Hadoop集群搭建-02安装配置Zookeeper
这一篇接着记录集群搭建,开始安装配置zookeeper,它的作用是做集群的信息同步,zookeeper配置时本身就是一个独立的小集群,集群机器一般为奇数个,只要机器过半正常工作那么这个zookeeper集群就能正常工作,工作时自动选举一个leader其余为follower,所以最低是配置三台。
注意本篇文章的几乎所有操作如不标注,则默认为hadoop用户下操作
1.首先修改下上一篇写的批量脚本
复制一份,然后把ips内删除两台机器名,,只留下前三台即可,然后把几个脚本的名称啥的都改一下,和内部引用名都改一下。
可以用我改好的https://www.lanzous.com/b849762/ 密码:1qq6
2.安装zookeeper
可以用xshell的rz命令上传zookeeper安装包,安装包在这里https://www.lanzous.com/b849708/ 密码:8a10
[hadoop@nn1 ~]$ cd zk_op/
批量发送给三台机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/upload/zookeeper-3.4.8.tar.gz /tmp/
查看是否上传成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /tmp | grep zoo*"
批量解压到各自的/usr/local/目录下
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh tar -zxf /tmp/zookeeper-3.4.8.tar.gz -C /usr/local/
再次查看是否操作成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zoo*"
批量改变/usr/local/zookeeper-3.4.8目录的用户组为hadoop:hadoop
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chown -R hadoop:hadoop /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chmod -R 770 /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper-3.4.8"
批量创建软链接(可以理解为快捷方式)
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh ln - s /usr/local/zookeeper-3.4.8/ /usr/local/zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper"
这里软链接的用户组合权限可以不用修改,默认为root或者hadoop都可以。
修改/usr/local/zookeeper/conf/zoo.cfg
可以用我改好的https://www.lanzous.com/b849762/ 密码:1qq6
批量删除原有的zoo_sample.cfg文件,当然先备份为好
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh rm -f /usr/local/zookeeper/conf/zoo_sample.cfg
把我们准备好的配置文件放进去,批量。
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/zoo.cfg /usr/local/zookeeper/conf/
=================================================================================================
然后修改/usr/local/zookeeper/bin/zkEnv.sh脚本文件,添加日志文件路径
[hadoop@nn1 zk_op]$ vim /usr/local/zookeeper/bin/zkEnv.sh
ZOO_LOG_DIR=/data
把这个配置文件批量分发给其他机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /usr/local/zookeeper/bin/zkEnv.sh /usr/local/zookeeper/bin/
给5台机器创建/data目录,注意这里是给5台机器创建。用的没改过的原本批量脚本。
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh mkdir /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh chown hadoop:hadoop /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_all.sh "ls -l | grep data"
上面为啥是突然创建5个/data呢,,,因为后边的hdfs和yarn都需要,后边的hdfs是运行在后三台机器上的,所以现在直接都创建好。
然后回到zk_op中,给前三台机器创建id文件。用于zookeeper识别
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh touch /data/myid
然后_分别进三台机器_,给这个文件追加id值。
第一台:
echo "1" > /data/myid
第二台:
echo "2" > /data/myid
第三台:
echo "3" > /data/myid
3.批量设置环境变量
在nn1上切换到root用户更改系统环境变量
[hadoop@nn1 zk_op]$ su - root
[root@nn1 ~]# vim /etc/profile
文件在末尾添加
#set Hadoop Path
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:/usr/lib64
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin:/usr/local/zookeeper/bin
然后批量发送给其他两台机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /etc/profile /tmp/
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh cp -f /tmp/profile /etc/profile
批量检查一下
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh tail /etc/profile
批量source一下环境变量
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh source /etc/profile
4.批量启动zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh /usr/local/zookeeper/bin/zkServer.sh start
查看一下是否启动。看看有没有相关进程
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh jps
如下图查看进程,有QPM进程就说明启动成功
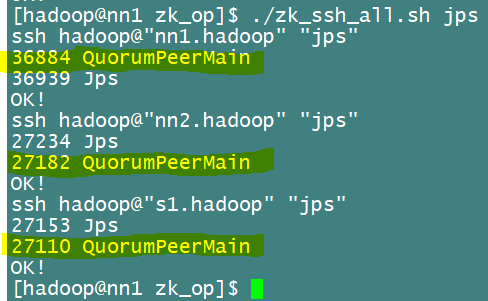
或者直接查看状态,
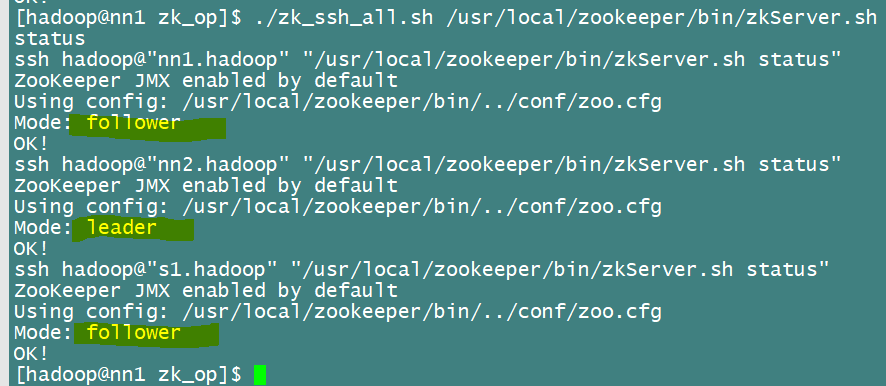
好了,zookeeper安装配置顺利结束!!!
