[Paper] Selection and replacement algorithm for memory performance improvement in Spark
Summary
Spark does not have a good mechanism to select reasonable RDDs to cache their partitions in limited memory. --> Propose a novel selection algorithm, by which Spark can automatically select the RDDs to cache their partitions in memory according to the number of use for RDDs. --> speeds up iterative computations.
Spark use least recently used (LRU) replacement algorithm to evict RDDs, which only consider the usage of the RDDs. --> a novel replacement algorithm called weight replacement (WR) algorithm, which takes comprehensive consideration of the partitions computation cost, the number of use for partitions, and the sizes of the partitions.
Preliminary Information
Cache mechanism in Spark
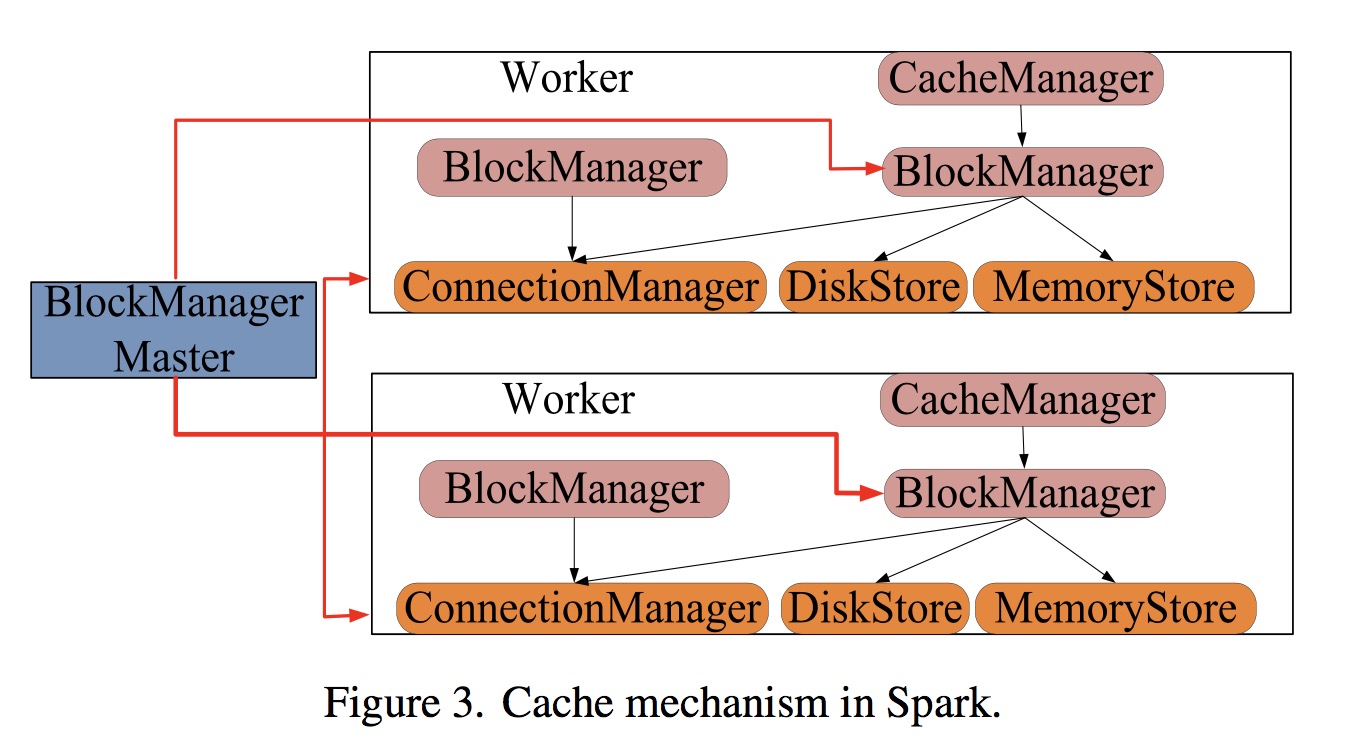
- When RDD partitions have been cached in memory during the iterative computation, an operation which needs the partitions will get them by CacheManager.
- All operations including reading or caching in CacheManager mainly depend on the API of BlockManager. BlockManager decides whether partitions are obtained from memory or disks.
Scheduling model
- The LRU algorithm only considers whether those partitions are recently used while ignores the partitions computation cost and the sizes of the partitions.
- The number of use for partitions can be known from the DAG before tasks are performed.
Let Nij be the number of use of j-th partition of RDDi.
Let Sij be the size of j-th partition or RDDi. - The computation time is also an important part. --> Each partition of RDDi starting time STij and finishing time FTij can roughly express its execution and communication time.
