hadoop集群搭建简要记录
2019/03/09 21:46
准备4台服务器或者虚拟机【centos7】,分别设置好静态ip【之所以设置静态ip主要就是为了省心!!!】
【
centos7下面配置静态IP 参考地址: https://www.linuxidc.com/Linux/2017-10/147449.htm
cd /etc/sysconfig/network-scripts
ls
这里说一下需要修改的位置:
#修改
BOOTPROTO=static #这里讲dhcp换成ststic
ONBOOT=yes #将no换成yes
#新增
IPADDR=192.168.10.100 #静态IP
GATEWAY=192.168.10.2 #默认网关
NETMASK=255.255.255.0 #子网掩码
保存退出后,重启网络服务:
# service network restart
Restarting network (via systemctl):
】
master 192.168.10.100
slave1 192.168.10.101
slave2 192.168.10.102
slave 3 192.168.10.103
主机名分别是 node node1 node2 node3【后面会提到如何进行修改配置】
这里只以master服务器为例。【至于slave机器,可以考虑用虚拟机克隆去生成,简单方便】
安装jdk和hadoop,就是解压。
然后vim /etc/profile 去配置java和hadoop的环境变量。如下:
# jdk1.8 环境变量 2019/03/09 18:19 export JAVA_HOME=/usr/local/jdk1.8 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar # hadoop环境变量 2019/03/09 18:19 export HADOOP_HOME=/usr/local/hadoop2.2.0 export HADOOP_LOG_DIR=/usr/local/hadoop2.2.0/logs export YARN_LOG_DIR=$HADOOP_LOG_DIR export PATH=.:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
可以使用命令 hadoop 查看是否成功,参考类似 java -version的功能。
为hadoop的相应文件位置准备文件目录。比如临时生成文件的存储目录、日志信息存储位置、真正数据存储位置、文件系统元数据存储位置、集群数据位置。可以自定义创建对应的文件目录。注意:这些文件目录的路径后面配置要用到。

接下来修改hadoop的相关配置文件:
切换路径到hadoop主目录下的etc下的hadoop路径下:
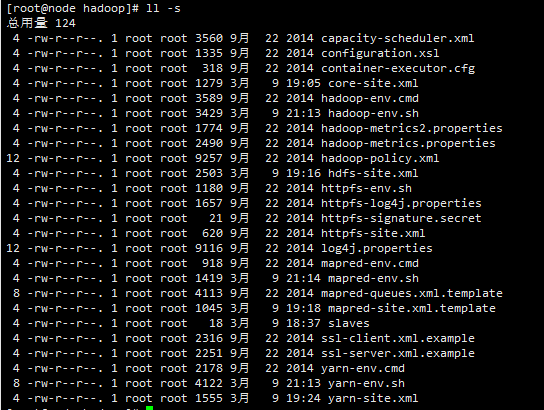
hadoop-env.sh yarn-env.sh mapred-env.sh 这三个文件里面,添加对jdk的引用,否则在启动hdfs的时候,会报异常:找不到java环境。
添加:export JAVA_HOME=/usr/local/jdk1.8 【 注意 和 /etc/profile 里面配置的java环境变量写法一致,使用绝对路径,最好直接拷贝过来】
vim slaves文件,里面添加slave节点的主机名。主机名的改法后面会说,
配置:core-site.xml【注意里面的路径参数结合自己的实际进行修改。相关路径就是上面让自定义创建的那些目录路径】
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node:9000/</value>
<description>设定namenode的主机名和端口</description>
</property>
<property>
<name>hadoop.temp.dir</name>
<value>/usr/local/hadoop2.2.0/tmp/hadoop-${user.name}</value>
<description>存储临时文件的目录</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
配置:hdfs-site.xml【注意里面的路径参数结合自己的实际进行修改。相关路径就是上面让自定义创建的那些目录路径】
<configuration> <property> <name>dfs.namenode.http-address</name> <value>node:50070</value> <description>NameNode地址和端口</description> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node1:50090</value> <description>SecondNameNode 地址和端口</description> </property> <property> <name>dfs.replication</name> <value>3</value> <description>设定HDFS存储文件的副本个数,默认为3</description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop2.2.0/hdfs/name</value> <description>namenode 用来 持续存储命名空间和交换日志的本地系统路径</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop2.2.0/hdfs/data</value> <description>DataNode在本地存储文件的目录列表</description> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///usr/local/hadoop2.2.0/hdfs/namesecondary</value> <description>设置secondarynamenode存储临时镜像的本地文件系统路径,如果这是一个用逗号分割的文件列表,则镜像将会冗余复制到所有目录</description> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> <description>是否允许网页浏览hdfs文件</description> </property> <property> <name>dfs.stream-buffer-size</name> <value>131072</value> <description> 默认4kb,作为hadoop的缓冲区,用于hadoop读取hdfs的文件和写hdfs的文件,好友map的输出都用到了这个缓冲区容量,对于现在硬件,可以设置为128kb(131072),甚至是1mb(太大的话map和reduce的内存溢出) </description> </property> </configuration>
