Hadoop入门第三篇-MapReduce试手以及MR工作机制
MapReduce几个小应用
上篇文章已经介绍了怎么去写一个简单的MR并且将其跑起来,学习一个东西动手还是很有必要的,接下来我们就举几个小demo来体验一下跑起来的快感。
demo链接请参照附件:http://files.cnblogs.com/files/wangkeustc/demo.tar.gz
排序:
问题:将sort_input文件夹下的多个文件中的数据按照从小到大排序
设计思路:shuffle阶段会将发送到reduce的数据自动排序,所以我们这边只要保证在每个partiton中数字都是按照从小到大来的,比如第一个分区时1-20000的整数,第二个分区时20000-40000等。
所以这个问题的解答,我们引入了一个新的概念,定义属于自己的Partition类
单表关联:
问题:请参考join_input中的文件输入格式,也就是根据文件中的child-parent关系,找出存在的grandchild-grandparent关系,比如Tom Jerry 和Jerry Mark ,那么我们可以得到Mark是Tom的grandparent。
涉及思路:类似于将这张表中的parent和自身中的child做join,mapper阶段我们可以根据Tom Jerry的关系输入两个key,分别对应<Tom,1 Jerry>,其中1表示是parent和<Jerry,2 Tom>。在Reducer中我们只要把每个key对应的parent和他的child找出来做个循环就可以得到所有结果了。
上面两个例子,大家可以仔细阅读以下代码,最好也手动敲一遍,仔细琢磨以下,因为接下来讲到的MapReduce的工作机制会与此相关。
MapReduce工作机制
MapReduce执行总流程
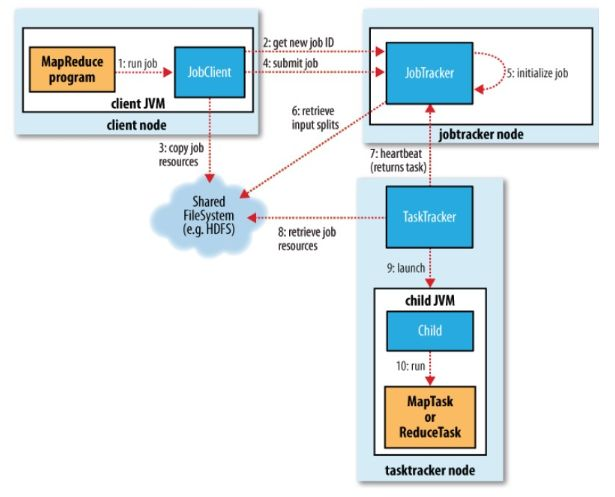
JobTracker:初始化作业,分配作业,与TaskManager通信,协调整个作业的执行
TaskTracker:保持与JobTracker的通信,执行map或者reduce任务
HDFS:保存作业的数据,配置信息等,保存作业结果。
具体相关流程
提交作业
客户端编写完程序代码后,打成jar,然后通过相关命令向集群提交自己想要跑的mr任务,具体过程如下:
- 通过调用JobTracker的getNewJobId()获取当前作业id
- 检查作业相关路径
- 计算作业的输入划分,并将划分信息写到Job.split文件中
- 将运行作业所需要的资源包括作业jar包,配置文件和甲酸所得的输入划分,复制到作业对应的HDFS上
- 调用JobTracker的summitJob()提交,告诉JobTracker作业准备执行
初始化作业
- 从HDFS中读取作业对应的job.split,得到输入数据的划分信息
- 创建并且初始化Map任务和Reduce任务:为每个map/reduce task生成一个TaskInProgress去监控和调度该task。
/**
* Construct the splits, etc. This is invoked from an async
* thread so that split-computation doesn't block anyone.
