论文笔记:Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation
Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation
2019-04-24 16:53:25
Paper:https://arxiv.org/pdf/1903.02120.pdf
Code(unofficial PyTorch Implementation):https://github.com/LinZhuoChen/DUpsampling
1. Background and Motivation:
常规的 encoder-decoder 模型中,decoder 部分采用的是双线性插值的方法,进行分辨率的提升。但是,这种粗暴的方式,对分割问题适应吗?作者提出一种新颖的模型来替换掉双线性插值的方式,即依赖于数据的上采样模型(data-dependent upsampling (DUpsampling) to replace bilinear)。这么做的好处是:充分利用了语义分割问题 label space 的冗余性,并且可以恢复出 pixel-wise prediction。那么,具体该怎么做呢?在 DeepLabv3+ 中,decoder 的定义如下图所示:
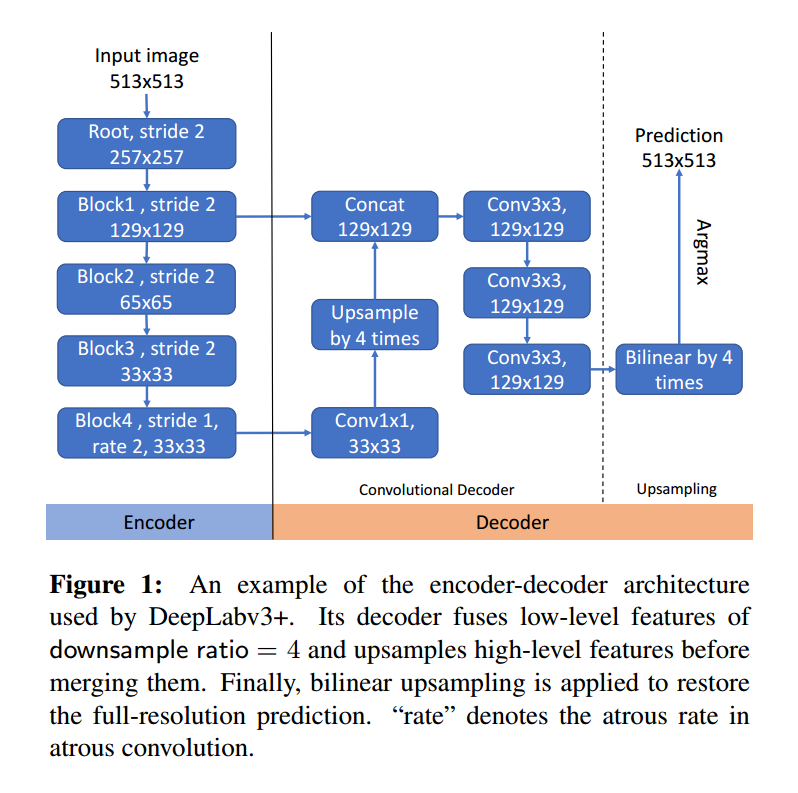
这种框架带来了如下的问题:
1). encode 的总体步长必须用多个空洞卷积来降低。这种操作需要很多的计算代价。
2). decoder 通常需要在底层融合特征。因为 bilinear 的问题,导致最终融合的拟合程度是由融合的底层特征分辨率决定的。这就导致,为了得到高分辨率的预测结果,decoder 就必须融合底层高分辨率的特征。这种约束,限制了 feature aggregation 的设计空间,从而得到的是 suboptimcal 的特征组合。在本文的实验中,作者发现:如果可以进行不受到分辨率约束的特征聚合,那么就可以设计更好的特征聚合的方法。
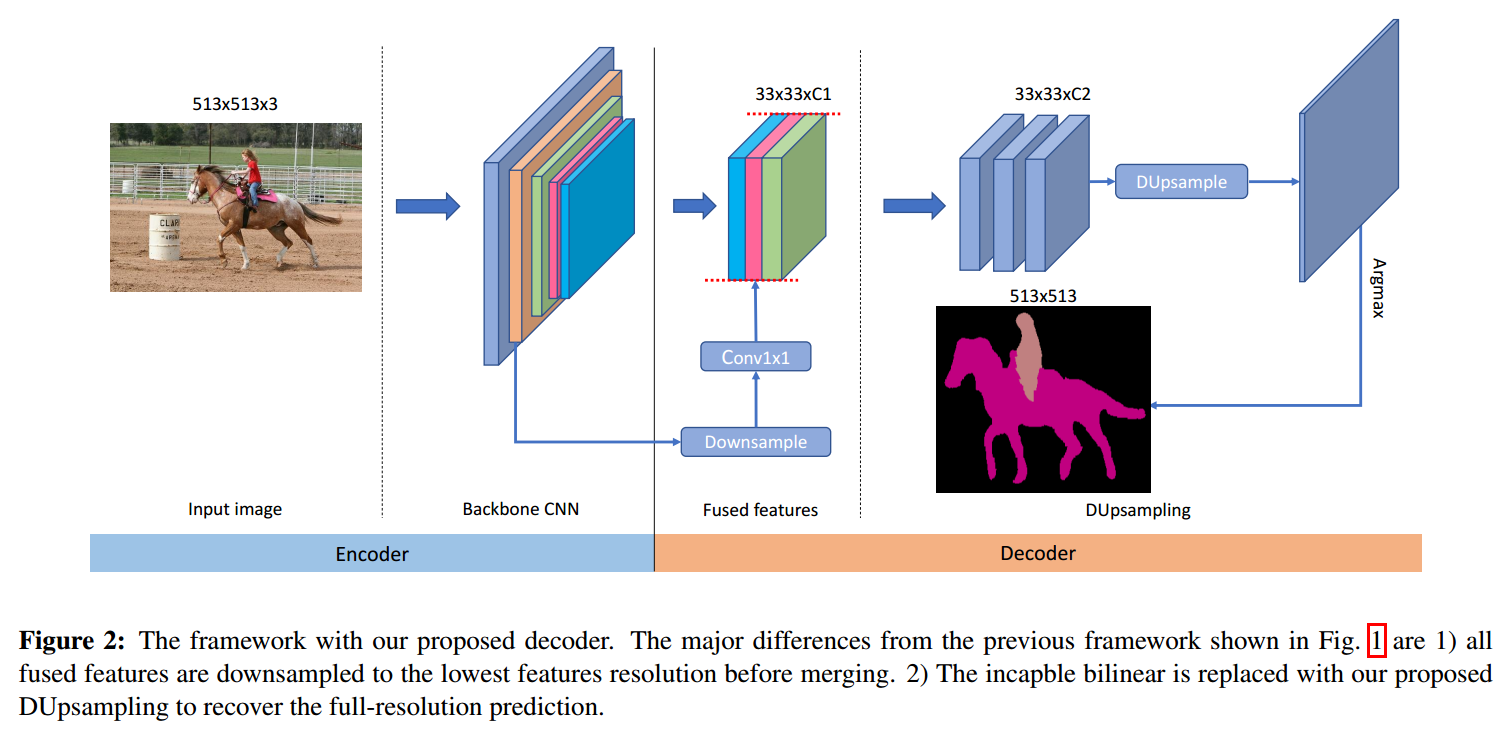
2. Our Approach:
2.1 Beyond Bilinear: Data-dependent Upsampling:
我们用 F 表示用 encoder 对输入图像进行卷积之后的输出特征,Y 表示其真值。常规的分割任务中,用到的损失函数如下所示:

此处,损失函数通常是 cross-entropy loss,而 bilinear 用于上采样 F 得到与 Y 相同分辨率的图像。作者认为此处用双线性插值的方式进行上采样,并非是最好的选择。所以,作者在这里不去计算 bilinear(F) 和 Y 之间的误差,而是去计算将 Y 降低分辨率后的图像和 F 之间的误差。注意到,这里 F 和降低分辨率后的 Y,是具有相同分辨率的。为了将 Y 进行压缩,作者用一种在一些度量方式下的转换,来最小化 Y 和 低分辨率 Y 之间的重构误差。具体来说,作者首先将 Y 进行划分,对于每一个 sub-window S,将其 reshape 成一个 {0, 1} 向量 v。最终,我们压缩 v 为低维度的向量 x,然后水平和竖直的进行堆叠 x,构成最终  。
。
所以,这里的转换可以用矩阵 P 和 W 来表示,即:
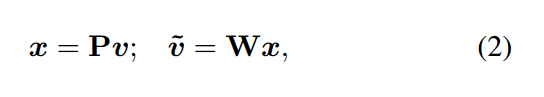
我们可以在训练集上通过最小化重构误差,来学习得到 P 和 W:
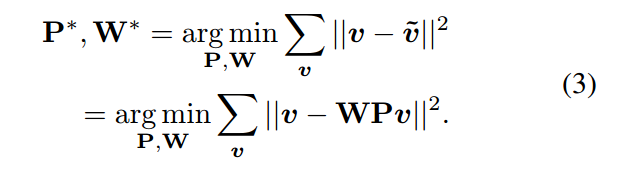
作者用 PCA 的方法可以得到该函数的闭合解。从而,可以得到关于真值 Y 的压缩版本真值。有了这个作为学习的目标,我们可以 pre-train 一个网络模型,通过计算其回归损失函数,如下所示:
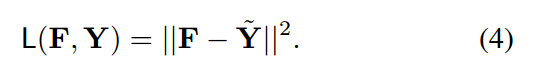
所以,任何的回归损失,l2 可以用于上述公式 4。但是,作者认为更直观的一种方式是计算在 Y 空间内的损失。所以,作者用学习到的重构矩阵 W 来上采样 F,然后计算反压缩的 F 和 Y 之间的误差,而不是对 Y 进行压缩处理:
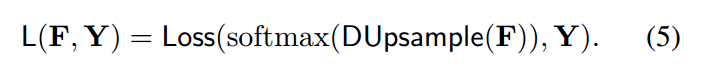
这里的 DUpsample(F)的过程,如下图所示:
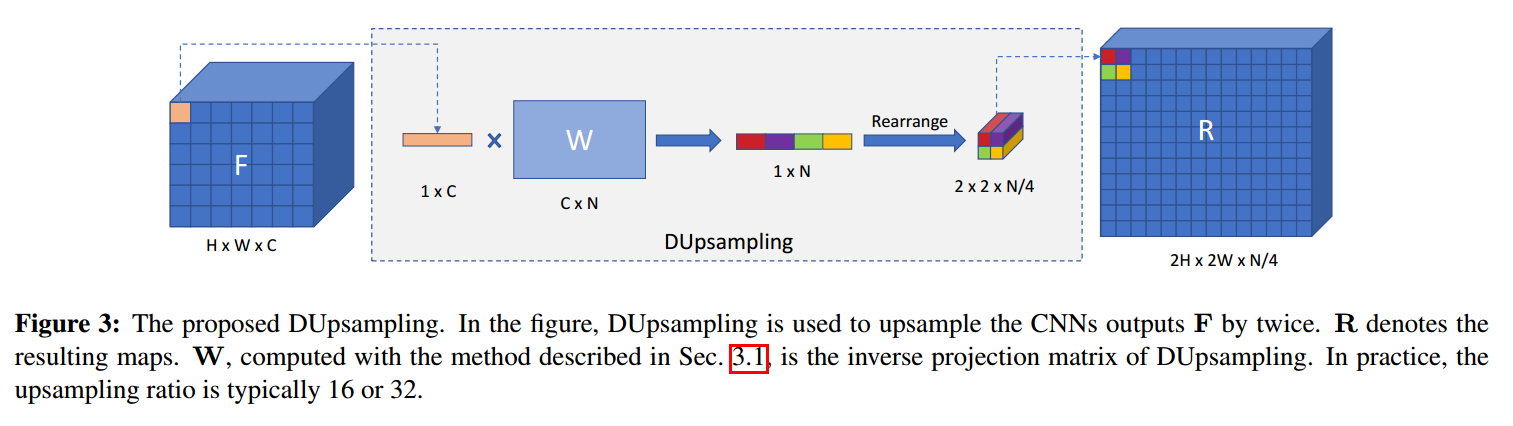
有了这个线性转换的过程,DUpsample (F) 采用线性上采样的方式对每一个 feature f 进行处理 Wf。与公式 1 相比,我们已经用一种 data-dependent upsampling 的方式,替换掉了 the bilinear upsampling 的方法,而这种转换矩阵,是从真值 labels 上进行学习。这种上采样的过程,与 1*1 卷积的相同,也是沿着 spatial dimension,卷积核是存在 W 中。这个 decompression 的过程,如上图 3 所示。
2.2 Incorporatinig DUpsampling with Adaptive-temperature Softmax :
