Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》获取
1、 安装IntelliJ IDEA
IDEA 全称 IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
IDEA每个版本提供Community和Ultimate两个版本,如下图所示,其中Community是完全免费的,而Ultimate版本可以使用30天,过这段时间后需要收费。从安装后使用对比来看,下载一个Community版本足够了。
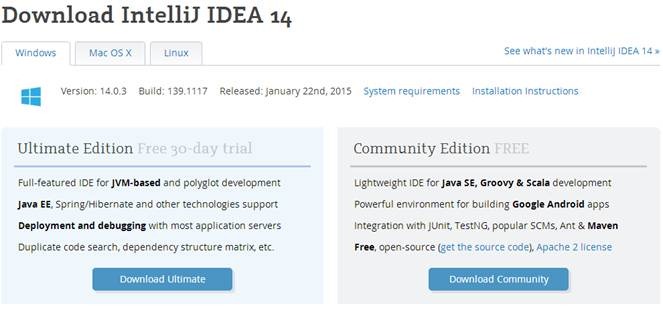
1.1 安装软件
1.1.1 下载IDEA安装文件
可以到Jetbrains官网http://www.jetbrains.com/idea/download/,选择最新的安装文件。由于以后的练习需要在Linux开发Scala应用程序,选择Linux系统IntelliJ IDEA14,如下图所示:
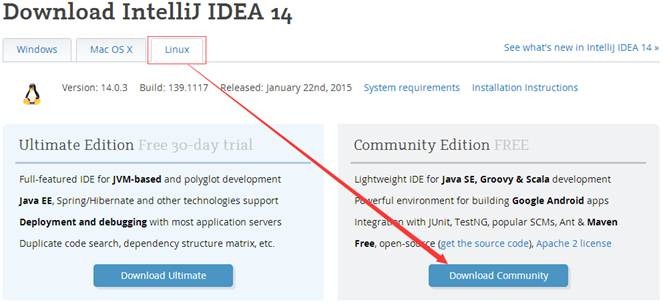
【注】在该系列配套资源的install目录下分别提供了ideaIC-14.0.2.tar.gz(社区版)和ideaIU-14.0.2.tar.gz(正式版)安装文件,对于Scala开发来说两个版本区别不大
1.1.2 解压缩并移动目录
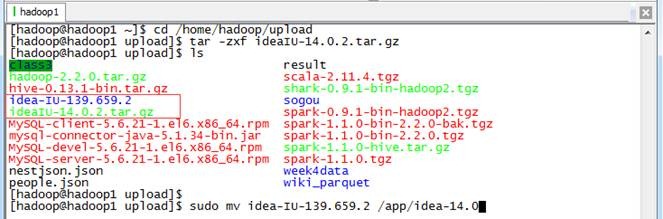
把下载的安装文件上传到目标机器,用如下命令解压缩IntelliJ IDEA安装文件,并迁移到/app目录下:
cd /home/hadoop/upload
tar -zxf ideaIU-14.0.2.tar.gz
sudo mv idea-IU-139.659.2 /app/idea-IU
1.1.3配置/etc/profile环境变量
使用如下命令打开/etc/profile文件:
sudo vi /etc/profile
确认JDK配置变量正确配置(参见第2节《Spark编译与部署》中关于基础环境搭建介绍):
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export PATH=$PATH:$JAVA_HOME

1.2 配置Scala环境
1.2.1 启动IntelliJ IDEA
可以通过两种方式启动IntelliJ IDEA:
l 到IntelliJ IDEA安装所在目录下,进入bin目录双击idea.sh启动IntelliJ IDEA;
