二叉树节点 public class BinaryTreeNode { private int data; private Bina ...