--oracle 用户对象的导入导出
exp devimage/oracle@172.xx.x.xx/TESTDB owner='devimage' file=d:/devimage.dmp log=d:/devimage.log
imp wxtest5star03/123456@localhost/orcl FROMUSER='devimage' TOUSER='wxtest5star03' FILE=D:/devimage.dmp log=d:/wxtest5star03.log IGNORE=Y
--oracle 创建用户
create user devtest10 identified by dev10
default tablespace TBS_BCP_DAT
temporary tablespace user_temp;
grant connect,resource,dba to devtest10;
--oracle 创建表空间
create tablespace DATA_TESTKIDSWANT
logging
datafile 'E:\app\Administrator\oradata\orcl\ DATA_TESTKIDSWANT.dbf'
size 50m
autoextend on
next 50m maxsize 20480m
extent management local;
--Oracle 11G在用EXPORT导出时,空表不能导出。11G中有个新特性,当表无数据时,不分配segment,以节省空间
select 'alter table '||table_name||' allocate extent;' from user_tables where num_rows=0
SQL Select语句完整的执行顺序:
1、from子句组装来自不同数据源的数据;
2、where子句基于指定的条件对记录行进行筛选;
3、group by子句将数据划分为多个分组;
4、使用聚集函数进行计算;
5、使用having子句筛选分组;
6、计算所有的表达式;
7、使用order by对结果集进行排序。
8、select 集合输出。
--条件分支
select userid ,loginname ,email ,
case when email is null then 'null' when email is not null then 'not null'
end as status
from t_ac_user;
--获取前5行
select * from t_ac_user where rownum =1;
--获取随机数
select dbms_random.value() from dual;
--获取随机字符串
select dbms_random.string('A',5) from dual;
--获取任意五行
select * from (
select * from t_ac_user order by dbms_random.value()) where rownum <5;
--将空值转换成实际值
select userid ,loginname ,email ,coalesce(email,'0') from t_ac_user;
--将字符替换成指定字符
select translate(name,'bl','BX') from userinfo; 将b替换为B,将l替换为X;
--将字符中所有数字消除掉
select replace(translate(name,'0123456789','##########'),'#','') from userinfo;
--空值排序问题
select * from userinfo order by age nulls last; 或者nulls first;
--条件排序,商品表中当前销售的商品价钱 促销的时候为促销价,平时为正常价,按照当前销售价来排序
select goods_name, case when is_sell ='1' then price when is_sell = '0' then pricecx end as nowprice from t_bd_goods order by nowprice;
或者
select goods_name from t_bd_goods order by case when is_sell ='1' then price
when is_sell = '0' then pricecx
end ;
--oracle求交集,并集,差集 分别是 intersect,union all,minus,检索的字段类型一致。
select ename,job from emp
minus
select ename,job from empv;
--查询没有员工的部门信息 使用外联结
select d.* from dept d,emp e where d.deptno=e.deptno(+) and e.deptno is null;
--三张表联合查询 两张表内连接 然后和另外一个外联结 比如查询所有员工的姓名,部门名称,第二职业,有的没有第二职业,所以用外联结
select e.ename,d.dname,b.job from emp e,dept d,bonus b where e.deptno=d.deptno and e.ename = b.ename(+);
--如果有的部门没有员工,有的员工没有部门 这种情况要查询出所有的信息需要使用全连接
select d.deptno,e.ename from dept d full join emp e on d.deptno=e.deptno;
--复制表数据
insert into bonus2 select * from bonus;
--将元数据按条件分配到不同备份表中 insert all 和 insert first
insert all
when ename ='a' then
into bonus2 values(ename,job,sal,comm )
else
into bonus3 values(ename,job,sal,comm)
select * from bonus;
--检索 所有表 表中所有列 所有表中的索引列
select * from all_tables where owner = 'SCOTT';
select * from all_tab_columns where owner = 'SCOTT' and table_name = 'EMP';
select * from all_ind_columns where index_owner = 'SCOTT' and table_name='EMP';
--检索oracle所有视图的一个视图
select * from dictionary
--分组和窗口函数的使用 关于窗口函数 over() 的具体使用规则 另行百度。
查询每个部门的员工数
select deptno 部门,count(ename) 部门人数 from emp group by deptno;
在此基础上增加一列 显示公司总人数
select deptno 部门,count(ename) 部门人数,(select count(ename) from emp) 公司总人数 from emp group by deptno;
使用窗口函数,查询公司员工姓名,部门编号,公司总人数 三列数据
select ename,deptno,count(ename)over() 公司总人数 from emp order by 2;
查询公司员工姓名,部门编号,所在部门总人数 三列数据
