4.6 并发编程/IO模型
并发编程/IO模型
背景概念

IO模型概念
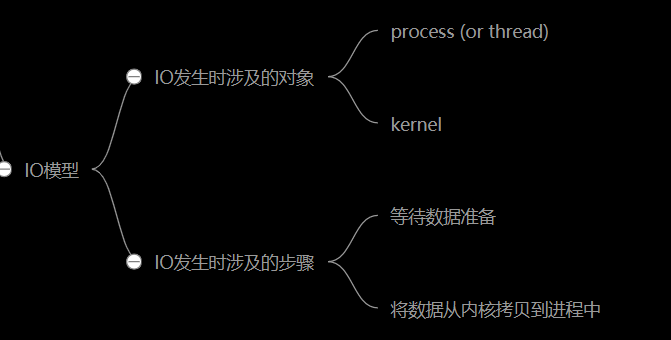
IO模型分类
阻塞IO (blocking IO)
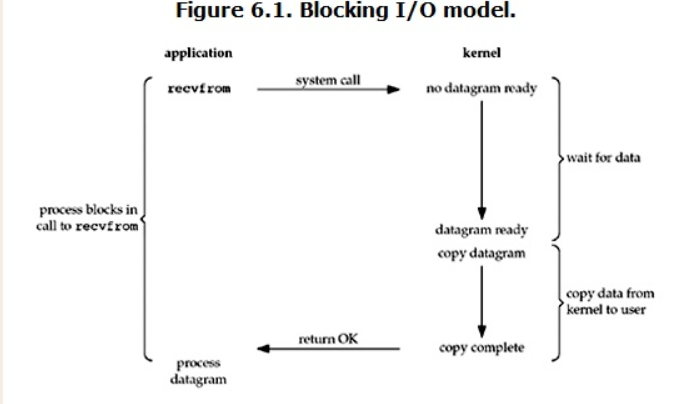
特点:
两个阶段(等待数据和拷贝数据两个阶段)都被block
设置
server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
解决方案:
启用多线程或者多进程,要阻塞只阻塞当前线程/进程,不会影响其他进程/线程
不良影响:
当遇到过多得链接请求时会严重占用资源,降低响应效率
修复不良影响:
启用进程池/线程池 ,降低进程/线程数量
仍旧未解决的不良影响:
池得数量不好规范,请求数量和池大小不好对应,且池存在数量上限
只是一定程度上限制了不良影响,无法根本解决
总结 :
基于池得创建可以解决小规模得服务请求带来的压力,对于大规模还是无力回天
非阻塞IO (nonblocking IO)

特点:
基于IO阻塞模型类似,再本应阻塞得地方不在阻塞,如果未收到想要数据会返回一个 error 给用户告知无数据
发送 error 后会进行其他得任务继续操作背后会一直对 kernel 进行轮询发送数据请求,
这期间如果数据到了就会重新正常操作,而在轮询期间,无数据得进程会一直处于阻塞状态
就结果而言。完全得实现了并发,以及解决了IO阻塞带来得效率低下的问题
设置
server.setblocking() #默认是True
server.setblocking(False) #False的话就成非阻塞了,这只是对于socket套接字来说的
不良影响:
1. 虽说解决了单线程并发,但是大大的占用了cpu
2. 任务完成的响应延迟增大,任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低
总结 :
完全不推荐
多路复用IO (IO multiplexing)
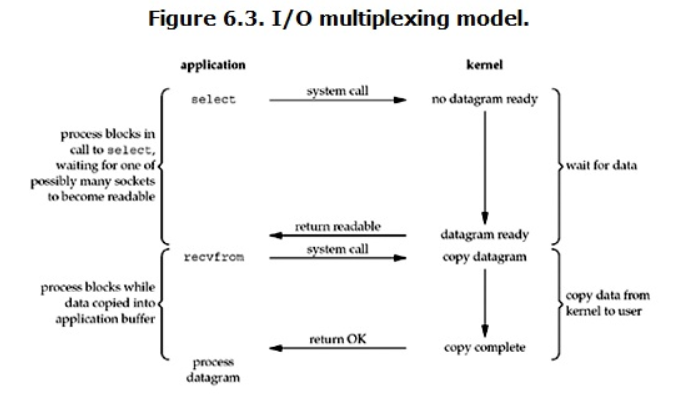
特点:
当用户进程调用了select,那么整个进程会被block
而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。
这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。
因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
设置
使用 select 模块 或者 eppol (只能用于 linux 中)
最优的选择方案是用 selectors
selectors 实例
#服务端
from socket import *
import selectors sel=selectors.DefaultSelector()
def accept(server_fileobj,mask):
conn,addr=server_fileobj.accept()
sel.register(conn,selectors.EVENT_READ,read) def read(conn,mask):
try:
data=conn.recv(1024)
if not data:
print('closing',conn)
sel.unregister(conn)
conn.close()
return
conn.send(data.upper()+b'_SB')
except Exception:
print('closing', conn)
sel.unregister(conn)
conn.close() server_fileobj=socket(AF_INET,SOCK_STREAM)
server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server_fileobj.bind(('127.0.0.1',8088))
server_fileobj.listen(5)
server_fileobj.setblocking(False) #设置socket的接口为非阻塞
sel.register(server_fileobj,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept while True:
events=sel.select() #检测所有的fileobj,是否有完成wait data的
for sel_obj,mask in events:
callback=sel_obj.data #callback=accpet
callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1) #客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8088)) while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
不良影响:
1. 虽说解决了单线程并发,但是大大的占用了cpu
2. 任务完成的响应延迟增大,任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低
