2 Model层 - 模型查询
1.简介
- 查询集表示从数据库中获取的对象集合
- 查询集可以含有零个、一个或多个过滤器
- 过滤器基于所给的参数限制查询的结果
- 从Sql的角度,查询集和select语句等价,过滤器像where和limit子句
- 接下来主要讨论如下知识点
- 查询集
- 字段查询:比较运算符,F对象,Q对象
2.查询集
- 在管理器上调用过滤器方法会返回查询集
- 查询集经过过滤器筛选后返回新的查询集,因此可以写成链式过滤
- 惰性执行:创建查询集不会带来任何数据库的访问,直到调用数据时,才会访问数据库
- 何时对查询集求值:迭代,序列化,与if合用
- 返回查询集的方法,称为过滤器
all()
filter()
exclude()
order_by()
values():一个对象构成一个字典,然后构成一个列表返回
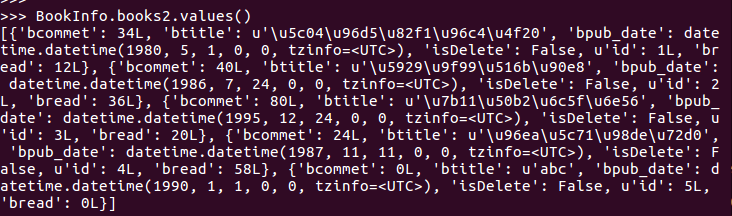
>>> BookInfo.books2.values()
[{'bcommet': 34L, 'btitle': u'\u5c04\u96d5\u82f1\u96c4\u4f20', 'bpub_date': datetime.datetime(, , , , , tzinfo=<UTC>), 'isDelete': False, u'id': 1L, 'bread': 12L}, {'bcommet': 40L, 'btitle': u'\u5929\u9f99\u516b\u90e8', 'bpub_date': datetime.datetime(, , , , , tzinfo=<UTC>), 'isDelete': False, u'id': 2L, 'bread': 36L}, {'bcommet': 80L, 'btitle': u'\u7b11\u50b2\u6c5f\u6e56', 'bpub_date': datetime.datetime(, , , , , tzinfo=<UTC>), 'isDelete': False, u'id': 3L, 'bread': 20L}, {'bcommet': 24L, 'btitle': u'\u96ea\u5c71\u98de\u72d0', 'bpub_date': datetime.datetime(, , , , , tzinfo=<UTC>), 'isDelete': False, u'id': 4L, 'bread': 58L}, {'bcommet': 0L, 'btitle': u'abc', 'bpub_date': datetime.datetime(, , , , , tzinfo=<UTC>), 'isDelete': False, u'id': 5L, 'bread': 0L}]
>>>
- 返回单个值的方法
get():返回单个满足条件的对象
如果未找到会引发"模型类.DoesNotExist"异常
如果多条被返回,会引发"模型类.MultipleObjectsReturned"异常
count():返回当前查询的总条数
first():返回第一个对象
last():返回最后一个对象
exists():判断查询集中是否有数据,如果有则返回True
限制查询集
- 查询集返回列表,可以使用下标的方式进行限制,等同于sql中的limit和offset子句
- 注意:不支持负数索引
- 使用下标后返回一个新的查询集,不会立即执行查询
- 如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()引发DoesNotExist异常
查询集的缓存
- 每个查询集都包含一个缓存来最小化对数据库的访问
- 在新建的查询集中,缓存为空,首次对查询集求值时,会发生数据库查询,django会将查询的结果存在查询集的缓存中,并返回请求的结果,接下来对查询集求值将重用缓存的结果
- 情况一:这构成了两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载
print([e.title for e in Entry.objects.all()])
print([e.title for e in Entry.objects.all()])
- 情况二:两次循环使用同一个查询集,第二次使用缓存中的数据
querylist=Entry.objects.all()
print([e.title for e in querylist])
print([e.title for e in querylist])
- 何时查询集不会被缓存:当只对查询集的部分进行求值时会检查缓存,但是如果这部分不在缓存中,那么接下来查询返回的记录将不会被缓存,这意味着使用索引来限制查询集将不会填充缓存,如果这部分数据已经被缓存,则直接使用缓存中的数据