select ename,deptno,count(ename)over(partition by deptno) 所在部门总人数 from emp order by 2;
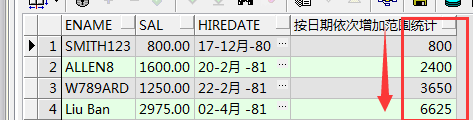
over内部可以使用order by 不仅表示排序 而且表示按照该排序进行范围依次扩大 来进行统计分析,如下
select ename,sal,hiredate,sum(sal)over() 所有员工工资总额 from emp;
select ename,sal,hiredate,sum(sal)over(partition by deptno) 所在部门工资总额 from emp;
select ename,sal,hiredate,sum(sal)over(order by hiredate) 按日期依次增加范围统计 from emp;
select ename,sal,hiredate,max(sal)over(order by hiredate) from emp;
有了窗口函数这种功能,可以很方便的写出一些比较使用的统计
统计emp表中每个部门的员工总数,每个部门的职位种类总数,再统计一列公司的总人数
select distinct deptno 部门,count(ename)over(partition by deptno) 每个部门员工数,
count(distinct job)over(partition by deptno) 职位种数,count(ename)over() 公司员工总数 from emp;
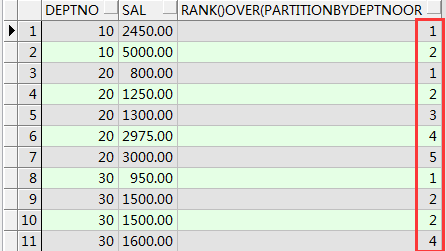
--rank()排名函数 按照窗口函数进行分组排序后,用rank进行排名 薪水相同的话 排名并列
select deptno,sal,rank()over(partition by deptno order by sal ) from emp order by deptno,sal;
select deptno,sal,dense_rank()over(partition by deptno order by sal ) from emp order by deptno,sal;
dense_rank函数排名 名次是连续的
时间的操作
select hiredate,
hiredate + 5, 五天后
hiredate - 5,五天前
add_months(hiredate, 5),五个月后
add_months(hiredate, -5),五个月前
add_months(hiredate, 5 * 12),五年后
add_months(hiredate, -5 * 12)五年前
from emp;
--日期相差的天数
select hiredate ,round(sysdate - hiredate) from emp;
--日期相差的月数 年数的话 除以十二
select hiredate,round(months_between(sysdate,hiredate)) from emp;
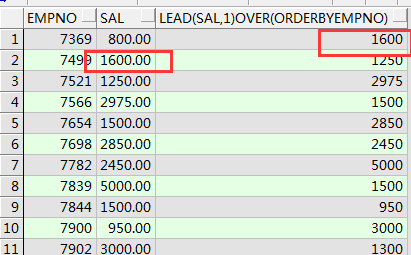
--lead函数 返回下一行的列值 lag表示返回上一行
select empno,sal,lead(sal,1)over(order by empno) from emp;
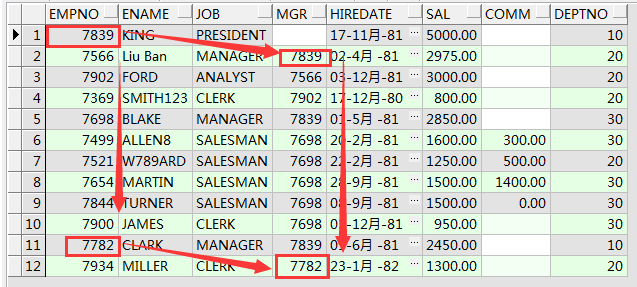
--递归查询
select * from emp start with empno =7839 connect by mgr = prior empno;
翻译过来就是
从empno=7839开始查,按照mgr等于上一条数据的empno的规则开始查。这个是向下递归
select * from emp start with empno=7900 connect by empno=prior mgr;
翻译过来就是
从empno=7900开始查,按照empno等于上一条的mgr规则查。这个是向上递归。
--having 分组的时候 可以对聚合函数的结果进行条件限制 where条件里面不能有聚合函数
select deptno,count(sal) co from emp group by deptno having count(sal) >2;
--有排序的分页的时候 可以使用row_number()over()分析函数 这个可以先排序 然后在分配序号值,普通的rownum是先分配rownum然后再去pga里排序
select * from (
select empno,ename,row_number()over(order by ename) as rn from emp)
where rn between 5*(2-1)+1 and 2*5;
--keep关键字
Min(col2)keep(dense_rank first order by col1)over (partition by col3) 按col3分组保留按col1排名各组第一的col2的最小值。
下面的这个就是

如果直接使用max(sal)over(partition by deptno)的话 是查询出部门中最大的工资 等于现在是需要先给雇佣日期排序 然后在查工资字段,分字段了,就得用这个了,其中使用max或者min是因为 dense_rank的时候 相同级别的 可能有多个
select deptno,sal,hiredate,max(hiredate)over(partition by deptno),
max(sal)keep(dense_rank first order by hiredate)over(partition by deptno)
from emp;
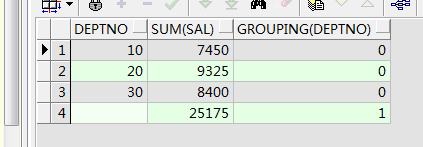
--group扩展 roolup grouping rollup表示要进行合计了,按照一个或者多个字段,grouping表示如果现在的这条数据是对这个字段进行rollup了 那么返回1 否则 返回0
select deptno,sum(sal),grouping(deptno) from emp group by rollup(deptno) order by deptno;
---sys_connect_by_path可以将树形结构行专列,配合start with connect by 使用 其中还有一个 伪列 level字段 表示深度
select level,
sys_connect_by_path( ename,'>>'),
sys_connect_by_path( job,'>>'),
job from emp start with empno=7369 connect by prior mgr = empno;
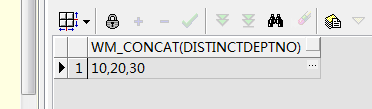
--- wm_concat函数,可以实现字段合并,效果如下,可以使用replace将逗号换掉
select wm_concat(distinct deptno) from emp;
行转列,列转行的行数11g还有pivot,unpivot函数可以使用。具体用法百度下吧。
大部分sql摘抄自《sql cookbook》一书。
- Oracle sql语句执行顺序
sql语法的分析是从右到左 一.sql语句的执行步骤: 1)词法分析,词法分析阶段是编译过程的第一个阶段.这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构 ...