*/
public synchronized void initTasks()
throws IOException, KillInterruptedException, UnknownHostException {
if (tasksInited || isComplete()) {
return;
}
...... jobtracker.getInstrumentation().addWaitingMaps(getJobID(), numMapTasks);
jobtracker.getInstrumentation().addWaitingReduces(getJobID(), numReduceTasks);
this.queueMetrics.addWaitingMaps(getJobID(), numMapTasks);
this.queueMetrics.addWaitingReduces(getJobID(), numReduceTasks); //根据numMapTasks任务数,创建MapTask的总数
maps = new TaskInProgress[numMapTasks];
for(int i=0; i < numMapTasks; ++i) {
inputLength += splits[i].getInputDataLength();
maps[i] = new TaskInProgress(jobId, jobFile,
splits[i],
jobtracker, conf, this, i, numSlotsPerMap);
}
...... //
// Create reduce tasks
//根据numReduceTasks,创建Reduce的Task数量
this.reduces = new TaskInProgress[numReduceTasks];
for (int i = 0; i < numReduceTasks; i++) {
reduces[i] = new TaskInProgress(jobId, jobFile,
numMapTasks, i,
jobtracker, conf, this, numSlotsPerReduce);
nonRunningReduces.add(reduces[i]);
} ...... // create cleanup two cleanup tips, one map and one reduce.
//创建2个clean up Task任务,1个是Map Clean-Up Task,一个是Reduce Clean-Up Task
cleanup = new TaskInProgress[2]; // cleanup map tip. This map doesn't use any splits. Just assign an empty
// split.
TaskSplitMetaInfo emptySplit = JobSplit.EMPTY_TASK_SPLIT;
cleanup[0] = new TaskInProgress(jobId, jobFile, emptySplit,
jobtracker, conf, this, numMapTasks, 1);
cleanup[0].setJobCleanupTask(); // cleanup reduce tip.
cleanup[1] = new TaskInProgress(jobId, jobFile, numMapTasks,
numReduceTasks, jobtracker, conf, this, 1);
cleanup[1].setJobCleanupTask(); // create two setup tips, one map and one reduce.
//原理同上
setup = new TaskInProgress[2]; // setup map tip. This map doesn't use any split. Just assign an empty
// split.
setup[0] = new TaskInProgress(jobId, jobFile, emptySplit,
jobtracker, conf, this, numMapTasks + 1, 1);
setup[0].setJobSetupTask(); // setup reduce tip.
setup[1] = new TaskInProgress(jobId, jobFile, numMapTasks,
numReduceTasks + 1, jobtracker, conf, this, 1);
setup[1].setJobSetupTask(); ...... - 上面的代码块提到的,创建两个初始化task,一个初始化Map,一个初始化Reduce
分配任务
JobTracker会将任务分配到TaskTracker去执行,但是怎么判断哪些TaskTracker,怎么分配任务呢?所以,我们要实现JobTracker和TaskTracker中的通信,也就是TaskTracker循环向JobTracker发送心跳,向上级报告自己这边是不是还活着,活干的怎么样了,可以接些新活等。作为JobTracker,接收到心跳信息,如果有待分配任务,就会给这个TaskTracker分配一个任务,然后taskTracker就把这个任务加入到他的任务队列中。我们可以主要看看TaskTracker中的transmitHeartBeart()和JobTracker的heartbeat()方法。
执行任务
TaskTracker申请到任务后,在本地执行,主要有以下几个步骤来完成本地的步骤化:
- 将job.split复制到本地
- 将job.jar复制到本地
- 将job的配置信息写入到Job.xml
- 创建本地任务目录,解压job.rar
- 调用launchTaskForJob()方法发布任务
发布任务后,TaskRunner会启动新的java虚拟机来运行每个任务,以map任务为例,流程如下:
- 配置任务执行参数(获取java程序的执行环境和配置参数等)
- 在child临时文件表中添加Map任务信息
- 配置log文件夹,配置Map任务的执行环境和配置参数;
- 根据input split,生成RecordReader读取数据
- 为Map任务生成MapRunnable,一次从RecordReader中接收数据,并调用map函数进行处理
- 将Map函数的输出调用collect收集到MapOUtputBuffer中
Hadoop入门第三篇-MapReduce试手以及MR工作机制的更多相关文章
- JavaMail入门第三篇 发送邮件
JavaMail API中定义了一个java.mail.Transport类,它专门用于执行邮件发送任务,这个类的实例对象封装了某种邮件发送协议的底层实施细节,应用程序调用这个类中的方法就可以把Mes ...
- Hadoop入门第四篇:手动搭建自己的hadoop小集群
前言 好几天没有更新了,本来是应该先写HDFS的相关内容,但是考虑到HDFS是我们后面所有学习的基础,而我只是简单的了解了一下而已,后面准备好好整理HDFS再写这块.所以大家在阅读这篇文章之前,请先了 ...