l 在命令行终端中,进入$IDEA_HOME/bin目录,输入./idea.sh进行启动
IDEA初始启动目录如下,IDEA默认情况下并没有安装Scala插件,需要手动进行安装,安装过程并不复杂,下面将演示如何进行安装。

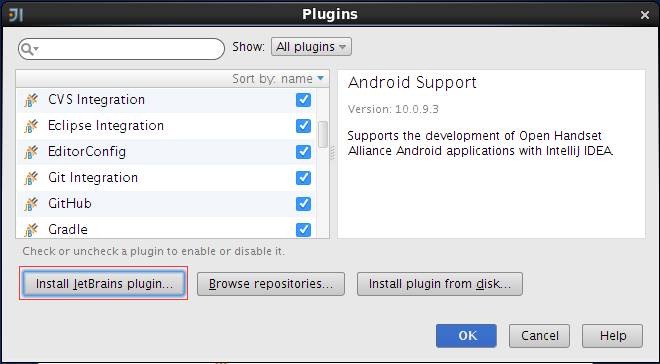
1.2.2 下载Scala插件
参见上图,在启动界面上选择“Configure-->Plugins"选项,然后弹出插件管理界面,在该界面上列出了所有安装好的插件,由于Scala插件没有安装,需要点击”Install JetBrains plugins"进行安装,如下图所示:
待安装的插件很多,可以通过查询或者字母顺序找到Scala插件,选择插件后在界面的右侧出现该插件的详细信息,点击绿色按钮"Install plugin”安装插件,如下图所示:
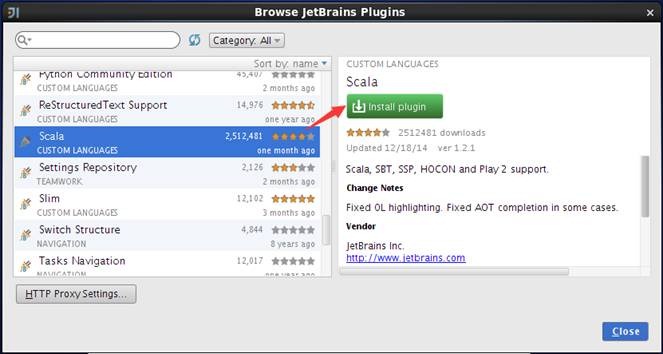
安装过程将出现安装进度界面,通过该界面了解插件安装进度,如下图所示:
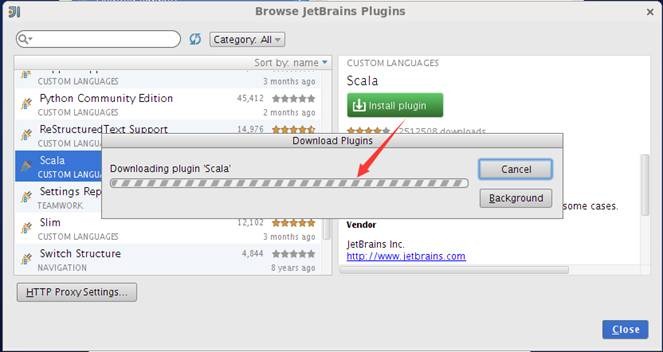
安装插件后,在启动界面中选择创建新项目,弹出的界面中将会出现"Scala"类型项目,选择后将出现提示创建的项目是仅Scala代码项目还是SBT代码项目,如下图所示:

1.2.3 设置界面主题
从IntelliJ IDEA12开始起推出了Darcula 主题的全新用户界面,该界面以黑色为主题风格得到很多开发人员的喜爱,下面我们将介绍如何进行配置。在主界面中选择File菜单,然后选择Setting子菜单,如下图所示:

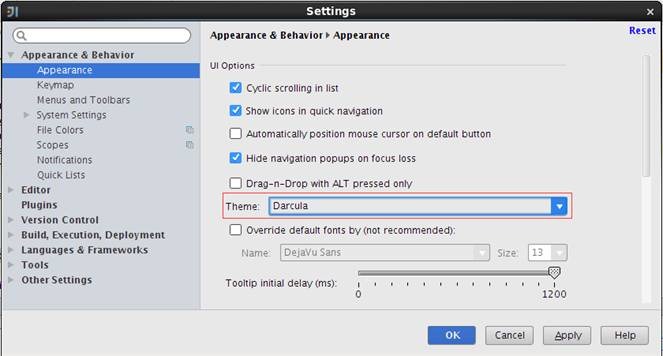
在弹出的界面中选择Appearance &Behavior中Appearance,其中Theme中选择Darcula主题,如下图所示:
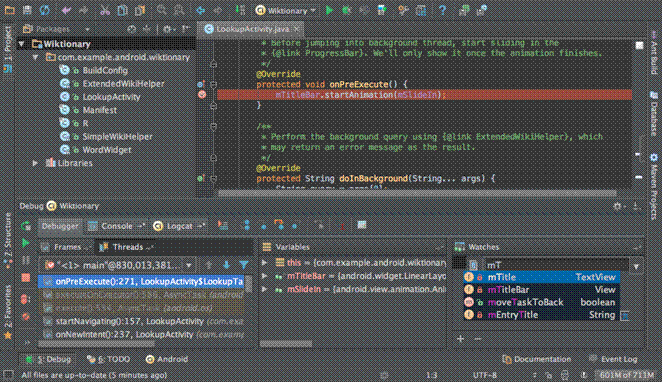
保存该主题重新进入,可以看到如下图样式的开发工具,是不是很酷!
2 使用IDEA编写例子
2.1 创建项目
2.1.1 设置项目基本信息
在IDEA菜单栏选择File->New Project,出现如下界面,选择创建Scala项目:
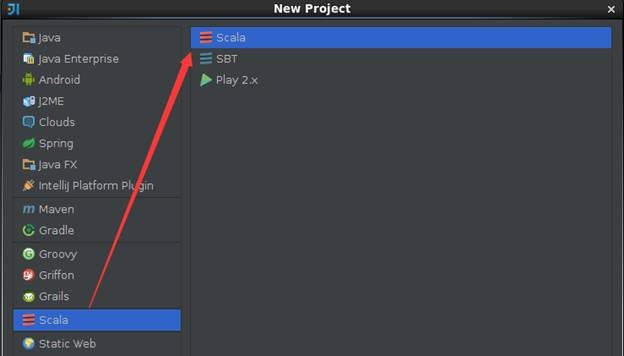
在项目的基本信息填写项目名称、项目所在位置、Project SDK和Scala SDK,在这里设置项目名称为class3,关于Scala SDK的安装参见第2节《Spark编译与部署》下Spark编译安装介绍:
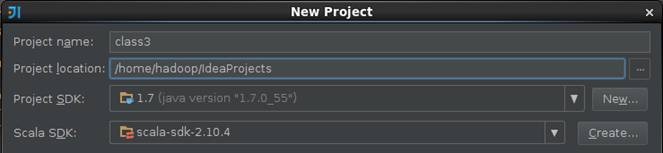
2.1.2 设置Modules
创建该项目后,可以看到现在还没有源文件,只有一个存放源文件的目录src以及存放工程其他信息的杂项。通过双击src目录或者点击菜单上的项目结构图标打开项目配置界面,如下图所示:
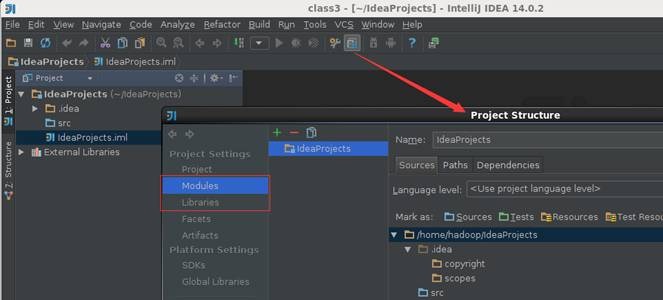
在Modules设置界面中,src点击右键选择“新加文件夹”添加src->main->scala目录:
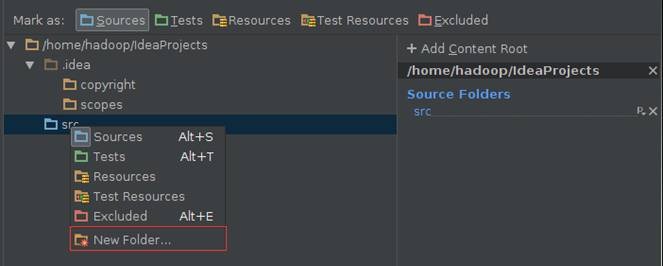
在Modules设置界面中,分别设置main->scala目录为Sources类型:
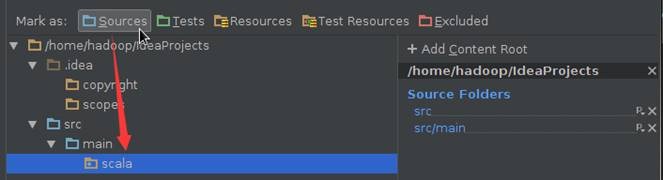
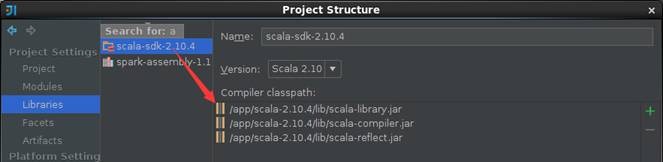
2.1.3 配置Library
选择Library目录,添加Scala SDK Library,这里选择scala-2.10.4版本
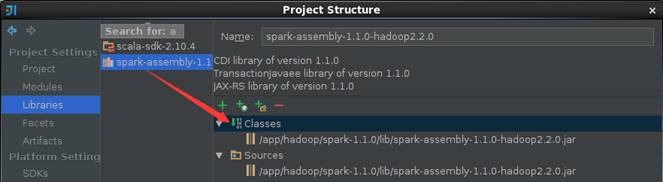
添加Java Library,这里选择的是在$SPARK_HOME/lib/spark-assembly-1.1.0-hadoop2.2.0.jar文件,添加完成的界面如下:
2.2 例子1:直接运行
《Spark编程模型(上)--概念及Shell试验》中使用Spark-Shell进行了搜狗日志的查询,在这里我们使用IDEA对Session查询次数排行榜进行重新练习,可以发现借助专业的开发工具可以方便快捷许多。
2.2.1 编写代码
在src->main->scala下创建class3包,在该包中添加SogouResult对象文件,具体代码如下:
package class3 import org.apache.spark.SparkContext._
import org.apache.spark.{SparkConf, SparkContext} object SogouResult{
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SogouResult <file1> <file2>")
System.exit(1)
} val conf = new SparkConf().setAppName("SogouResult").setMaster("local")