- Oracle SQL语句追踪
Oracle SQL语句追踪 1 SQL语句追踪 追踪SQL语句的执行过程需要在Oracle服务器端进行,Oracle服务器端会检测并记录访问进程所执行的所有SQL语句.下面使用的命令都是在命令行 ...
- Oracle SQL语句执行过程
前言 QQ群讨论的时候有人遇到这样的问题:where子句中无法访问Oracle自定义的字段别名.这篇 博客就是就这一问题做一个探讨,并发散下思维,谈谈SQL语句的执行顺序问题. 问题呈现 直接给出SQ ...
- [转]关于oracle sql语句查询时表名和字段名要加双引号的问题
oracle初学者一般会遇到这个问题. 用navicat可视化创建了表,可是就是不能查到! 后来发现②语句可以查询到 ①select * from user; 但是,我们如果给user加上双引 ...
- Oracle SQL语句执行步骤
转自:http://www.cnblogs.com/quanweiru/archive/2012/11/09/2762345.html Oracle中SQL语句执行过程中,Oracle内部解析原理如下 ...
- oracle: sql语句报ora-01461/ora-00911错误
oracle: sql语句报ora-01461/ora-00911错误 ora-00911:sql语句中可能含有特殊字符,或者sql语句中不能用";"分号结尾. sql语句报ora ...
- 简单的oracle sql语句练习
简单的oracle sql语句练习 求每个部门的平均薪水 select deptno,avg(sal) from emp group by deptno 每个部门同一个职位的最大工资 select d ...
- Oracle sql语句中不支持boolean类型(decode&case)
[转自] http://blog.csdn.net/t0nsha/article/details/7828538 Oracle sql语句中不支持boolean类型(decode&case) ...
- oracle管理优化必备语句以及oracle SQL语句性能调整
本文转自http://www.dataguru.cn/article-3302-1.html oracle数据库管理优化必备语句: 1. SELECT T.START_TIME,T.USED_UBLK ...
随机推荐
- python数据分析之:数据聚合与分组运算
在数据库中,我们可以对数据进行分类,聚合运算.例如groupby操作.在pandas中同样也有类似的功能.通过这些聚合,分组操作,我们可以很容易的对数据进行转换,清洗,运算.比如如下图,首先通过不同的 ...
- xcode6
官方的xcode6下载太慢,这里送上百度网盘地址: http://pan.baidu.com/s/1hqze1hi
- docker swarm部署spring cloud服务
一.准备docker swarm的集群环境 ip 是否主节点 192.168.91.13 是 192.168.91.43 否 二.准备微服务 ①eureka服务 application.y ...
- Data Structure Binary Tree: Lowest Common Ancestor in a Binary Tree
http://www.geeksforgeeks.org/lowest-common-ancestor-binary-tree-set-1/ #include <iostream> #in ...
- 【leetcode刷题笔记】Next Permutation
Implement next permutation, which rearranges numbers into the lexicographically next greater permuta ...
- python 3 并发编程多进程 paramiko 模块
python 3 paramiko模块 paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的pa ...
- python中自定义排序函数
Python内置的 sorted()函数可对list进行排序: >>>sorted([36, 5, 12, 9, 21]) [5, 9, 12, 21, 36] 但 sorted() ...
- 开发rsync启动脚本
rsync rsync是类unix系统下的数据镜像备份工具——remote sync.一款快速增量备份工具 Remote Sync,远程同步 支持本地复制,或者与其他SSH.rsync主机同步. ...
- UNIDBgrid里动态添加clientevents实现回车替换TAB
//GRID里回车替换TABfunction cellkeydown(sender, td, cellIndex, record, tr, rowIndex, e, eOpts){ if (e.get ...
- 使用POI将doc文件转换为html
需要的jar包有:有一些是依赖包,可以使用maven下载 doc文件转换为html文件 package com.gsww.sxzz.controller.service; import org.apa ...