selenium + phantomjs 爬取落网音乐
题记:
作为一个业余程序猿,最大的爱好就是电影和音乐了,听音乐当然要来点有档次的。落网的音乐的逼格有点高,一听听了10年。学习python一久了,于是想用python技术把落网的音乐爬下来随便听。
目的:
将每一期的落网音乐下载到电脑上。
=====================================================================================
版本一:
刚开始,学习了爬虫技术中的urllib,urllib2,httplib,然后学习了用requests + beautifulsoup获取数据(python理念:能简单为啥还要复杂)。
于是,就有了这个版本。
图1:

图2:
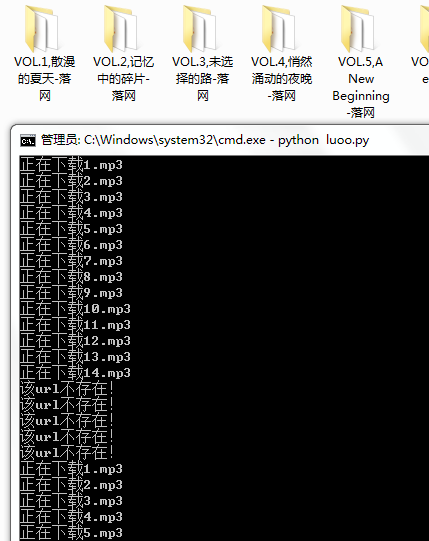
图3:
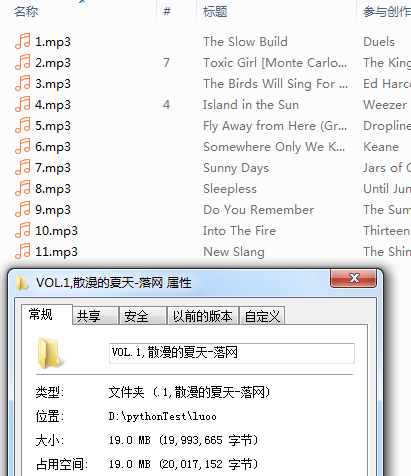
缺点:
1、从html元素查找title,再从request请求查看每一首音乐的url,这个半手动的违背了自动下载的初衷。
2、这个音乐url是规律的命名,如果不规律的话,便不能用了。
3、单线程下载,速度慢。
需要改进的地方:
1、音乐url应能自动在网页里搜索,而不需要手动查看request请求的header。
2、使用多线程。提高下载速度。
=================================================================
版本二:
分析:
1、打开落网每一期音乐的页面,查看源代码中,不能看到音乐的url,那判定该音乐是由js发起的请求。
2、要查看web页面中js发起的请求时,用requests模块只能获取静态的url,如果是动态的就没办法了。
3、通过搜索查阅,找到一款神器,selenium + phantomjs。
selenium是web自动化测试包,测试直接运行在浏览器中,就像真正的用户在操作一样,详见官网 http://www.seleniumhq.org。
phantomjs是基于webkit的javascript API,可以编译解释执行JavaScript代码。详见:官网 http://phantomjs.org。
webdriver api 见 http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webdriver。
4、Time fly,just do it。
在分析过程中,开始一直是requests模块的思维,由于落网的js是压缩过的,想到解压js,再查找相关的dom元素,再进行webElement的click提交,查看请求,但是这种方法一直没有结果。用了chrome 及 opera 的开发者工具,仍然无果。
换个思路,用了firefox的firebug试试。打开页面后,发现这个东西:
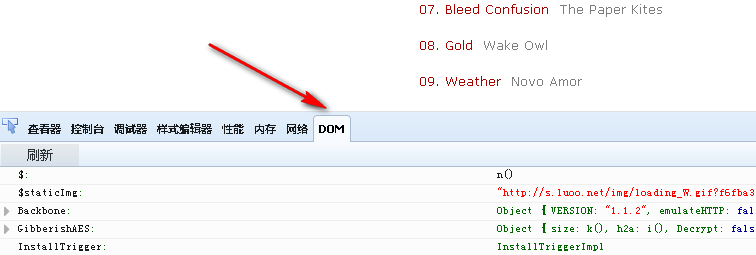
看了看内容,这就是js对象呀。再仔细查看,找到了这个:

哎哟,这不就是我要找的东西么,真是破铁鞋无觅处、得来全不费工夫呀。。。
但是,如果通过代码得到这个东西呢,一直没想到好的办法(业余菜鸟,对http请求了解太少)。
偶然看到这篇帖子:http://blog.csdn.net/pushiqiang/article/details/51290509
里面有一句代码得到启发:

这是返回js变量,那我需要的代码变量应用就是firebug里的luooPlayer了。
测试:

得到结果:
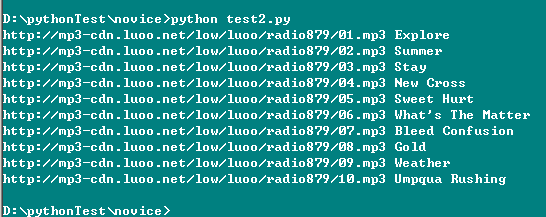
终于,主要的内容搞定。那接下来就是download每一期了,再加上多线程,就能下载了。
代码:
#coding:utf-8
'''
Auth:daivlin
Date:2016-12-22
''' import os
import time
import urllib
import threading
from selenium import webdriver class Luoo(object):
def __init__(self,issue):
''' init ,参数为期数 '''
self.issue_url = r"http://www.luoo.net/music/" + "%03d"%issue
driver = webdriver.PhantomJS()
driver.get(self.issue_url) #每期名称如: VOL666 欢迎来到巴黎
self.issue_name = "VOL." + "%03d"%issue + " " + driver.title
luooPlayer = driver.execute_script("return luooPlayer") #读取js变量 #音乐列表为元组:(name,url)