总结 :
select的优势在于可以处理多个连接,不适用于单个连接
异步IO(asynchronous IO)
用户进程发起read操作之后,立刻就可以开始去做其它的事。
kernel 受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。
然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,
当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
socketserver 模块
包含类
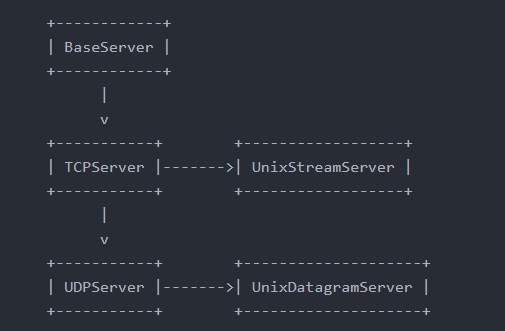
BaseServer是基类,它不能实例化使用,
TCPServer使用TCP协议通信,
UDPServer使用UDP协议通信,
UnixStreamServer和UnixDatagramServer使用Unix域套接字,只适用于UNIX平台。
ForkingMixIn 多进程异步
ThreadingMixIn 多线程异步
如何创建一个socketserver :
1. 创建一个请求处理的类,继承 BaseRequestHandlerclass ,要重写父类里 handle() 方法;
2. 你必须实例化 TCPServer,并且传递server IP和你上面创建的请求处理类,给这个TCPServer;
3. server.handle_requese() 只处理一个请求,server.server_forever() 处理多个一个请求,永远执行
4. 关闭连接 server_close()
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler): #服务类,监听绑定等等
def handle(self): #请求处理类,所有请求的交互都是在handle里执行的
# self.request is the TCP socket connected to the client
self.data = self.request.recv(1024).strip() #每一个请求都会实例化MyTCPHandler(socketserver.BaseRequestHandler):
print("{} wrote:".format(self.client_address[0]))
print(self.data)
self.request.sendall(self.data.upper()) #sendall是重复调用send.
if __name__ == "__main__":
HOST, PORT = "localhost", 9999
server = socketserver.TCPServer((HOST, PORT), MyTCPHandler)
# Activate the server; this will keep running until you
# interrupt the program with Ctrl-C
server.serve_forever()
server = socketserver.ThreadingTCPServer((HOST, PORT), MyTCPHandler) #线程
# server = socketserver.ForkingTCPServer((HOST, PORT), MyTCPHandler) #多进程 linux适用
# server = socketserver.TCPServer((HOST, PORT), MyTCPHandler) 单进程
ThreadingTCPServer
服务器内部会为每个client创建一个 “线程”,该线程用来和客户端进行交互。
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
pass
if __name__ == '__main__':
server = SocketServer.ThreadingTCPServer(('127.0.0.1',8766), MyServer)
server.serve_forever()
ForkingTCPServer
用法类似 ThreadingTCPServer 只是将线程换成了进程
import SocketServer
class MyServer(SocketServer.BaseRequestHandler):
def handle(self):
pass
if __name__ == '__main__':
server = SocketServer.ForkingTCPServer(('127.0.0.1',8009),MyServer)
server.serve_forever()
总结:
socketserver 完美的解决了之前的各种困扰。不论是并发问题还是线程池大小以及IO问题都被解决。
因此socketserver成为了最终解决方案
4.6 并发编程/IO模型的更多相关文章
- python 并发编程 io模型 目录
python 并发编程 IO模型介绍 python 并发编程 socket 服务端 客户端 阻塞io行为 python 并发编程 阻塞IO模型 python 并发编程 非阻塞IO模型 python 并 ...
