sklearn调参(验证曲线,可视化不同参数下交叉验证得分)
一 、 原始方法:
思路:
1. 参数从 0+∞ 的一个 区间 取点, 方法如: np.logspace(-10, 0, 10) , np.logspace(-6, -1, 5)
2. 循环调用cross_val_score计算得分。
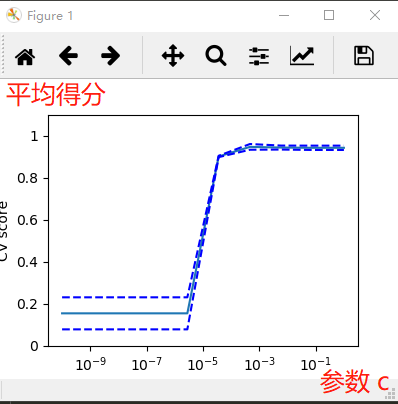
在SVM不同的惩罚参数C下的模型准确率。
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
import numpy as np
from sklearn import datasets, svm
digits = datasets.load_digits()
x = digits.data
y = digits.target
vsc = svm.SVC(kernel='linear') if __name__=='__main__':
c_S = np.logspace(-10, 0, 10)#在范围内取是个对数
# print ("length", len(c_S))
scores = list()
scores_std = list()
for c in c_S:
vsc.C = c
this_scores = cross_val_score(vsc, x, y, n_jobs=4)#多线程 n_jobs,默认三次交叉验证
scores.append(np.mean(this_scores))
scores_std.append(np.std(this_scores))
plt.figure(1, figsize=(4, 3))#绘图
plt.clf()
plt.semilogx(c_S, scores)#划线
plt.semilogx(c_S, np.array(scores)+np.array(scores_std), 'b--')
plt.semilogx(c_S, np.array(scores)-np.array(scores_std), 'b--')
locs, labels = plt.yticks()
plt.yticks(locs, list(map(lambda X: "%g" % X, locs)))#阶段点
plt.ylabel('CV score')
plt.xlabel('parameter C')
plt.ylim(0, 1.1)#范围
plt.show()
效果:
二、高级方法(validation_curve)
思路:
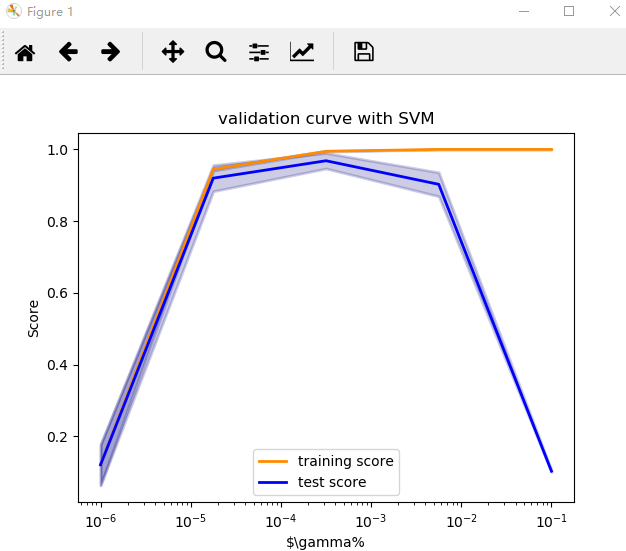
直接用validation_curve获得模型在不同参数下,每次训练得分和测试得分。
from sklearn import svm
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_digits
import numpy as np
import matplotlib.pyplot as plt
digits = load_digits()
X = digits.data
y = digits.target
param_range = np.logspace(-6, -1, 5)
vsc = svm.SVC()
train_score, test_score = validation_curve(vsc, X, y, param_name='gamma', param_range=param_range, cv=10, scoring="accuracy", n_jobs=1)
train_score_mean = np.mean(train_score, axis=1)
train_score_std = np.std(train_score, axis=1)
test_score_mean = np.mean(test_score, axis=1)
test_score_std = np.std(test_score, axis=1)
plt.title("validation curve with SVM")
plt.xlabel("$\gamma%")
plt.ylabel("Score")
plt.ylim()
lw = 2
plt.semilogx(param_range, train_score_mean,label="training score", color="darkorange", lw=lw)
plt.fill_between(param_range, train_score_mean-train_score_std, train_score_mean+train_score_std, alpha=0.2, color="navy", lw=lw)
plt.semilogx(param_range, test_score_mean,label="test score", color="blue", lw=lw)
plt.fill_between(param_range, test_score_mean-test_score_std, test_score_mean+test_score_std, alpha=0.2, color="navy", lw=lw)
plt.legend(loc="best")
plt.show()
结果:
sklearn调参(验证曲线,可视化不同参数下交叉验证得分)的更多相关文章
- 普通交叉验证(OCV)和广义交叉验证(GCV)
普通交叉验证OCV OCV是由Allen(1974)在回归背景下提出的,之后Wahba和Wold(1975)在讨论 了确定多项式回归中多项式次数的背景,在光滑样条背景下提出OCV. Craven和Wa ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
- python 机器学习中模型评估和调参
在做数据处理时,需要用到不同的手法,如特征标准化,主成分分析,等等会重复用到某些参数,sklearn中提供了管道,可以一次性的解决该问题 先展示先通常的做法 import pandas as pd f ...