val sc = new SparkContext(conf) //session查询次数排行榜
val rdd1 = sc.textFile(args(0)).map(_.split("\t")).filter(_.length==6)
val rdd2=rdd1.map(x=>(x(1),1)).reduceByKey(_+_).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
rdd2.saveAsTextFile(args(1))
sc.stop()
}
}
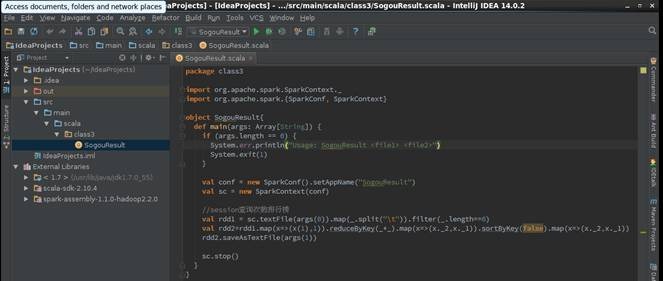
2.2.2 编译代码
代码在运行之前需要进行编译,可以点击菜单Build->Make Project或者Ctrl+F9对代码进行编译,编译结果会在Event Log进行提示,如果出现异常可以根据提示进行修改
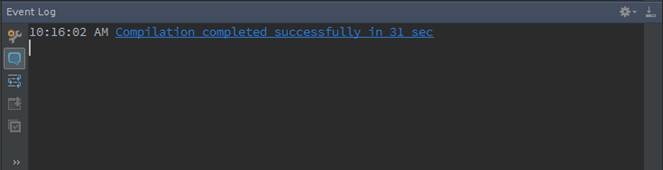
2.2.3 运行环境配置
SogouResult首次运行或点击菜单Run->Edit Configurations打开"运行/调试 配置界面"
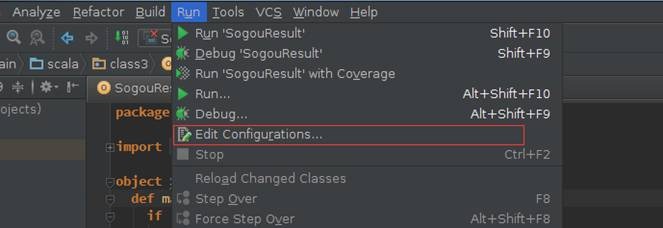
运行SogouResult时需要输入搜狗日志文件路径和输出结果路径两个参数,需要注意的是HDFS的路径参数路径需要全路径,否则运行会报错:
l 搜狗日志文件路径:使用上节上传的搜狗查询日志文件hdfs://hadoop1:9000/sogou/SogouQ1.txt
l 输出结果路径:hdfs://hadoop1:9000/class3/output2
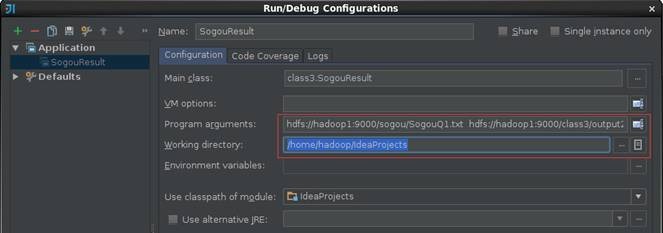
2.2.4 运行结果查看
启动Spark集群,点击菜单Run->Run或者Shift+F10运行SogouResult,在运行结果窗口可以运行情况。当然了如果需要观察程序运行的详细过程,可以加入断点,使用调试模式根据程序运行过程。
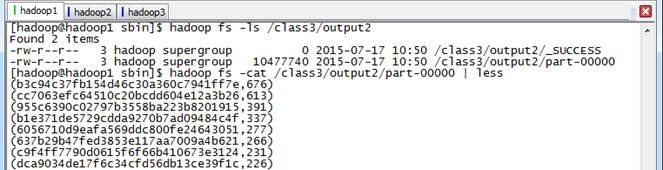
使用如下命令查看运行结果,该结果和上节运行的结果一致
hadoop fs -ls /class3/output2
hadoop fs -cat /class3/output2/part-00000 | less
2.3 例子2:打包运行
上个例子使用了IDEA直接运行结果,在该例子中将使用IDEA打包程序进行执行
2.3.1 编写代码
在class3包中添加Join对象文件,具体代码如下:
