TensorFlow学习笔记(七)TesnorFlow实现计算加速
目录:
一、TensorFlow使用GPU
二、深度学习训练与并行模式
三、多GPU并行
四、分布式TensorFlow
4.1分布式TensorFlow的原理
4.2分布式TensorFlow模型训练
4.3使用caicloud运行分布式TensorFlow
深度学习应用到实际问题中,一个非常棘手的问题是训练模型时计算量太大。为了加速训练,TensorFlow可以利用GPU或/和分布式计算进行模型训练。
一、TensorFlow使用GPU
TensorFlow可以通过td.device函数来指定运行每个操作的设备,这个设备可以是本设备的CPU或GPU,也可以是远程的某一台设备。
TF生成会话的时候,可愿意通过设置tf.log_device_placemaent参数来打印每一个运算的设备。
import tensorflow as tf a = tf.constant([1.0,2.0,3.0],shape=[3],name='a')
b = tf.constant([1.0,2.0,3.0],shape=[3],name='b')
c= tf.add_n([a,b],name="c") with tf.Session(config=tf.ConfigProto(log_device_placement = True)) as sess:
print(sess.run(c)) ########
Device mapping: no known devices.
c: (AddN): /job:localhost/replica:0/task:0/device:CPU:0
b: (Const): /job:localhost/replica:0/task:0/device:CPU:0
a: (Const): /job:localhost/replica:0/task:0/device:CPU:0 [2. 4. 6.]
在配置好了GPU环境的TensorFlow中,如果没有明确指明运行设备,TF会优先选择GPU。
import tensorflow as tf a = tf.constant([1.0,2.0,3.0],shape=[3],name='a')
b = tf.constant([1.0,2.0,3.0],shape=[3],name='b')
c= tf.add_n([a,b],name="c") with tf.Session(config=tf.ConfigProto(log_device_placement = True)) as sess:
print(sess.run(c)) ########
Device mapping: no known devices.
c: (AddN): /job:localhost/replica:0/task:0/device:GPU:0
b: (Const): /job:localhost/replica:0/task:0/device:GPU:0
a: (Const): /job:localhost/replica:0/task:0/device:GPU:0 [2. 4. 6.]
可以通过tf.device 来制定运行操作的设备。
import tensorflow as tf
with tf.device("/CPU:0"):
a = tf.constant([1.0,2.0,3.0],shape=[3],name='a')
b = tf.constant([1.0,2.0,3.0],shape=[3],name='b')
with tf.device("/GPU:0"):
c= tf.add_n([a,b],name="c") with tf.Session(config=tf.ConfigProto(log_device_placement = True)) as sess:
print(sess.run(c))
某些数据类型是不被GPU所支持的。强制指定设备会报错。为了避免解决这个问题。在创建会还时可以指定参数allow_soft_placement 。当allow_soft_placement为True的时候,如果运算无法在GPU上运行,TF会自动将其放在CPU 上运行。
a_cpu = tf.Variable(0,name='a_cpu')
with tf.device('/gpu:0'):
a_gpu = tf.Variable(0,name='a_gpu') sess = tf.Session(config=tf.ConfigProto(log_device_placement=True,allow_soft_placement = True))
sess.run(tf.global_variables_initializer())
