sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法。于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证。 一开始的子集被称为训练集。而其它的子集则被称为验证集或测试集。交叉验证是一种评估统计分析、机器学习算法对独立于训练数据的数据集的泛化能力(generalize)。
我们以分类花的例子来看下:
# 加载iris数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
X = iris.data
y = iris.target
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 建立模型
model = KNeighborsClassifier()
# 训练模型
model.fit(X_train, y_train)
# 将准确率打印出
print(model.score(X_test, y_test))
这样这个模型的得分为:
0.911111111111
但是如果我再运行一下,这个得分又会变成:
0.955555555556
如果再进行多次运行,这个得分的结果就又会不一样。
为了能够得出一个相对比较准确的得分,一般是进行多次试验,并且是用不同的训练集和测试集进行。
这个叫做交叉验证,一般有留一法,也就是把原始数据分成十份,其中一份作为测试,其它的作为训练集,并且可以循环来选取其中的一份作为测试集,剩下的作为训练集。
当然,这里只是提供一个基本思想,具体你要分成几份可以自己来定义。
比如,下面的代码我们定义了5份并做了5次实验:
# 加载iris数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
X = iris.data
y = iris.target
# 建立模型
model = KNeighborsClassifier()
# 使用K折交叉验证模块
scores = cross_val_score(model, X, y, cv=5)
# 将5次的预测准确率打印出
print(scores)
输出为:
[ 0.96666667 1. 0.93333333 0.96666667 1. ]
对这几次实验结果进行一下平均作为本次实验的最终得分:
# 将5次的预测准确平均率打印出
print(scores.mean())
结果为:
0.973333333333
在KNN算法中,其中有个neighbors参数,我们可以修改此参数的值:
model = KNeighborsClassifier(n_neighbors=5)
但这个参数值选择哪个数字为最佳呢?
我们可以通过程序来不停选择这个值并看在不同数值下其对应的得分情况,最终可以选择得分较好对应的参数值:
# 加载iris数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
# 可视化模块
import matplotlib.pyplot as plt
iris = load_iris()
X = iris.data
y = iris.target
# 建立测试参数集
k_range = range(1, 31)
k_scores = []
for k in k_range:
# 建立模型
model = KNeighborsClassifier(n_neighbors=k)
# 使用K折交叉验证模块
scores = cross_val_score(model, X, y, cv=10)
# 计算10次的预测准确平均率
k_scores.append(scores.mean())
# 可视化数据
plt.plot(k_range, k_scores)
plt.show()
显示的图形为:
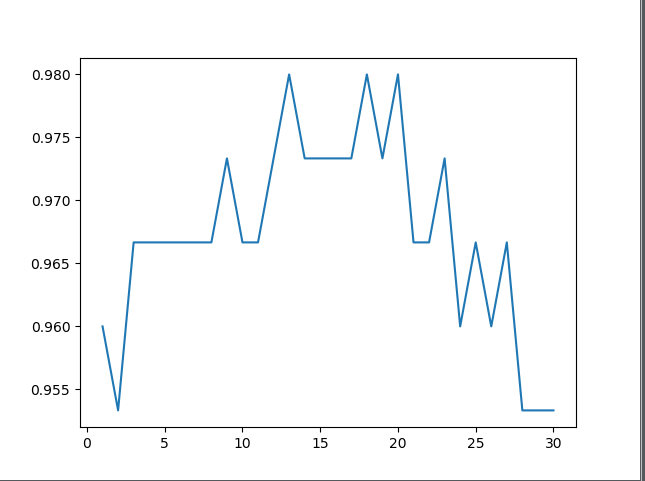
从这个结果图上看,n_neighbors太小或太大其精确度都会下降,因此比较好的取值是5-20之间。
另外对于回归算法,需要用损失函数来进行评估:
loss = -cross_val_score(model, data_X, data_y, cv=10, scoring='neg_mean_squared_error')
sklearn交叉验证-【老鱼学sklearn】的更多相关文章
- sklearn标准化-【老鱼学sklearn】
在前面的一篇博文中关于计算房价中我们也大致提到了标准化的概念,也就是比如对于影响房价的参数中有面积和户型,面积的取值范围可以很广,它可以从0-500平米,而户型一般也就1-5. 标准化就是要把这两种参 ...
- sklearn数据库-【老鱼学sklearn】
在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练. 本节就来看看sklearn提供了哪些可供训练的数据集. 这些数据位于datasets中,网址为:htt ...
- sklearn交叉验证2-【老鱼学sklearn】
过拟合 过拟合相当于一个人只会读书,却不知如何利用知识进行变通. 相当于他把考试题目背得滚瓜烂熟,但一旦环境稍微有些变化,就死得很惨. 从图形上看,类似下图的最右图: 从数学公式上来看,这个曲线应该是 ...
- sklearn交叉验证3-【老鱼学sklearn】
在上一个博文中,我们用learning_curve函数来确定应该拥有多少的训练集能够达到效果,就像一个人进行学习时需要做多少题目就能拥有较好的考试成绩了. 本次我们来看下如何调整学习中的参数,类似一个 ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 机器学习- Sklearn (交叉验证和Pipeline)
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用.那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_valid ...
随机推荐
- [模板] 积性函数 && 线性筛
积性函数 数论函数指的是定义在正整数集上的实或复函数. 积性函数指的是当 \((a,b)=1\) 时, 满足 \(f(a*b)=f(a)*f(b)\) 的数论函数. 完全积性函数指的是在任何情况下, ...
- 在本机使用虚拟机安装一个linux系统,并搭建ftp服务器
一.Linux基础使用:linux服务器环境搭建(FTP服务器), 在本机使用虚拟机安装一个linux系统,并搭建ftp服务器,要求能使用ftp服务将本机文件到保存linux虚拟机上 资料: VMwa ...
- mpvue——引入echarts图表
安装 mpvue-echarts的github地址 https://github.com/F-loat/mpvue-echarts $ cnpm install mpvue-echarts $ cnp ...
- Memory Layout for Multiple and Virtual Inheritance
Memory Layout for Multiple and Virtual Inheritance(By Edsko de Vries, January 2006)Warning. This art ...
- poj 2955 Brackets (区间dp 括号匹配)
Description We give the following inductive definition of a “regular brackets” sequence: the empty s ...
- Object is not a function
如图报了一个这样的错,百度好多都说是函数名和html元素重名的问题.可是这个问题我想我这里是不存在的 可以看到就一个绑定事件,而且id名不是关键字 报错是在$.ajax这一行,索性就把submit-i ...
- kafka全部数据清空与某一topic数据清空
1. Kafka全部数据清空 kafka全部数据清空的步骤为: 停止每台机器上的kafka: 删除kafka存储目录(server.properties文件log.dirs配置,默认为“/tmp/ka ...
- SHELL希尔排序
/****************************************************************************** * Compilation: javac ...
- 使用Jenkins docker镜像运行Jenkins服务
需求 使用docker技术管理Jenkins服务器.避免多次部署需要重复安装的重复工作,且可以方便迁移到新的服务器. Jenkins docker镜像 https://hub.docker.com/_ ...
- Jenkins 子业务日志拆分分析方法
需求 Jenkins日志打印内容很长,或者并发编译导致,日志内容不容易查看. 对于具体业务失败, 开发者希望看到具体业务自身的日志内容. 解法 tee 命令能够保证, shell命令执行的内容,即往控 ...