package class3 import org.apache.spark.SparkContext._
import org.apache.spark.{SparkConf, SparkContext} object Join{
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: Join <file1> <file2>")
System.exit(1)
} val conf = new SparkConf().setAppName("Join").setMaster("local")
val sc = new SparkContext(conf) val format = new java.text.SimpleDateFormat("yyyy-MM-dd")
case class Register (d: java.util.Date, uuid: String, cust_id: String, lat: Float,lng: Float)
case class Click (d: java.util.Date, uuid: String, landing_page: Int)
val reg = sc.textFile(args(0)).map(_.split("\t")).map(r => (r(1), Register(format.parse(r(0)), r(1), r(2), r(3).toFloat, r(4).toFloat)))
val clk = sc.textFile(args(1)).map(_.split("\t")).map(c => (c(1), Click(format.parse(c(0)), c(1), c(2).trim.toInt)))
reg.join(clk).take(2).foreach(println) sc.stop()
}
}
2.3.2 生成打包文件
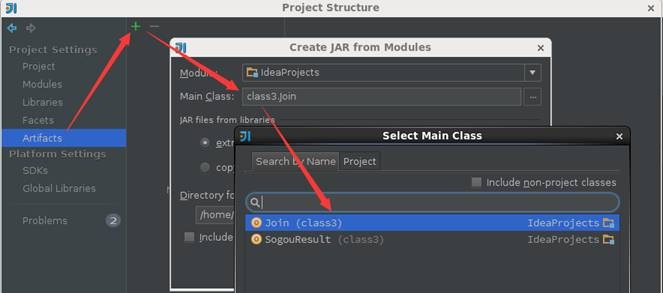
第一步 配置打包信息
在项目结构界面中选择"Artifacts",在右边操作界面选择绿色"+"号,选择添加JAR包的"From modules with dependencies"方式,出现如下界面,在该界面中选择主函数入口为Join:
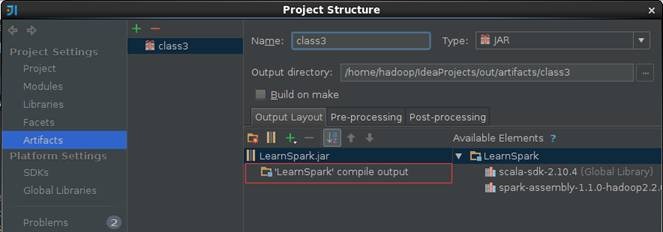
第二步 填写该JAR包名称和调整输出内容