a_gpu: (VariableV2): /job:localhost/replica:0/task:0/device:CPU:0
a_gpu/read: (Identity): /job:localhost/replica:0/task:0/device:CPU:0
a_gpu/Assign: (Assign): /job:localhost/replica:0/task:0/device:CPU:0
init/NoOp_1: (NoOp): /job:localhost/replica:0/task:0/device:CPU:0
a_cpu: (VariableV2): /job:localhost/replica:0/task:0/device:CPU:0
a_cpu/read: (Identity): /job:localhost/replica:0/task:0/device:CPU:0
a_cpu/Assign: (Assign): /job:localhost/replica:0/task:0/device:CPU:0
init/NoOp: (NoOp): /job:localhost/replica:0/task:0/device:CPU:0
init: (NoOp): /job:localhost/replica:0/task:0/device:CPU:0
a_gpu/initial_value: (Const): /job:localhost/replica:0/task:0/device:CPU:0
a_cpu/initial_value: (Const): /job:localhost/replica:0/task:0/device:CPU:0
实践经验:将计算密集型的操作放在GPU上。为了提高程序运行速度,尽量将相关操作放在同一台设备上。
二、深度学习训练与并行模式
常用的并行化深度学习模型的方法有两种:同步模式和异步模式。
在异步模式下,不同设备之间是完全独立的。
异步模型流程图:
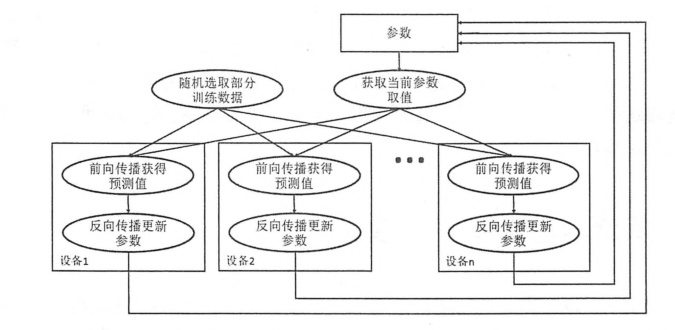
同步模型流程图:
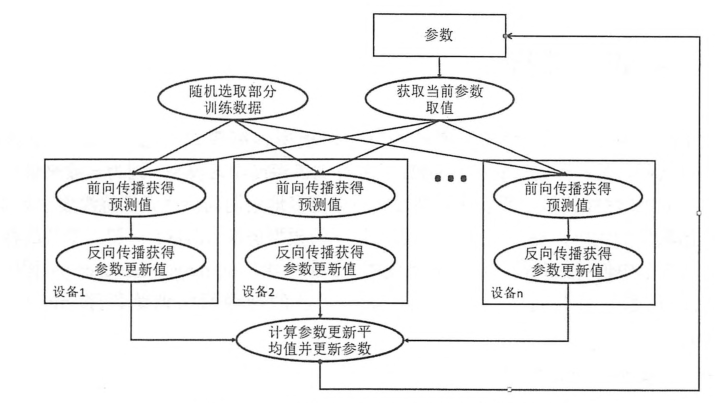
同步模式时,单个设备不会单独对参数进行更新,而会等待所有设备都完成反向传播之后再统一更新参数。
同步模式解决了异步模式中存在参数更新的问题,然而同步模式的效率却低于异步模式。
三、多GPU并行
一般来说,一台机器上的多个GPU性能相似,所以在这种设置下跟多的是采用同步模式训练甚多学习模型。
四、分布式TensorFlow
通过多GPU并行的方式固然可以达到很好的训练效果,但是一台机器上毕竟GPU的个数是有限的。如果需要记忆不提升深度学习模型的训练效果,就需要将TensorFlow分布式的运行在多台计算机上。
4.1分布式TensorFlow的原理
在第二个小结中,介绍了分布式TensorFlow训练甚多学习模型的理论。本小节将具体介绍如何使用TF在分布式集群中训练深度学习模型。TensorFlow集群通过一系列的任务(tasks)来执行TF计算图中的运算。一般来说,不同的任务跑在不同的机器上。当然,使用GPU时,不同任务可以使用用一太机器上的不同GPU。TF中的任务可以聚合成工作。每个工作可以包含一个或多个任务。当一个TF集群有多个任务的时候,需要使用tf.train.ClusterSpec来指定运行每一个人物的机器。
配置第一个任务集群
import tensorflow as tf
c = tf.constant('Hello ,this is the server1!')
#生成一个有两个人物的集群,一个任务跑在本地的2222端口,另一个跑在本地的2223端口
cluster = tf.train.ClusterSpec({"local":['localhost:2998','localhost2999']})
#通过上面生成的集群配置生成Server。并通过job_name和task_index指定当前启动的任务。
server = tf.train.Server(cluster,job_name='local',task_index=0)
#通过server.target生成会话来使用来使用TF集群中的资源。通过log_device_placement可以看到执行每一个操作的任务
sess = tf.Session(server.target,config=tf.ConfigProto(log_device_placement = True))
print(sess.run(c))
配置第二个任务,使用同样的集群配置
import tensorflow as tf
c = tf.constant('Hello ,this is the server2!')