self.music_list = []
var = 1
for i in luooPlayer["playlist"]:
self.music_list.append(("%02d"%var,i["mp3"]))
var += 1
driver.quit() def get_issue_name(self):
''' 获取期刊号 '''
return self.issue_name def get_music_list(self):
''' 获取音乐列表 '''
return self.music_list class DownloadThread(threading.Thread):
''' 下载线程'''
def __init__(self,dirname,name,url):
super(DownloadThread,self).__init__()
self.dirname = dirname
self.name = name
self.url = url def run(self):
''' 下载音乐 '''
ABSPATH = os.path.dirname(os.path.realpath(__file__))
DOWNDIR = os.path.join(os.path.join(ABSPATH,"Luoo"),"%s"%self.dirname)
MUSICPATH = os.path.join(DOWNDIR,"%s.mp3"%self.name)
try:
os.mkdir(DOWNDIR)
except:
pass
if not os.path.exists(MUSICPATH):
urllib.urlretrieve(self.url, MUSICPATH)
print "%s.mp3 was downloaded"%self.name for i in range(867,888):
r = Luoo(i)
name = r.get_issue_name()
tds = []
for j in r.get_music_list():
tds.append(DownloadThread(name,j[0],j[1]))
print "start download %s"%name
for td in tds:
td.start()
for tj in tds:
tj.join()
print "%s download complate"%name
print "=========================" print "All have downloaded"
下载效果:
待改进的地方:
1、因为编码问题报错,文件名称用序号代替,需改为真实音乐名称。
==============================================================================
webdriver执行js代码,得到返回的值代码如下:
jscode = '''
var img_src = $("img.vol-cover");
return img_src.attr("src");
'''
img_cover = driver.execute_script(jscode)
==============================================================================
爬虫只供参考
做个厚道的程序猿
别增加人家的服务器压力
==============================================================================
人生苦短,我用python!
selenium + phantomjs 爬取落网音乐的更多相关文章
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页
Python3.x:Selenium+PhantomJS爬取带Ajax.Js的网页 前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但 ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- selenium+phantomjs爬取bilibili
selenium+phantomjs爬取bilibili 首先我们要下载phantomjs 你可以到 http://phantomjs.org/download.html 这里去下载 下载完之后解压到 ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- selenium + PhantomJS 爬取js页面
from selenium import webdriver import time _url="http://xxxxxxxx.com" driver = webdriver.P ...
