Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页及获取JS返回值
前言
现在很多网站的都大量使用JavaScript,或者使用了Ajax技术。这样在网页加载完成后,url虽然不改变但是网页的DOM元素内容却可以动态的变化。如果处理这种网页是还用requests库或者python自带的urllib库那么得到的网页内容和网页在浏览器中显示的内容是不一致的。
解决方案
使用Selenium+PhantomJS。这两个组合在一起,可以运行非常强大的爬虫,可以处理cookie,JavaScript,header以及其他你想做的任何事情。
安装第三方库
Selenium是一个强大的网络数据采集工具,最初是为网站自动化测试开发的,其有对应的Python库;
Selenium安装命令:
pip install selenium
安装PhantomJS
PhantomJS是一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现。通过编写js程序可以直接与webkit内核交互,在此之上可以结合java语言等,通过java调用js等相关操作。需要去官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:http://phantomjs.org/download.html,按照不同的系统选择相应的版本
对windows系统来说,下载PhantomJs 然后将 解压后的执行文件放在被设置过环境变量的地方,不设置的话,后续代码就要设, 所以这里直接放进来方便;

然后检测下,在cmd窗口输入phantomjs:

出现这样的画面,即表示成功;
对Mac系统来说,下载后保存到一个路径中,可以直接保存在环境变了路径中,也可以在环境变量路径中创建一个指向phantomjs的软连接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)
能成功获取到页面元素即为安装成功
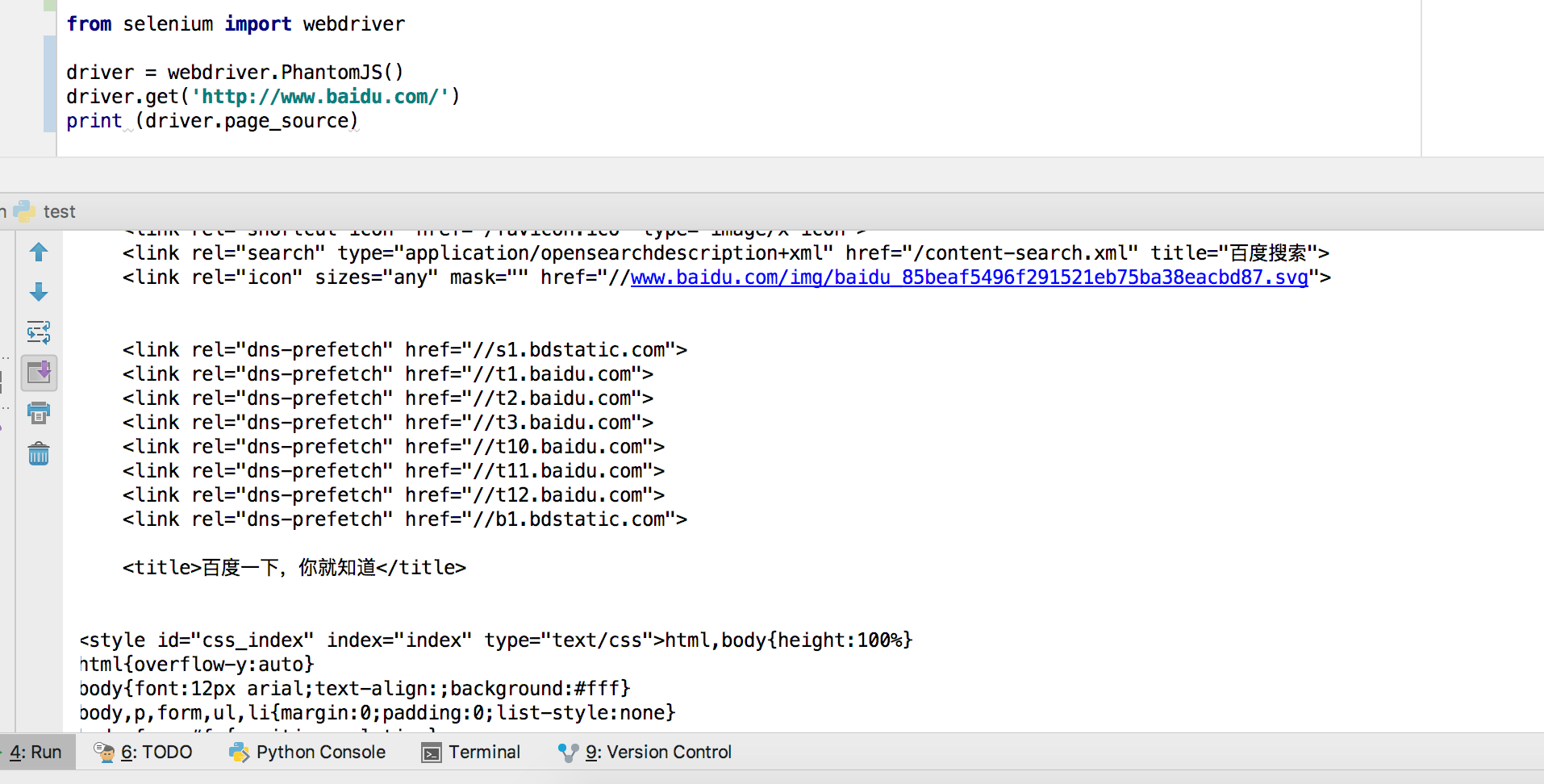
示例一:
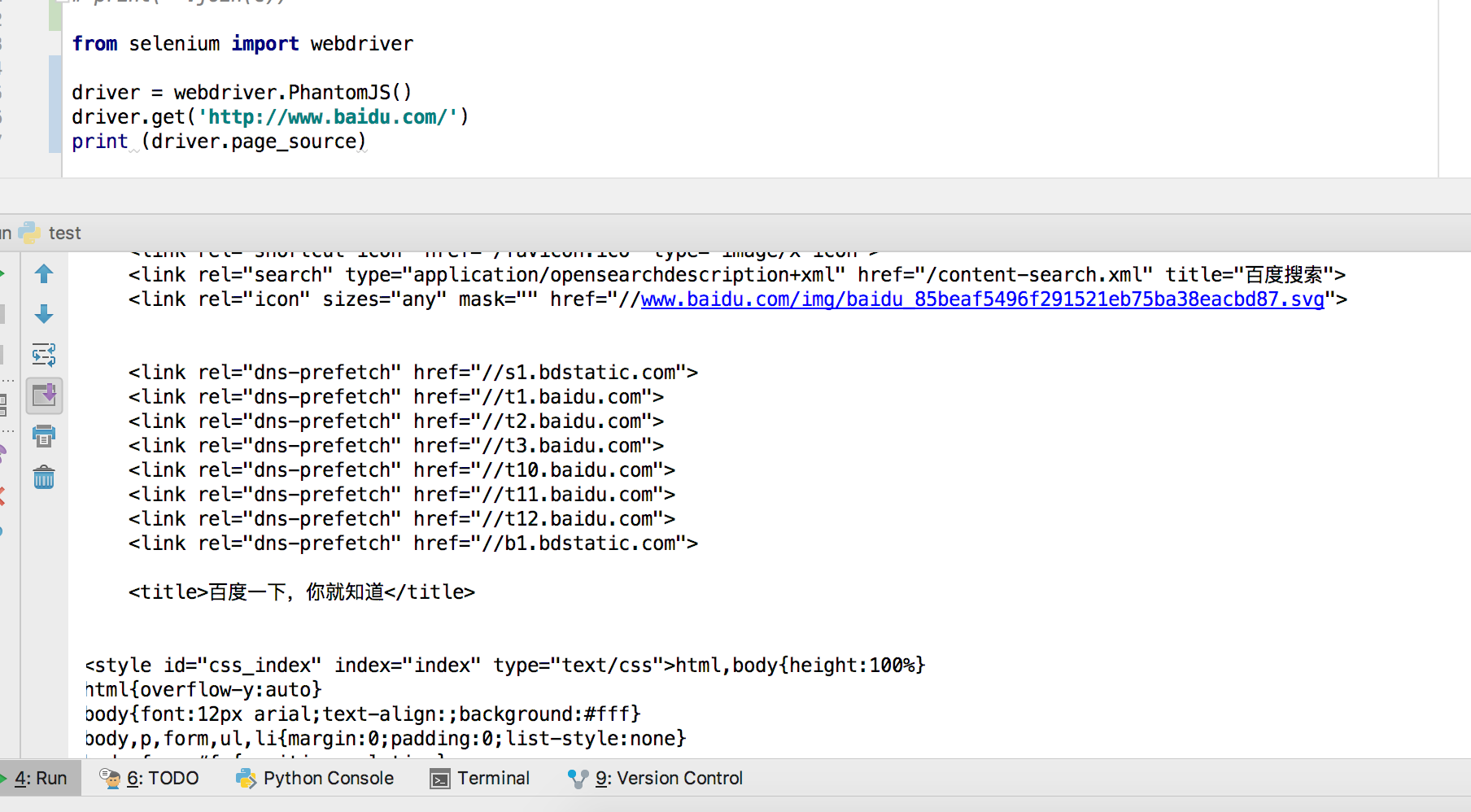
Selenium+PhantomJS示例代码:
from selenium import webdriver driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()
能输出网页源码,说明安装成功
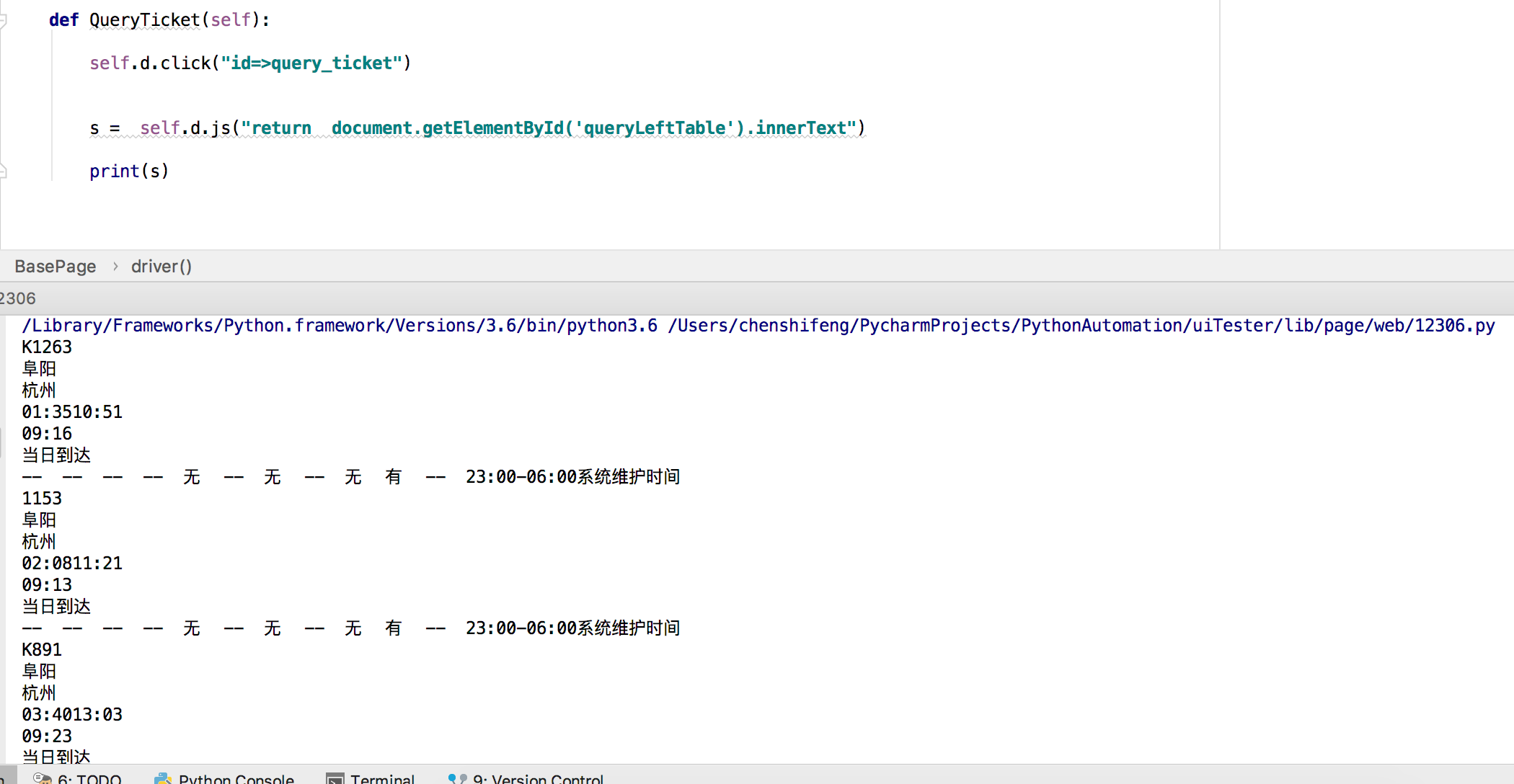
获取JS返回值
Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页及获取JS返回值的更多相关文章
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页
Python3.x:Selenium+PhantomJS爬取带Ajax.Js的网页 前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但 ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- selenium+phantomjs爬取bilibili
selenium+phantomjs爬取bilibili 首先我们要下载phantomjs 你可以到 http://phantomjs.org/download.html 这里去下载 下载完之后解压到 ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- selenium + PhantomJS 爬取js页面
from selenium import webdriver import time _url="http://xxxxxxxx.com" driver = webdriver.P ...
