Linux System Programming 学习笔记(四) 高级I/O
1. Scatter/Gather I/O
#include <sys/uio.h>
struct iovec {
void *iov_base; /* pointer to start of buffer */
size_t iov_len; /* size of buffer in bytes */
};
/* The readv() function reads count segments from the file descriptor fd into the buffers described by iov */
ssize_t readv (int fd, const struct iovec *iov, int count);
/* The writev() function writes at most count segments from the buffers described by iov into the file descriptor fd */
ssize_t writev (int fd, const struct iovec *iov, int count);
注意:在Scatter/Gather I/O操作过程中,内核必须分配内部数据结构来表示每个buffer分段,正常情况下,是根据分段数count进行动态内存分配的,
但是当分段数count较小时(一般<=8),内核直接在内核栈上分配,这显然比在堆中动态分配要快
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <sys/uio.h> int main(int argc, char* argv[])
{
struct iovec iov[];
char* buf[] = {
"The term buccaneer comes from the word boucan.\n",
"A boucan is a wooden frame used for cooking meat.\n",
"Buccaneer is the West Indies name for a pirate.\n" }; int fd = open("wel.txt", O_WRONLY | O_CREAT | O_TRUNC);
if (fd == -) {
fprintf(stderr, "open error\n");
return ;
} /* fill out three iovec structures */
for (int i = ; i < ; ++i) {
iov[i].iov_base = buf[i];
iov[i].iov_len = strlen(buf[i]) + ;
} /* with a single call, write them out all */
ssize_t nwrite = writev(fd, iov, );
if (nwrite == -) {
fprintf(stderr, "writev error\n");
return ;
}
fprintf(stdout, "wrote %d bytes\n", nwrite);
if (close(fd)) {
fprintf(stdout, "close error\n");
return ;
} return ;
}
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
#include <sys/uio.h>
#include <sys/stat.h> int main(int argc, char* argv[])
{
char foo[], bar[], baz[];
struct iovec iov[];
int fd = open("wel.txt", O_RDONLY);
if (fd == -) {
fprintf(stderr, "open error\n");
return ;
} /* set up our iovec structures */
iov[].iov_base = foo;
iov[].iov_len = sizeof(foo);
iov[].iov_base = bar;
iov[].iov_len = sizeof(bar);
iov[].iov_base = baz;
iov[].iov_len = sizeof(baz); /* read into the structures with a single call */
ssize_t nread = readv(fd, iov, );
if (nread == -) {
fprintf(stderr, "readv error\n");
return ;
} for (int i = ; i < ; ++i) {
fprintf(stdout, "%d: %s", i, (char*)iov[i].iov_base);
}
if (close(fd)) {
fprintf(stderr, "close error\n");
return ;
} return ;
}
writev的简单实现:
#include <unistd.h>
#include <sys/uio.h> ssize_t my_writev(int fd, const struct iovec* iov, int count)
{
ssize_t ret = ;
for (int i = ; i < count; ++i) {
ssize_t nr = write(fd, iov[i].iov_base, iov[i].iov_len);
if (nr == -) {
if (errno == EINTR)
continue;
ret -= ;
break;
}
ret += nr;
}
return nr;
}
In fact, all I/O inside the Linux kernel is vectored; read() and write() are implemented as vectored I/O with a vector of only one segment
2. epoll
/* A successful call to epoll_create1() instantiates a new epoll instance and returns a file descriptor associated with the instance */
#include <sys/epoll.h>
int epoll_create(int size);
parameter size used to provide a hint about the number of file descriptors to be watched;
nowadays the kernel dynamically sizes the required data structures and this parameter just needs to be greater than zero
(2) controling epoll
/* The epoll_ctl() system call can be used to add file descriptors to and remove file descriptors from a given epoll context */
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event); struct epoll_event {
__u32 events; /* events */
union {
void* ptr;
int fd;
__u32 u32;
__u64 u64;
} data;
};
a. op parameter
EPOLL_CTL_ADD // Add a monitor on the file associated with the file descriptor fd to the epoll instance associated with epfd
EPOLL_CTL_DEL // Remove a monitor on the file associated with the file descriptor fd from the epoll instance associated with epfd