配置:yarn-site.xml【注意里面的路径参数结合自己的实际进行修改。相关路径就是上面让自定义创建的那些目录路径】
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>node</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>node:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>node:8088</value> </property> </configuration>
接下来修改主机名:【centos7】
查看主机名以及相关设置
hostnamectl status --static 静态的
hostnamectl status --transient 瞬态的
hostnamectl status --pretty 灵活的
同时修改三种主机名:
sudo hostnamectl set-hostname <主机名,eg:node/node1/。。。>
绑定主机名和ip
vim /etc/hosts
添加:
192.168.10.100 node
192.168.10.101 node1
192.168.10.102 node2
192.168.10.103 node3
guanbi关闭防火墙:
systemctl stop firewalld.service
防止防火墙开机自启动:
systemctl disable firewalld.service
关于各个节点之间使用ssh进行免密通信的设置:很简单,这里不再赘述,网上很多,也很简单。
注意其他slave节点也要进行同样的配置。
最后:
HDFS
启动 start-dfs.sh
hadoop资源管理器 Yarn
启动 start-yarn.sh
JobHistory 历史任务管理器
启动 mr-jobhistory-daemon.sh start historyserver
关闭 同上,start改为stop
hadoop集群搭建简要记录的更多相关文章
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- Hadoop集群搭建-02安装配置Zookeeper
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- Hadoop集群搭建(五)~搭建集群
继上篇关闭防火墙之后,因为后面我们会管理一个集群,在VMware中不断切换不同节点,为了管理方便我选择xshell这个连接工具,大家也可以选择SecureCRT等工具. 本篇记录一下3台机器集群的搭建 ...
- Hadoop 集群搭建和维护文档
一.前言 -- 基础环境准备 节点名称 IP NN DN JNN ZKFC ZK RM NM Master Worker master1 192.168.8.106 * * * * * * maste ...
- Hadoop集群搭建(完全分布式版本) VMWARE虚拟机
Hadoop集群搭建(完全分布式版本) VMWARE虚拟机 一.准备工作 三台虚拟机:master.node1.node2 时间同步 ntpdate ntp.aliyun.com 调整时区 cp /u ...
- Hadoop集群搭建的详细过程
Hadoop集群搭建 一.准备 三台虚拟机:master01,node1,node2 时间同步 1.date命令查看三台虚拟机时间是否一致 2.不一致时间同步:ntpdate ntp.aliyun.c ...
- Hadoop 集群搭建
Hadoop 集群搭建 2016-09-24 杜亦舒 目标 在3台服务器上搭建 Hadoop2.7.3 集群,然后测试验证,要能够向 HDFS 上传文件,并成功运行 mapreduce 示例程序 搭建 ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
随机推荐
- XML解析,出现ClassCastException 原因
import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.Docum ...
- css 雪碧图
CSS Sprites在国内很多人叫css精灵,是一种网页图片应用处理方式.它允许你将一个页面涉及到的所有零星图片都包含到一张大图中去,这样一来,当访问 该页面时,载入的图片就不会像以前那样一幅一幅地 ...
- DOM 中 Property 和 Attribute 的区别(转)
property 和 attribute非常容易混淆,两个单词的中文翻译也都非常相近(property:属性,attribute:特性),但实际上,二者是不同的东西,属于不同的范畴. property ...
- 26、HDF5 文件格式简介
转载:庐州月光 http://www.cnblogs.com/xudongliang/p/6907733.html 三代测序下机的原始数据不再是fastq格式了,而是换成了hdf5 格式,在做三代数据 ...
- DNA甲基化及其测量方法(转)
转自声明的奥秘 www.lifeomics.com DNA甲基化与肿瘤发生: DNA甲基化水平和模式的改变是肿瘤发生的一个重要因素.这些变化包括CpG岛局部的高甲基化和基因组DNA低甲 ...
- python+selenium UI自动化不同浏览器之间的切换
class register(): ROBOT_LIBRARY_SCOPE = 'GLOBAL' def __init__(self): pass # m默认打开chrome def open_bro ...
- 22. CTF综合靶机渗透(十五)
靶机说明: Game of Thrones Hacking CTF This is a challenge-game to measure your hacking skills. Set in Ga ...
- kali linux学习笔记之系统定制及优化(附:中文输入法设置)
fix update flash plugin on kali rolling author:@kerker 0x00设置软件源 root@kali:~# vim /etc/apt/sources.l ...
- html5增强的页面元素
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- SpringBoot应用篇(一):自定义starter
一.码前必备知识 1.SpringBoot starter机制 SpringBoot中的starter是一种非常重要的机制,能够抛弃以前繁杂的配置,将其统一集成进starter,应用者只需要在mave ...