【注意】的是默认情况下"Output Layout"会附带Scala相关的类包,由于运行环境已经有Scala相关类包,所以在这里去除这些包只保留项目的输出内容
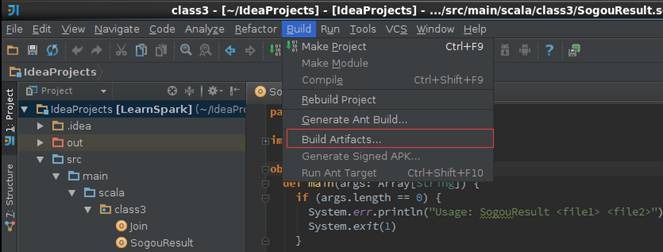
第三步 输出打包文件
点击菜单Build->Build Artifacts,弹出选择动作,选择Build或者Rebuild动作
第四步 复制打包文件到Spark根目录下
cd /home/hadoop/IdeaProjects/out/artifacts/class3
cp LearnSpark.jar /app/hadoop/spark-1.1.0/
ls /app/hadoop/spark-1.1.0/

2.3.3 运行查看结果
通过如下命令调用打包中的Join方法,运行结果如下:
cd /app/hadoop/spark-1.1.0
bin/spark-submit --master spark://hadoop1:7077 --class class3.Join --executor-memory 1g LearnSpark.jar hdfs://hadoop1:9000/class3/join/reg.tsv hdfs://hadoop1:9000/class3/join/clk.tsv
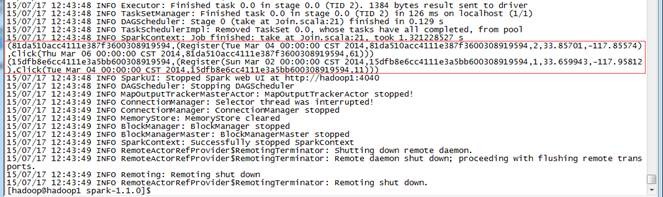
3、问题解决
3.1 出现"*** is already defined as object ***"错误
编写好SogouResult后进行编译,出现"Sogou is already as object SogouResult"的错误,

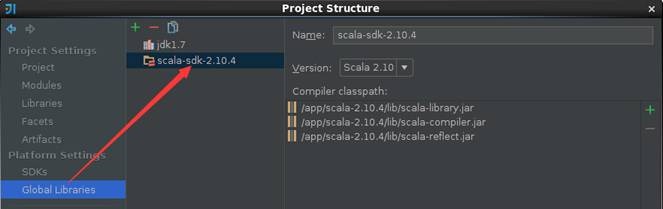
出现这个错误很可能不是程序代码的问题,很可能是使用Scala JDK版本问题,作者在使用scala-2.11.4遇到该问题,换成scala-2.10.4后重新编译该问题得到解决,需要检查两个地方配置:Libraries和Global Libraries分别修改为scala-2.10.4
Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战的更多相关文章
- Spark入门(七)--Spark的intersection、subtract、union和distinc
Spark的intersection intersection顾名思义,他是指交叉的.当两个RDD进行intersection后,将保留两者共有的.因此对于RDD1.intersection(RDD2 ...