EPOLL_CTL_MOD // Modify an existing monitor of fd with the updated events specified by event
b. event parameter
EPOLLET // Enables edge-triggered behavior for the monitor of the file ,The default behavior is level-triggered
EPOLLIN // The file is available to be read from without blocking
EPOLLOUT // The file is available to be written to without blocking
对于结构体struct epoll_event 里的data成员,通常做法是将data联合体里的fd设置为第二个参数fd,即 event.data.fd = fd
To add a new watch on the file associated with fd to the epoll instance epfd :
#include <sys/epoll.h> struct epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLOUT int ret = epll_ctl(epfd, EPOLL_CTL_ADD, fd, &event);
if (ret) {
fprintf(stderr, "epll_ctl error\n");
}
To modify an existing event on the file associated with fd on the epoll instance epfd :
#include <sys/epoll.h> struct epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN; int ret = epoll_ctl(epfd, EPOLL_CTL_MOD, fd, &event);
if (ret) {
fprintf(stderr, "epoll_ctl error\n");
}
To remove an existing event on the file associated with fd from the epoll instance epfd :
#include <sys/epoll.h> struct epoll_event event; int ret = epoll_ctl(epfd, EPOLL_CTL_DEL, fd, &event);
if (ret) {
fprintf(stderr, "epoll_ctl error\n");
}
(3) waiting for events with epoll
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
The return value is the number of events, or −1 on error
#include <sys/epoll.h> #define MAX_EVENTS 64 struct epoll_event* events = malloc(sizeof(struct epoll_event) * MAX_EVENTS);
if (events == NULL) {
fprintf(stdout, "malloc error\n");
return ;
} int nready = epoll_wait(epfd, events, MAX_EVENTS, -);
if (nready < ) {
fprintf(stderr, "epoll_wait error\n");
free(events);
return ;
} for (int i = ; i < nready; ++i) {
fprintf(stdout, "event=%ld on fd=%d\n", events[i].events, events[i].data.fd);
/* we now can operate on events[i].data.fd without blocking */
}
free(events);
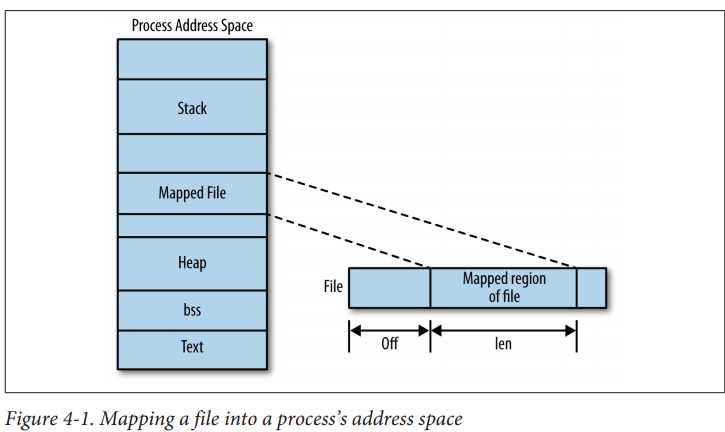
3. Mapping Files into Memory
/* A call to mmap() asks the kernel to map len bytes of the object represented by the file descriptor fd,
starting at offset bytes into the file, into memory
*/
#include <sys/mman.h>
void* mmap(void* addr, size_t len, int prot, int flags, int fd, off_t offset);
void* ptr = mmap(, len, PROT_READ, MAP_SHARED, fd, );
int munmap (void *addr, size_t len);
munmap() removes any mappings that contain pages located anywhere in the process address space starting at addr,
which must be page-aligned, and continuing for len bytes
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <fcntl.h> int main(int argc, char* argv[])
{
if (argc < ) {
fprintf(stderr, "usage:%s <file>\n", argv[]);
return ;
} int fd = open(argv[], O_RDONLY);
if (fd == -) {
fprintf(stderr, "open error\n");
return ;
} struct stat sbuf;
if (fsat(fd, &sbuf) == -) {
fprintf(stderr, "fstat error\n");
return ;
} if (!S_ISREG(sbuf.st_mode)) {
fprintf(stderr, "%s is not a file\n", argv[]);
return ;
}
void* ptr = mmap(, sbuf.st_size, PROT_READ, MAP_SHARED, fd, );
if (ptr == MAP_FAILED) {
fprintf(stderr, "mmap error\n");
return ;
} if (close(fd)) {
fprintf(stderr, "close error\n");
return ;
} for (int i = ; i < sbuf.st_size; ++i) {
fputc(ptr[i], stdout);
} if (munmap(ptr, sbuf.st_size) == -) {
fprintf(stderr, "munmap error\n");
return ;
}
return ;
}
#include <sys/mman.h>
int msync (void *addr, size_t len, int flags);
4. 同步 异步


5. I/O调度和I/O性能
Linus Elevator I/O scheduler
The Deadline I/O Scheduler
The Anticipatory I/O Scheduler
The CFQ I/O Scheduler
The Noop I/O Scheduler
Linux System Programming 学习笔记(四) 高级I/O的更多相关文章
- Linux System Programming 学习笔记(十一) 时间
1. 内核提供三种不同的方式来记录时间 Wall time (or real time):actual time and date in the real world Process time:the ...