- Selenium+PhantomJs 爬取网页内容
利用Selenium和PhantomJs 可以模拟用户操作,爬取大多数的网站.下面以新浪财经为例,我们抓取新浪财经的新闻版块内容. 1.依赖的jar包.我的项目是普通的SSM单间的WEB工程.最后一个 ...
- selenium + phantomjs 爬取落网音乐
题记: 作为一个业余程序猿,最大的爱好就是电影和音乐了,听音乐当然要来点有档次的.落网的音乐的逼格有点高,一听听了10年.学习python一久了,于是想用python技术把落网的音乐爬下来随便听. 目 ...
- 看我怎么扒掉CSDN首页的底裤(python selenium+phantomjs爬取CSDN首页内容)
这里只是学习一下动态加载页面内容的抓取,并不适用于所有的页面. 使用到的工具就是python selenium和phantomjs,另外调试的时候还用了firefox的geckodriver.exe. ...
- selenium+phantomjs爬取动态页面数据
1.安装selenium pip/pip3 install selenium 注意依赖关系 2.phantomjs for windows 下载地址:http://phantomjs.org/down ...
随机推荐
- Android Stuido代码混淆
一.Android Studio 代码混淆基本配置首先我们要在build.gradle里设置 miifyEnabled 里改为true,表示可以混淆 proguardFiles getDefaultP ...
- Android解析XML文件
XML文件和获取XML值 XML文件样例 <?xml version="1.0" encoding="utf-8"?> <citys> ...
- typescritp 导出默认接口
假如有ITest.ts文件,如下: export default interface ITest{ } 这样会报错,编译不通过.据说是设计成这样的,具体详细见:https://github.com/M ...
- oracle 数据库 导出与导入 expdb和impdb使用方法 (服务器本机)
expdb 与exp 导出数据有区异,exp 无法导出空值表,用于客户端,expdb 只用于服务器端.备份出来的数据可再远程传输到另外一台linux 实现异地备份! 一 关于expdp和impdp ...
- 用Python实现数据结构之优先级队列
优先级队列 如果我们给每个元素都分配一个数字来标记其优先级,不妨设较小的数字具有较高的优先级,这样我们就可以在一个集合中访问优先级最高的元素并对其进行查找和删除操作了.这样,我们就引入了优先级队列 这 ...
- 修改css的(屏蔽)overflow: hidden;实现浏览器能把网页全图保存成图片
摘要: 1.项目需要,需要对网页内容“下载”保存成全图片 2.QQ浏览器等主流浏览器都支持这种下载保存功能 3.项目需要场景:编写好的项目维护文档,放在服务器上.如果是txt不能带图片可视化,如果wo ...
- February 3rd, 2018 Week 5th Saturday
Life takes on the meaning that you give it. 你赋予生活什么,生活就是什么样子. I always wonder why on earth I am here ...
- Ulua对象管理方式
不管是C++中还是在C#中,在都绕不开一个问题:类对象怎么在Lua中使用的问题,还好Lua提供了Userdata以及ligh Userdata结构类型,通过扩展可以处理这方面的问题.现在的很多框架也大 ...
- Html body的滚动条禁止与启用
在写一个在页面中,经验证用户没有登录或session失效时候弹出登录框禁止页面滚动用到今天搞了一个功能,上下左右居中,模仿QQ空间里的样式,把横向和纵向滚动条禁止掉代码如下:<script ty ...
- 描述各自页面的 page
一个小程序页面由四个文件组成(注意:为了方便开发者减少配置项,描述页面的四个文件必须具有相同的路径与文件名).分别是: 页面 Page(JS文件) Page(Object) 函数用来注册一个页面.接受 ...