- # hadoop入门第六篇:Hive实例
前言 前面已经讲了如何部署在hadoop集群上部署hive,现在我们就做一个很小的实例去熟悉HIVE QL.使用的数据是视频播放数据包括视频编码,播放设备编码,用户账号编码等,我们在这个数据基础上 ...
- Hadoop入门第五篇:Hive简介以及部署
标签(空格分隔): Hadoop Hive hwi 1.Hive简介 之前我一直在Maxcompute上进行大数据开发,所以对数仓这块还算比较了解,在接受Hive的时候基本上没什么大的障碍.所以, ...
- Html/Css(新手入门第三篇)
一.学习心得---参考优秀的网页来学习. 1我们只做的静态网页主要用的技术?html+css 只要网上看到的,他的源代码公开的.[1].先去分析,他们页面是如何布局(结构化)[2].再试着去做一下,- ...
- Android JNI入门第三篇——jni头文件分析
一. 首先写了java文件: public class HeaderFile { private native void doVoid(); native int doShort(); native ...
- Java线程入门第三篇
Java内存模型(jmm) Why:保证多线程正确协同工作 看图说明: 文字解释:线程a和线程b通信过程,首先线程a把本地内存的共享变量更新到主内存中,然后线程b去读取主内存的共享变量,最后更新到自己 ...
- Visualforce入门第三篇_2017.3.2
Visualforce实现显示Record List(列表) 详细见链接:https://trailhead.salesforce.com/modules/visualforce_fundamenta ...
- JavaMail入门第四篇 接收邮件
上一篇JavaMail入门第三篇 发送邮件中,我们学会了如何用JavaMail API提供的Transport类发送邮件,同样,JavaMail API中也提供了一些专门的类来对邮件的接收进行相关的操 ...
随机推荐
- 2017.12.25 Linux系统的使用
Linux系统的使用 现在标配的系统是 Linux + Nginx + PHP + MySQL ,这样的配置越来越多的大公司在用的了说到配置不同的是一个公司的规约,比如说挂载一般分为2个盘, / 下面 ...
- 解决mysql8小时无连接自动断掉机制
windows下打开my.ini,增加: interactive_timeout=28800000 wait_timeout=28800000 MySQL是一个小型关系型数据库管理系统,由于MySQL ...
- WPF实现ListView大小图标和分组
XAML: <ListView Grid.Row="3" Name="t_lvw_time" HorizontalAlignment="Stre ...
- 一次线上CPU高的问题排查实践
一次线上CPU高的问题排查实践 前言 近期某一天上班一开电脑,就收到了运维警报,有两台服务CPU负载很高,同时收到一线同事反馈 系统访问速度非常慢,几乎无响应. 一个美好的早晨,最怕什么就来什么.只好 ...
- daemon函数实现原理 守护进程
linux提供了daemon函数用于创建守护进程,实现原理如下: #include <unistd.h> int daemon(int nochdir, int noclose); 1. ...
- nginx限制ip访问某些特定url
这两天百度云给我发了一些安全报警邮件,其中一条是有些陌生ip频繁尝试登录我的后台账户,也就是www.runstone.top/admin.给出的建议是限制这些ip访问/admin/这个url,于是经过 ...
- k8s的储存方式简述
pod中的存储卷类型:1.emptyDir:用于临时储存空间,无持久性储存功能,生命周期同pod容器,pod删除后,数据不再存在.2.gitRepo:pod创建时,自动将云端仓库中的文件克隆到pod挂 ...
- gitLab 服务器搭建 (自己服务器上搭建gitLab)
环境 lunix(ubuntu) 1:添加文件 在 /etc/apt/sources.list.d/gitlab-ce.list 中添加一行 deb https://mirrors.tuna.ts ...
- 【JAVA】JVM常用工具
JDK内置工具使用 jps(Java Virtual Machine Process Status Tool) 查看所有的jvm进程,包括进程ID,进程启动的路径等等. jstack(Java ...
- day03_基本数据类型基本运算
1.什么是数据类型 变量值才是我们存储的数据,所以数据类指的就是变量值的不同种类 2.为何数据要分类型? 变量值是用来保存现实世界中的状态的,那么针对不同的状态就应该用不同类型的数据去表示 3.如何用 ...