- Linux System Programming 学习笔记(七) 线程
1. Threading is the creation and management of multiple units of execution within a single process 二 ...
- Linux System Programming 学习笔记(六) 进程调度
1. 进程调度 the process scheduler is the component of a kernel that selects which process to run next. 进 ...
- Linux System Programming 学习笔记(二) 文件I/O
1.每个Linux进程都有一个最大打开文件数,默认情况下,最大值是1024 文件描述符不仅可以引用普通文件,也可以引用套接字socket,目录,管道(everything is a file) 默认情 ...
- Linux System Programming 学习笔记(一) 介绍
1. Linux系统编程的三大基石:系统调用.C语言库.C编译器 系统调用:内核向用户级程序提供服务的唯一接口.在i386中,用户级程序执行软件中断指令 INT n 之后切换至内核空间 用户程序通过寄 ...
- Linux System Programming 学习笔记(十) 信号
1. 信号是软中断,提供处理异步事件的机制 异步事件可以是来源于系统外部(例如用户输入Ctrl-C)也可以来源于系统内(例如除0) 内核使用以下三种方法之一来处理信号: (1) 忽略该信号.SIG ...
- Linux System Programming 学习笔记(九) 内存管理
1. 进程地址空间 Linux中,进程并不是直接操作物理内存地址,而是每个进程关联一个虚拟地址空间 内存页是memory management unit (MMU) 可以管理的最小地址单元 机器的体系 ...
- Linux System Programming 学习笔记(八) 文件和目录管理
1. 文件和元数据 每个文件都是通过inode引用,每个inode索引节点都具有文件系统中唯一的inode number 一个inode索引节点是存储在Linux文件系统的磁盘介质上的物理对象,也是L ...
- Linux System Programming 学习笔记(五) 进程管理
1. 进程是unix系统中两个最重要的基础抽象之一(另一个是文件) A process is a running program A thread is the unit of activity in ...
随机推荐
- 《毛毛虫组》【Alpha】Scrum meeting 5
第二天 日期:2019/6/18 1.1 今日完成任务情况以及遇到的问题. 今日完成任务情况: 出入库货物年统计模块设计及系统的测试运行: (1)对数据库表--tb_InStore和tb_OutSto ...
- C#语言命名的9种规范
下面介绍C#语言命名的9种规范: a) 类 [规则1-1]使用Pascal规则命名类名,即首字母要大写. [规则1-2]使用能够反映类功能的名词或名词短语命名类. [规则1-3]不要使用“I”.“C” ...
- android 通过adb 和 ndk调试堆栈
打开终端 , 输入以下命令, armeabi是应用编译好的.so库的路径 adb logcat|ndk-stack -sym ./armeabi/ 如果堆栈报错,会弹出报错内容. 如下: C:\Use ...
- java 会话跟踪技术
1.session用来表示用户会话,session对象在服务端维护,一般tomcat设定session生命周期为30分钟,超时将失效,也可以主动设置无效: 2.cookie存放在客户端,可以分为内存c ...
- Golang TCP转发到指定地址
Golang TCP转发到指定地址 第二个版本,设置指定ip地址 代码 // tcpForward package main import ( "fmt" "net&qu ...
- python 爬取知乎图片
先上完整代码 import requests import time import datetime import os import json import uuid from pyquery im ...
- PHP将unicode转utf8最简法
最近开发时遇到Unicode编码问题,找了半天才知道PHP并没有Unicode转码函数,终于发现用一行PHP代码解决的方案: $str = '{"success":true,&qu ...
- MySQL中CONCAT()的用法
MySQL中CONCAT()的用法 在日常开发过程中,特别是在书写接口的时候,经常会遇到字符串拼接的情况,比如在返回图片数据时,数据库里往往存储的是相对路径,而接口里一般是存放绝对地址,这就需要字符串 ...
- CentOS 7.0 使用 yum 安装 MariaDB 及 简单配置
1.安装MariaDB 安装命令 yum -y install MariaDB-server MariaDB-client 安装完成MariaDB,首先启动MariaDB 设置开机启动 接下来进行Ma ...
- 关于51单片机IO引脚的驱动能力与上拉电阻
单片机的引脚,可以用程序来控制,输出高.低电平,这些可算是单片机的输出电压.但是,程序控制不了单片机的输出电流. 单片机的输出电流,很大程度上是取决于引脚上的外接器件. 单片机输出低电平时,将允许外部 ...