- Spark入门(六)--Spark的combineByKey、sortBykey
spark的combineByKey combineByKey的特点 combineByKey的强大之处,在于提供了三个函数操作来操作一个函数.第一个函数,是对元数据处理,从而获得一个键值对.第二个函 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--7.Spark Streaming(下)--实时流计算Spark Streaming实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源 ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门实战系列--9.Spark图计算GraphX介绍及实例
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理 ...
随机推荐
- 如何在MFC中创建非矩形button
一般情况下,我们创建的按钮都是矩形的,但有时为了满足特殊的需求,我们要在对话框中创建一个非矩形的按钮,比如,圆形,椭圆等. 要实现一个非矩形的按钮,这就涉及到了自绘控件.自绘控件的方法有很多,可以参考 ...
- LNMP 部署
一.防火墙配置 CentOS 7.x默认使用的是firewall作为防火墙,这里改为iptables防火墙. 1.关闭firewall: systemctl stop firewalld.servic ...
- 使用扩展方法简化RadAjaxManager设置
相对于RadAjaxPanel,RadAjaxManager提供了更精确控制更新目标的设置,特别是在某些场景下,使用RadAjaxManager能够获得更好的性能. 但是,由于要明确设置目标,配置的代 ...
- Ubuntu 下安装Mysql 需要注意的地方.
安装卸载 sudo apt-get autoremove --purge mysql-server-5.0sudo apt-get remove mysql-serversudo apt-get au ...
- asp.net identity 2.2.0 中角色启用和基本使用(四)
创建角色相关视图 第一步:添加视图 打开RolesAdminController.cs 将鼠标移动到public ActionResult Index()上 右键>添加视图 系统会 ...
- 我的ORM之九 -- 生成器
我的ORM索引 数据库连接字符串格式 <add name="dbo" connectionString="" providerName="MyS ...
- 【腾讯优测干货】看腾讯的技术大牛如何将Crash率从2.2%降至0.2%?
小优有话说: App Crash就像地雷. 你怕它,想当它不存在.无异于让你的用户去探雷,一旦引爆,用户就没了. 你鼓起勇气去扫雷,它却神龙见首不见尾. 你告诫自己一定开发过程中减少crash,少埋点 ...
- VS2012编译的Windows服务启动后立即停止的解决方案
ATL中的BUG,在没有COM的服务中,使用_ATL_NO_COM_SUPPORT. 并在服务中添加下面的代码 #if defined(_ATL_NO_COM_SUPPORT) HRESULT Pre ...
- 不插网线,看不到IP的解决办法
在Windows中,如果不插网线,就看不到IP地址,即使这个块网卡已经绑定了固定IP,原因是操作系统开启了DHCP Media Sense功能,该功能的作用如下: 在一台使用 TCP/IP 的基于 W ...
- 用DirectX实现魔方(一)
关于魔方 魔方英文名字叫做Rubik's Cube,是由匈牙利建筑学教授和雕塑家Ernő Rubik于1974年发明,最初叫做Magic Cube(这大概也是中文名字的来历吧),1980年Ideal ...