- Selenium+PhantomJs 爬取网页内容
利用Selenium和PhantomJs 可以模拟用户操作,爬取大多数的网站.下面以新浪财经为例,我们抓取新浪财经的新闻版块内容. 1.依赖的jar包.我的项目是普通的SSM单间的WEB工程.最后一个 ...
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页及获取JS返回值
前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但是网页的DOM元素内容却可以动态的变化.如果处理这种网页是还用requests库或者 ...
- 看我怎么扒掉CSDN首页的底裤(python selenium+phantomjs爬取CSDN首页内容)
这里只是学习一下动态加载页面内容的抓取,并不适用于所有的页面. 使用到的工具就是python selenium和phantomjs,另外调试的时候还用了firefox的geckodriver.exe. ...
- selenium+phantomjs爬取动态页面数据
1.安装selenium pip/pip3 install selenium 注意依赖关系 2.phantomjs for windows 下载地址:http://phantomjs.org/down ...
随机推荐
- STM32启动代码分析 IAR 比较好
stm32启动代码分析 (2012-06-12 09:43:31) 转载▼ 最近开始使用ST的stm32w108芯片(也是一款zigbee芯片).开始看他的启动代码看的晕晕呼呼呼的. 还好在c ...
- 安装在CloudStack时CentOS6.4中安装MySQL通过mysql_secure_installation方式修改密码
在安装CloudStack时,通过mysql_secure_installation方式修改密码 01 [root@test ~]# /usr/bin/mysql_secure_installatio ...
- OpenMP共享内存并行编程详解
实验平台:win7, VS2010 1. 介绍 平行计算机可以简单分为共享内存和分布式内存,共享内存就是多个核心共享一个内存,目前的PC就是这类(不管是只有一个多核CPU还是可以插多个CPU,它们都有 ...
- 实现TCP、UDP相互通信及应用
实验名称 Socket编程综合实验(1) 一.实验目的: 1.理解进程通信的原理及通信过程 2.掌握基于TCP和UDP的工作原理 3.掌握基本的Socket网络编程原理及方法 二.实验内容 1.掌握 ...
- python 使用总结
本人原来是编写java的,后来转到编写ios之后,最后又来编写python了.相对于其他的一些开发人员来说,我精通的语言还是比较杂的. 这里将几个语言进行类比,比较一些个人的看法的东西. 首先obje ...
- (转)实例简述Spring AOP之间对AspectJ语法的支持(转)
Spring的AOP可以通过对@AspectJ注解的支持和在XML中配置来实现,本文通过实例简述如何在Spring中使用AspectJ.一:使用AspectJ注解:1,启用对AspectJ的支持:通过 ...
- applicationCache对象
applicationCache对象代表了本地缓存,可以在js中进行一些操作.可以用它来通知用户本地缓存中已经被更新,也允许用户手工更新本地缓存.applicationCache.addEventLi ...
- Enum.GetHashCode()的问题
先说一下,正常如果代码可以定义成枚举,我是比较倾向于定义成枚举的,类似这样: public enum Gender { /// <summary> /// 男 /// </summa ...
- InfoPi运行机制介绍
整体工作框架 文件目录结构 数据库设计 程序开发框架 注:图片可能被自动缩小,可以另存看大图 1.整体工作框架. 通用户关注绿色竖线左侧的内容即可 2.InfoPi的文件目录结构. 请留意一下cfg目 ...
- Android学习十二:跑马灯程序实现(简单联系)
package org.tonny; import java.util.Timer; import java.util.TimerTask; import android.app.Activity; ...