Hadoop集群搭建-02安装配置Zookeeper的更多相关文章
- Hadoop集群搭建-05安装配置YARN
Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hadoop集群搭建-01前期准备 先保证集群5台虚 ...
- Hadoop集群搭建-04安装配置HDFS
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- 基于Hadoop集群搭建Hive安装与配置(yum插件安装MySQL)---linux系统《小白篇》
用到的安装包有: apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.49.tar.gz 百度网盘链接: 链接:https://pan.baid ...
- Linux下Hadoop集群环境的安装配置
1)安装Ubuntu或其他Linux系统: a)为减少错误,集群中的主机最好安装同一版本的Linux系统,我的是Ubuntu12.04. b)每个主机的登陆用户名也最好都一样,比如都是hadoop,不 ...
- Hadoop集群搭建(六)~安装JDK
前面集群的准备工作都做完了,本篇记录安装JDK,版本位1.8 1,在opt目录下创建software和module文件夹:software用来放安装包,module为安装目录 2,把JDK和hadoo ...
- Hadoop集群搭建的密钥配置SSH实现机制的配置(2)
[hadoop@weekend110 ~]$ ssh-keygen -t rsa 用来生产密钥对 Generating public/private rsa key pair. Enter file ...
- Hadoop集群搭建-虚拟机安装(转)(一)
1.软件准备 a).操作系统:CentOS-7-x86_64-DVD-1503-01 b).虚拟机:VMware-workstation-full-9.0.2-1031769(英文原版先安装) VM ...
- Hadoop集群搭建的密钥配置SSH实现机制
- Hadoop集群搭建-03编译安装hadoop
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
随机推荐
- 洛谷 P4933 大师
题面 (实名推荐:本题的出题人小哥哥打球暴帅哦!(APIO/CTSC/WC的时候一起打过球w,而且大学在我隔壁喔) ) 没仔细看数据范围的时候真是摸不着头脑...还以为要 O(N^2) dp 爆锤.. ...
- node中的http内置模块
Node.js开发的目的就是为了用JavaScript编写Web服务器程序.因为JavaScript实际上已经统治了浏览器端的脚本,其优势就是有世界上数量最多的前端开发人员.如果已经掌握了JavaSc ...
- 物联网是前端工程师的新蓝海吗? | Live笔记
物联网是继 Web .无线之后的又一次重大技术变革,在变革的大潮中,程序员的知识体系和思维方式将面临全面更新. 前端开发的历史 在准备这个live的过程中,我回顾了前端开发短暂的历史,有几次我认为非常 ...
- 2017 ZSTU寒假排位赛 #6
题目链接:https://vjudge.net/contest/149212#overview. A题,水题,略过. B题,水题,读清题意即可. C题,数学题,如果把x表示成x=nb+m,则k=n/m ...
- antd-mobile的DatePicker分钟精度半小时
项目要求,在时间选择上需要精确到分钟,且分钟只能半小时,既0分钟或者是30分钟. 前期引用的时间控件是antd-mobile的DatePicker组件,具体用法可参考:https://mobile.a ...
- appium中从activity切换到html
问题:混合开发的app中,会有内嵌的H5页面元素,该如何进行定位操作? 解决思路:appium中的元素定位都是基于android原生控件进行元素定位,而web网页是B/S架构,两者运行环境不同需要进行 ...
- HTTP中GET请求与POST请求的区别
GET和POST是HTTP请求的两种基本方法.最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数.但这只是表象,或者说只是现象,并不是核心.本文将细细谈谈对它们的 ...
- centos 下启动 rabbitmq 报错的解决
安装 rabbitmq 后进行了一些配置,然后启动服务: service rabbitmq-server start 无法启动.通过 journalctl -xe 查看日志后,有如下日志: ... - ...
- 002-tomcat目录简介、应用部署【自动部署 ② 控制台部署 ③ 自定义部署】
一.目录及功能 主目录下有bin,conf,lib,logs,temp,webapps,work 7个文件夹 1.1.bin目录[重要] bin目录主要是用来存放tomcat的命令,主要有两大类,一类 ...
- 你应该知道的 MySQL 的锁
背景 数据库的锁是在多线程高并发的情况下用来保证数据稳定性和一致性的一种机制.MySQL 根据底层存储引擎的不同,锁的支持粒度和实现机制也不同.MyISAM 只支持表锁,InnoDB 支持行锁和表锁. ...