3.字段查询
- 实现where子名,作为方法filter()、exclude()、get()的参数
- 语法:属性名称__比较运算符=值
- 表示两个下划线,左侧是属性名称,右侧是比较类型
- 对于外键,使用“属性名_id”表示外键的原始值
- 转义:like语句中使用了%与,匹配数据中的%与,在过滤器中直接写,例如:filter(title__contains="%")=>where title like '%\%%',表示查找标题中包含%的
比较运算符
- exact:表示判等,大小写敏感;如果没有写“ 比较运算符”,表示判等
filter(isDelete=False)

- contains:是否包含,大小写敏感
exclude(btitle__contains='传')

- startswith、endswith:以value开头或结尾,大小写敏感
exclude(btitle__endswith='传')
- isnull、isnotnull:是否为null
filter(btitle__isnull=False)
- 在前面加个i表示不区分大小写,如iexact、icontains、istarswith、iendswith
- in:是否包含在范围内
filter(pk__in=[, , , , ])

- gt、gte、lt、lte:大于、大于等于、小于、小于等于
filter(id__gt=)
- year、month、day、week_day、hour、minute、second:对日期间类型的属性进行运算
filter(bpub_date__year=)
filter(bpub_date__gt=date(, , ))

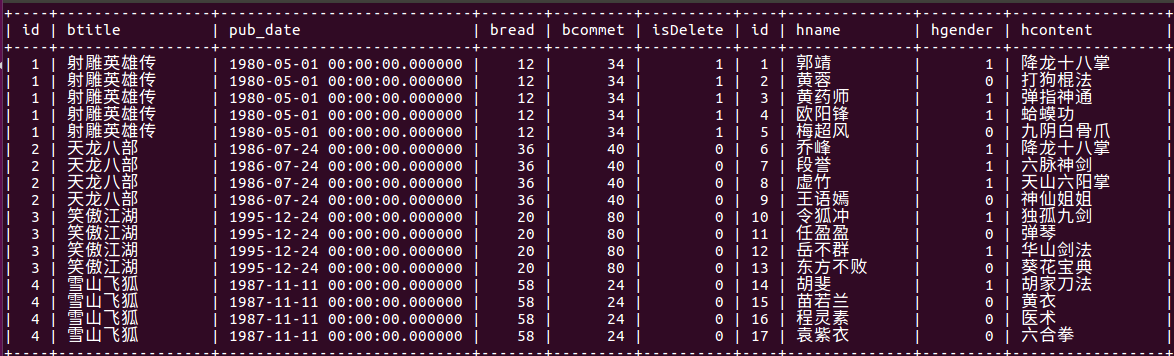
- 跨关联关系的查询:处理join查询
- 语法:模型类名 <属性名> <比较>
- 注:可以没有__<比较>部分,表示等于,结果同inner join
- 可返向使用,即在关联的两个模型中都可以使用
filter(heroinfo_ _hcontent_ _contains='八')


- 查询的快捷方式:pk,pk表示primary key,默认的主键是id
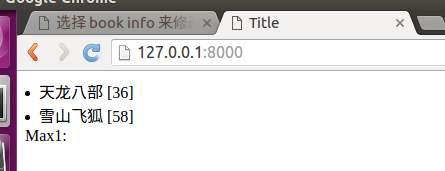
filter(pk__lt=)
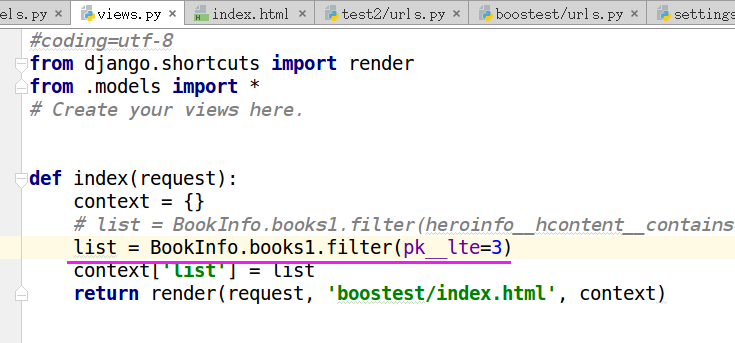