#和第一个任务一样的集群配置
cluster = tf.train.ClusterSpec({"local":['localhost:2998','localhost2999']})
#指定task_index = 1,所以第二个任务是运行在2999端口上
server = tf.train.Server(cluster,job_name='local',task_index=0)
sess = tf.Session(server.target,config=tf.ConfigProto(log_device_placement = True))
print(sess.run(c))
当只启动第一个任务时,程序会停下来等待第二个任务启动。而且持续输出failed to connect to “ipv4:127.0.0.1:2999”,当第二个任务启动后,才会输出第一个任务的结果。
4.2分布式TensorFlow模型训练
4.3使用caicloud运行分布式TensorFlow
TensorFlow学习笔记(七)TesnorFlow实现计算加速的更多相关文章
- tensorflow学习笔记七----------RNN
和神经网络不同的是,RNN中的数据批次之间是有相互联系的.输入的数据需要是要求序列化的. 1.将数据处理成序列化: 2.将一号数据传入到隐藏层进行处理,在传入到RNN中进行处理,RNN产生两个结果,一 ...
- tensorflow学习笔记七----------卷积神经网络
卷积神经网络比神经网络稍微复杂一些,因为其多了一个卷积层(convolutional layer)和池化层(pooling layer). 使用mnist数据集,n个数据,每个数据的像素为28*28* ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- TensorFlow学习笔记10-卷积网络
卷积网络 卷积神经网络(Convolutional Neural Network,CNN)专门处理具有类似网格结构的数据的神经网络.如: 时间序列数据(在时间轴上有规律地采样形成的一维网格): 图像数 ...
- Tensorflow学习笔记2:About Session, Graph, Operation and Tensor
简介 上一篇笔记:Tensorflow学习笔记1:Get Started 我们谈到Tensorflow是基于图(Graph)的计算系统.而图的节点则是由操作(Operation)来构成的,而图的各个节 ...
- Tensorflow学习笔记2019.01.22
tensorflow学习笔记2 edit by Strangewx 2019.01.04 4.1 机器学习基础 4.1.1 一般结构: 初始化模型参数:通常随机赋值,简单模型赋值0 训练数据:一般打乱 ...
- Tensorflow学习笔记2019.01.03
tensorflow学习笔记: 3.2 Tensorflow中定义数据流图 张量知识矩阵的一个超集. 超集:如果一个集合S2中的每一个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S ...
随机推荐
- Ubuntu Python 安装numpy SciPy、MatPlotLib环境
安装 sudo apt-get install python-scipysudo apt-get install python-numpysudo apt-get install python-mat ...
- 学习:erlang正则
一.re:run/3. ①.re:run("321321","2132",[caseless]). {match,[{1,4}]} %% 返回值是 匹配 ...
- Lumen Carbon 日期及时间处理包
用到过的方法: 获取当前Y-m-d H:i:s Carbon::now()->toDateTimeString() 把 Y-m-d H:i:s 转 Y-m-d Carbon::parse('Y- ...
- 剑指 offer set 15 第一个只出现一次的字符
题目描述: 在一个字符串(1<=字符串长度<=10000,全部由大写字母组成)中找到第一个只出现一次的字符 思路: 1. 给定的题目约束比较多, 因此可以自定义哈希函数 2. 字符是一个长 ...
- ionic ui 框架
直接看着这写就行了 http://ionicframework.com/docs/components/
- 高级service之ipc ADIL用法
感谢 如果你还没有看过前面一篇文章,建议先去阅读一下 Android Service完全解析,关于服务你所需知道的一切(上) ,因为本篇文章中涉及到的代码是在上篇文章的基础上进行修改的. 在上篇文章中 ...
- Lua中 MinXmlHttpRequest如何发送post方式数据
local xhr=cc.XMLHttpRequest:new() xhr.responseType=cc.XMLHTTPREQUEST_RESPONSE_JSON xhr:open(“POST”,& ...
- centos6上安装docker
yum -y install epel-releaseyum -y install docker-ioyum install device-mapper-event-libs # 必需安装这一步,否 ...
- 【BZOJ2973】石头游戏 矩阵乘法
[BZOJ2973]石头游戏 Description 石头游戏的规则是这样的. 石头游戏在一个n行m列的方格阵上进行.每个格子对应了一个编号在0~9之间的操作序列. 操作序列是一个长度不超过6且循环执 ...
- 在centos linux上安装jdk7
在这里下载jdk7rpm安装包,并上传到centos服务器上http://www.oracle.com/technetwork/java/javase/downloads/java-se-jdk-7- ...