- Python Web学习笔记之并发编程IO模型
了解新知识之前需要知道的一些知识 同步(synchronous):一个进程在执行某个任务时,另外一个进程必须等待其执行完毕,才能继续执行 #所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调 ...
- Python之并发编程-IO模型
目录 一.IO模型介绍二.阻塞IO(blocking IO)三.非阻塞IO(non-blocking IO)四.多路复用IO(IO multiplexing)五.异步IO(Asynchronous I ...
- 并发编程 - io模型 - 总结
1.提交任务得方式: 同步:提交完任务,等结果,执行下一个任务 异步:提交完,接着执行,异步 + 回调 异步不等结果,提交完任务,任务执行完后,会自动触发回调函数2.同步不等于阻塞: 阻塞:遇到io, ...
- python并发编程&IO模型
一 IO模型介绍 为了更好地了解IO模型,可先回顾下:同步.异步.阻塞.非阻塞 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(n ...
- 并发编程——IO模型
前言 同步(synchronous):一个进程在执行某个任务时,另外一个进程必须等待其执行完毕,才能继续执行 #所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回.按照这个定义, ...
- 并发编程——IO模型详解
我是一个Python技术小白,对于我而言,多任务处理一般就借助于多进程以及多线程的方式,在多任务处理中如果涉及到IO操作,则会接触到同步.异步.阻塞.非阻塞等相关概念,当然也是并发编程的基础. ...
- 15 并发编程-(IO模型)
一.IO模型介绍 1.阻塞与非阻塞指的是程序的两种运行状态 阻塞:遇到IO就发生阻塞,程序一旦遇到阻塞操作就会停在原地,并且立刻释放CPU资源 非阻塞(就绪态或运行态):没有遇到IO操作,或者通过某种 ...
- 并发编程——IO模型(6)
1.IO模型分类 同步IO #所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回.按照这个定义,其实绝大多数函数都是同步调用.但是一般而言,我们在说同步.异步的时候,特指那些需要 ...
随机推荐
- windows相关命令记录
1.regedit 打开注册表 2.services.msc 打开服务列表 3.net start/stop 服务名 打开/关闭服务,例:net start mysql57,可以通过服务列表开启/关闭 ...
- 浏览器登录Dynamics 365 CE没毛病,程序连接却报错。
摘要: 微软动态CRM专家罗勇 ,回复308或者20190308可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me . 今天我做实验 ...
- 五、RemoteViews
RemoteViews表示的是一个View结构,它可以在其他进程中显示.RemoteViews在Android中的使用场景有两种:通知栏和桌面小部件. 1.RemoteViews的应用 RemoteV ...
- PM真的不是PM
上周写了一篇<PM意识2.0>,前同事老A留言给我说:“PM已死!”一句话勾起很多回忆啊~当年,我们在一家内资IT公司,我是质量总监,他是研发总监,带四五个PM.老A负责所有项目的计划和监 ...
- log4j详细配置
参考博客:https://blog.csdn.net/sinat_30185177/article/details/73550377 log4j..很简单好用的一个记录日志的东东,正因为好用,本人从来 ...
- linux 按行分割文件
$ sudo awk 'NR%2==1{close(p".txt");++p}{print > p".txt"}' test.txt $ sudo spl ...
- ReSharper导致Visual Studio缓慢?
问题排查 我们会竭尽所能的ReSharper的性能方面,但是也有一些已知和未知的情况下,ReSharper的可以减缓的Visual Studio. 这里有一些关键点进行故障排除和修复ReSharper ...
- SQLServer之视图简介
视图定义 视图是一个虚拟表,其内容由查询定义. 同表一样,视图包含一系列带有名称的列和行数据. 视图在数据库中并不是以数据值存储集形式存在,除非是索引视图. 行和列数据来自由定义视图的查询所引用的表, ...
- Git常用命令集锦
本篇Git命令博客主要是一些Git常用命令,适合于有一定Git或linux基础的小伙伴进行参考 1.新建文件夹 mkdir 文件夹名 2.查看目录机构: pwd 3.将文件添加至Git管理范围:git ...
- Linux定是调用shell脚本删除文件
编写脚本 vi delbak.sh 代码如下: #!/bin/sh location="/home/mysql/backup/" find $location -mtime +7 ...