- k-近邻算法采用for循环调参方法
//2019.08.02下午#机器学习算法中的超参数与模型参数1.超参数:是指机器学习算法运行之前需要指定的参数,是指对于不同机器学习算法属性的决定参数.通常来说,人们所说的调参就是指调节超参数.2. ...
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- GridsearchCV调参
在利用gridseachcv进行调参时,其中关于scoring可以填的参数在SKlearn中没有写清楚,就自己找了下,具体如下: parameters = {'eps':[0.3,0.4,0.5,0. ...
- LSTM调参经验
0.开始训练之前先要做些什么? 在开始调参之前,需要确定方向,所谓方向就是确定了之后,在调参过程中不再更改 1.根据任务需求,结合数据,确定网络结构. 例如对于RNN而言,你的数据是变长还是非变长:输 ...
- 【Python机器学习实战】决策树与集成学习(七)——集成学习(5)XGBoost实例及调参
上一节对XGBoost算法的原理和过程进行了描述,XGBoost在算法优化方面主要在原损失函数中加入了正则项,同时将损失函数的二阶泰勒展开近似展开代替残差(事实上在GBDT中叶子结点的最优值求解也是使 ...
随机推荐
- react中多语言切换的实现方式
目前正在进行的项目就是一个多语言切换的项目,有些前情知识我们可以 从https://react.i18next.com/getting-started进行了解. 说到使用方法,当然首先是要$ npm ...
- My thoughts after NOIP 2018(2)
又一次陷入迷茫了呢. - 大概是因为是因为自招政策要改变了吧? - 大概是因为前路在一点一点变得难走吧? - 大概是因为OI和学习实在太难平衡了吧? 未来的一切都已经不再在我控制的范围之内,不迷茫才怪 ...
- OSPF基础介绍
OSPF基础介绍 一.RIP的缺陷 1.以跳数评估的路由并非最优路径 2.最大跳数16导致网络尺度小 3.收敛速度慢 4.更新发送全部路由表浪费网络资源 二.OSPF基本原理 1.什么是OSPF a& ...
- CentOS下的yum upgrade和yum update区别
说明:生产环境对软件版本和内核版本要求非常精确,别没事有事随便的进行yum update操作!! ! yum update:升级所有包同时也升级软件和系统内核 yum upgrade:只升级所有包,不 ...
- 【1】存在大于1s的FullGC
目前有存在大于1s的FullGC,金桥的机器目前是2C4G的,使用的GC方法只能使用单线程进行串行的回收,导致GC比较慢. 建议可以调整GC参数,改用CMS,能够解决这个问题, 参数修改方法: 在应用 ...
- Redis详解(一)冰叔带你了解Redis
Redis 是一种基于 键值对 的 NoSQL 数据库.与很多键值对数据库不同,Redis 提供了丰富的 值数据存储结构,包括 string(字符串).hash(哈希).list(列表).set ...
- xss漏洞利用
简述 跨站脚本攻击(也称为XSS)指利用网站漏洞从用户那里恶意盗取信息.攻击者通过在链接中插入恶意代码,就能够盗取用户信息.攻击者通常会在有漏洞的程序中插入 JavaScript.VBScript. ...
- DPM 目标检测1
1. Origin 原始目标检测: HOG梯度模型+目标匹配 为了提过对目标形变的鲁棒性(多视角->多组件): 目标形态多样性—>多个模型 目标的动态变化多视角—> 子模型 目标形变 ...
- float导致出现大面积空白
float导致出现大面积空白,解决方法: *{ padding: 0; margin: 0; overflow:hidden; }
- jquery 学习(四) - 标签 添加/删除/修改
HTML代码 <div class="a1"> <div> <span id="a2">aaa</span> & ...