聚合函数
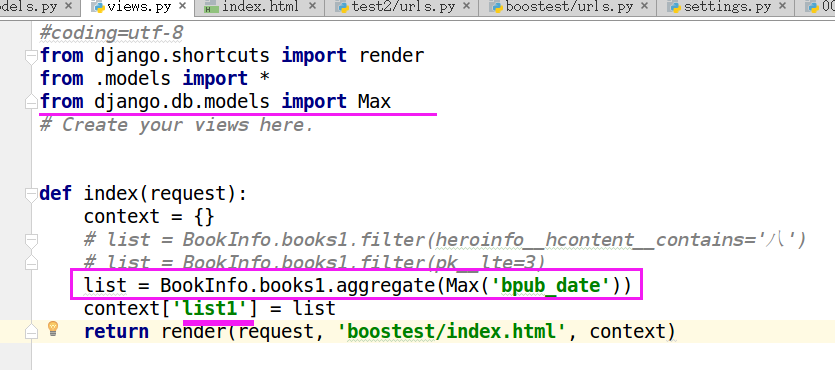
- 使用aggregate()函数返回聚合函数的值
- 函数:Avg,Count,Max,Min,Sum
from django.db.models import Max
maxDate = list.aggregate(Max('bpub_date'))
- count的一般用法:
count = list.count()

F对象
- 可以使用模型的字段A与字段B进行比较,如果A写在了等号的左边,则B出现在等号的右边,需要通过F对象构造
list.filter(bread__gte=F('bcommet'))
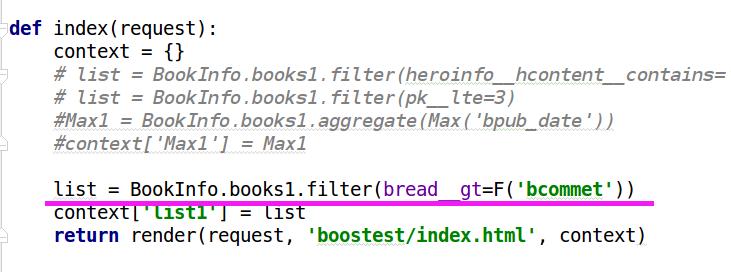

- django支持对F()对象使用算数运算
list.filter(bread__gte=F('bcommet') * )
- F()对象中还可以写作“模型类__列名”进行关联查询
list.filter(isDelete=F('heroinfo__isDelete'))
- 对于date/time字段,可与timedelta()进行运算
list.filter(bpub_date__lt=F('bpub_date') + timedelta(days=))
Q对象:逻辑或,逻辑与
逻辑与
- 过滤器的方法中关键字参数查询,会合并为And进行
- 需要进行or查询,使用Q()对象
- Q对象(django.db.models.Q)用于封装一组关键字参数,这些关键字参数与“比较运算符”中的相同
from django.db.models import Q
list.filter(Q(pk_ _lt=))
- Q对象可以使用&(and)、|(or)操作符组合起来
- 当操作符应用在两个Q对象时,会产生一个新的Q对象
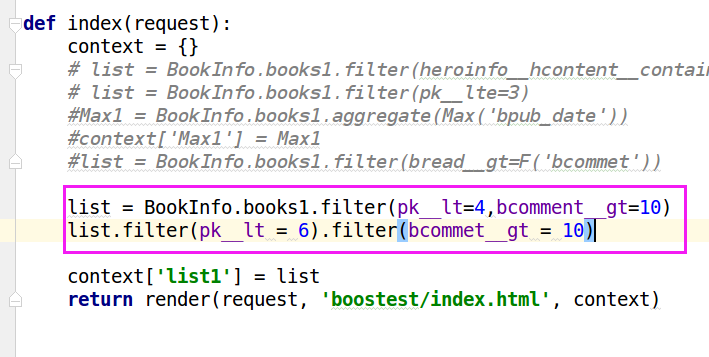
list.filter(pk_ _lt=).filter(bcommet_ _gt=)
list.filter(Q(pk_ _lt=) | Q(bcommet_ _gt=))