Consider the computation cost of partition as Costj = FTij - STij. - After that, we set up a scheduling model and obtain the weight of Pij, which can be expressed as:
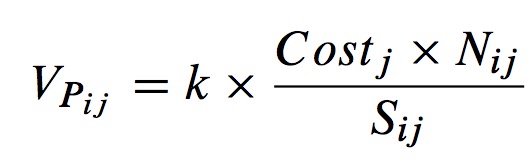
where k is the correction parameter, and it's set to a constant. - Finally, we assume that there are h partitions in RDDi, so the weight of RDDi is:
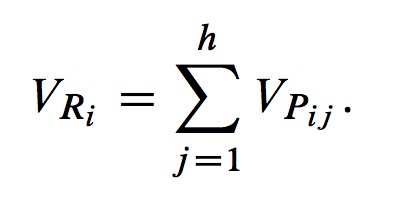
Proposed Algorithm
Selection algorithm
- For a given DAG graph,we can get the num of uses for each RDD, expressioned as NRDDi.
- The pseudocode:

Replacement algorithm
- In this paper, we use weight of partition to evaluate the importance of the partitions.
- When many partitions are cached in memory, we use QuickSort algorithm to sort the partitions according to the value of the partitions.
- The pseudocode:

Experiments
- five servers, six virtual machines, each vm has 100G disk, 2.5GHZ and runs Ubuntu 12.04 operation system while memory is variable, and we set it as 1G, 2G, or 4G in different conditions.
- Hadoop 2.10.4 and Spark-1.1.0.
- use ganglia to observe the memory usage.
- use pageRank algorithm to do expirement, it's iterative.
[Paper] Selection and replacement algorithm for memory performance improvement in Spark的更多相关文章
- Partitioned Replacement for Cache Memory
In a particular embodiment, a circuit device includes a translation look-aside buffer (TLB) configur ...
- Flash-aware Page Replacement Algorithm
1.Abstract:(1)字体太乱,单词中有空格(2) FAPRA此名词第一出现时应有“ FAPRA(Flash-aware Page Replacement Algorithm)”说明. 2.in ...
- Inside Amazon's Kafkaesque "Performance Improvement Plans"
Amazon CEO and brilliant prick Jeff Bezos seems to have lost his magic touch lately. Investors, empl ...
- Hive-Container killed by YARN for exceeding memory limits. 9.2 GB of 9 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task times, most recen ...
- Spring Boot Memory Performance
The Performance Zone is brought to you in partnership with New Relic. Quickly learn how to use Docke ...
- 计算机系统结构总结_Memory Hierarchy and Memory Performance
Textbook: <计算机组成与设计——硬件/软件接口> HI <计算机体系结构——量化研究方法> QR 这是youtube上一个非常好的memory syst ...
- PatentTips - Control register access virtualization performance improvement
BACKGROUND OF THE INVENTION A conventional virtual-machine monitor (VMM) typically runs on a compute ...
- SQL Performance Improvement Techniques(转)
原文地址:http://www.codeproject.com/Tips/1023621/SQL-Performance-Improvement-Techniques This article pro ...
- Ceilometer Polling Performance Improvement
Ceilometer的数据采集agent会定期对nova/keystone/neutron/cinder等服务调用其API的获取信息,默认是20秒一次, # Polling interval for ...
随机推荐
- android -------- Data Binding的使用 ( 六) 自定义属性
今天来说说DataBinding在自定义属性的使用 默认的android命名空间下,我们会发现并不是所有的属性都能直接通过data binding进行设置,比如margin,padding,还有自定义 ...
- textarea点击蓝色背景,黄色条,input点击黄色条,如何去掉?
textarea:focus{ background: #ffff outline:none; } input:focus{ oulilne:none; }
- 00-自测5. Shuffling Machine
Shuffling is a procedure used to randomize a deck of playing cards. Because standard shuffling techn ...
- 路由器固定IP配置
前言 路由器插入好电源,插入好网线,笔记本连接路由器的wifi,连接成功后,网页自动打开. 1.在网页自动输入管理员密码 2.上网方式选择固定IP地址,输入IP地址,子网掩码,默认网关,DNS服务 3 ...
- java骰子求和算法
//扔 n 个骰子,向上面的数字之和为 S.给定 Given n,请列出所有可能的 S 值及其相应的概率public class Solution { /** * @param n an intege ...
- cf-914D-线段树
http://codeforces.com/contest/914/problem/D 题目大意是给出一个数列,进行两种操作,一个是将位置i的数置为x,另一个操作是询问[l,r]内的数的gcd是不是x ...
- poj-2689-素数区间筛
Prime Distance Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 22420 Accepted: 5954 Descr ...
- PAT 1008 Elevator
1008 Elevator (20 分) The highest building in our city has only one elevator. A request list is mad ...
- python 小练习 8
砝码问题1有一组砝码,重量互不相等,分别为m1.m2.m3……mn:它们可取的最大数量分别为x1.x2.x3……xn. 现要用这些砝码去称物体的重量,问能称出多少种不同的重量. 现在给你两个正整数列表 ...
- Python返回函数、闭包,匿名函数
函数不仅可以作为函数参数,还可以作为函数返回结果 def pro1(c,f): def pro2(): return f(c) return pro2 #调用pro1函数时,返回的是pro2函数对象& ...