- 使用~(not)操作符在Q对象前表示取反
list.filter(~Q(pk__lt=))
- 可以使用&|~结合括号进行分组,构造做生意复杂的Q对象
- 过滤器函数可以传递一个或多个Q对象作为位置参数,如果有多个Q对象,这些参数的逻辑为and
- 过滤器函数可以混合使用Q对象和关键字参数,所有参数都将and在一起,Q对象必须位于关键字参数的前面
4 自连接
- 对于地区信息,属于一对多关系,使用一张表,存储所有的信息
- 类似的表结构还应用于分类信息,可以实现无限级分类
- 新建模型AreaInfo,生成迁移
class AreaInfo(models.Model):
atitle = models.CharField(max_length=20)
aParent = models.ForeignKey('self', null=True, blank=True)
- 访问关联对象
上级对象:area.aParent
下级对象:area.areainfo_set.all()
- 加入测试数据(在workbench中,参见“省市区mysql.txt”)
- 在booktest/views.py中定义视图area
from models import AreaInfo
def area(request):
area = AreaInfo.objects.get(pk=130100)
return render(request, 'booktest/area.html', {'area': area})
- 定义模板area.html
<!DOCTYPE html>
<html>
<head>
<title>地区</title>
</head>
<body>
当前地区:{{area.atitle}}
<hr/>
上级地区:{{area.aParent.atitle}}
<hr/>
下级地区:
<ul>
{ %for a in area.areainfo_set.all%}
<li>{{a.atitle}}</li>
{ %endfor%}
</ul>
</body>
</html>
- 在booktest/urls.py中配置一个新的urlconf
urlpatterns = [
url(r'^area/$', views.area, name='area')
]2 Model层 - 模型查询的更多相关文章
- 2 Model层-模型成员
1 类的属性 objects:是Manager类型的对象,用于与数据库进行交互 当定义模型类时没有指定管理器,则Django会为模型类提供一个名为objects的管理器 支持明确指定模型类的管理器 c ...
- DjangoMTV模型之model层——ORM操作数据库(基本增删改查)
Django的数据库相关操作 对象关系映射(英语:(Object Relational Mapping,简称ORM),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换.从效果上说 ...
- 读书笔记_MVC__关于通过js构建ORM,实现Model层
最近一直在学习MVC构建富应用的WEB程序,自己一直对MVC的设计模式理解的不是十分透彻,终于在研读了github上Spine的源码之后,对构建Model层有了一点自己的理解. 本文仅为个人理解,如有 ...
- 浅谈OSI七层模型及ICP/IP四层模型
1.OSI七层模型的概念 在网络历史的早期,国际标准化组织(ISO)和国际电报电话咨询委员会(CCITT)共同出版了开放系统互联的七层参考模型. 一台计算机操作系统中的网络过程包括从应用请求(在协议栈 ...
- TCP/IP四层模型和OSI七层模型
TCP/IP四层模型 TCP/IP是一组协议的代名词,它还包括许多协议,组成了TCP/IP协议簇.TCP/IP协议簇分为四层,IP位于协议簇的第二层(对应OSI的第三层),TCP位于协议簇的第三层(对 ...
- PHP MVC 中的MODEL层
Model层,就是MVC模式中的数据处理层,用来进行数据和商业逻辑的装封 三.实现你的Mode层 Model层,就是MVC模式中的数据处理层,用来进行数据和商业逻辑的装封,进行他的设计的时候设计到三个 ...
- TCP/IP四层模型和OSI七层模型的概念
转:http://blog.csdn.net/superjunjin/article/details/7841099/ TCP/IP四层模型 TCP/IP是一组协议的代名词,它还包括许多协议,组成了T ...
- MVC5中Model层开发数据注解
ASP.NET MVC5中Model层开发,使用的数据注解有三个作用: 数据映射(把Model层的类用EntityFramework映射成对应的表) 数据验证(在服务器端和客户端验证数据的有效性) 数 ...
- Model Validation(模型验证)
Model Validation(模型验证) 前言 阅读本文之前,您也可以到Asp.Net Web API 2 系列导航进行查看 http://www.cnblogs.com/aehyok/p/344 ...
随机推荐
- 【干货】Html与CSS入门学习笔记4-8
四.web镇之旅,连接起来 找一家托管公司如阿里云,购买域名和空间,然后将网页文件上传到购买的空间的根目录下. 1.绝对路径url url:uniform resource locators 统一资源 ...
- Android 应用开机自启和无需权限开启悬浮框
开机自启主要自定义广播接收类,且需要在清单文件中注册,不要在代码中动态注册. <uses-permission android:name="android.permission.REC ...
- JAVA继承与使用
说来惭愧,java学完已经两年了,开发也已经做了快一年了,现在才基本了解继承怎么用,平时都是在一个类中乱写一气.现在感觉原来学的知识真正运用起来还是具有一定的差距.希望能够先夯实基础,共勉.写一下自己 ...
- HDU 1009 FatMouse' Trade肥老鼠的交易(AC代码) 贪心法
题意: 一只老鼠用猫粮来换豆子,每个房间的兑换率不同,所以得尽量从兑换率高的房间先兑换.肥老鼠准备M磅猫粮去跟猫交易,让猫在warehouse中帮他指路,以找到好吃的.warehouse有N个房间,第 ...
- python内存泄露的诊断(转)
本篇文章非原创,转载自:http://rstevens.iteye.com/blog/828565 . 对于一个用 python 实现的,长期运行的后台服务进程来说,如果内存持续增长,那么很可能是有了 ...
- ARM实验1 —— 流水灯实验
实验内容: 编写GPIO模块程序,实现对FS_4412平台的上的led2,led3,led4 ,led5,的流水灯实现. 实验目的: 熟悉开发环境的使用. 掌握Exynos 4412处理器GPIO功能 ...
- 如何处理CloudFoundry应用部署时遇到的254错误
使用SAP云平台的CloudFoundry部署应用: 在cockpit遇到错误信息:instance: a0abe2b5-7623-4cf1-4c65-0c79, index: 0, exit_des ...
- Windows底层开发前期学习准备工作
1.若对Windows底层开发没有兴趣,不建议继续深究, 若有些兴趣可以继续. 2. 先广泛打基础,比如C/ASM/C++/MFC,再学习Windows核心编程,对R3上的一些开发有所熟悉,再系统的学 ...
- UVALive 4731 Cellular Network(贪心,dp)
分析: 状态是一些有序的集合,这些集合互不相交,并集为所有区域.显然枚举集合元素是哪些是无法承受的, 写出期望的计算式,会发现,当每个集合的大小确定了以后,概率大的优先访问是最优的. 因此先对u从大到 ...
- Oracle 自动生成hive建表语句
从 oracle 数据库导数到到 hive 大数据平台,需要按照大数据平台的数据规范,重新生成建表的 SQL 语句,方便其间,写了一个自动生成SQL的存储过程. ① 创建一张表,用来存储源表的结构,以 ...