截止目前为止,我们已经介绍了如何将这种 DUpsampling 结合到 decoder 中,接下来将会介绍如何将其结合到 encoder-decoder framework 中。由于 DUpsampling 可以用 1*1 的卷积操作来实现,将其直接结合到该框架中,会遇到优化的问题,即:收敛非常慢。为了解决这个问题,我们采用 softmax function with temperature, 即在原始的 softmax 函数中,添加一个 temperature T,以 soften/sharpen the activation of softmax:
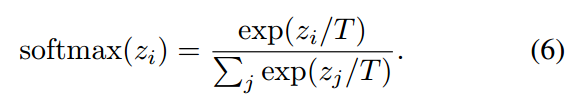
我们发现,T 可以自动的用反向传播进行学习,而不需要微调。
2.3 Flexible Aggregation of Covolutional Features :
当然原始 feature aggregation 的方法是存在如下问题的:

主要问题是:
1). f is applied after upsampling. Since f is a CNN, whose amount of computation depends on the spatial size of inputs, this arrangement would render the decoder inefficient computationally. Moreover, the computational overhead prevents the decoder from exploiting features at a very low level.
2). The resolution of fused low-level features Fi is equivalent to that of F, which is typically around 1/4 resolution of the final prediction due to the incapable bilinear used to produce the final pixel-wise prediction. In order to obtain high-resolution prediction, the decoder can only choose the feature aggregation with high-resolution low-level features.
此外,本文的另外一个亮点在于:本文的多层特征的融合,不在局限于底层特征。作者将原始的 feature map,都进行降采样成统一的维度,然后沿着 channel 的方向,进行拼合。
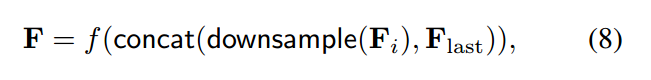
作者发现,仅当使用了作者提出的 DUpsampling layer 的时候,这种下采样拼合的方式,才可以提升最终分割的精度。
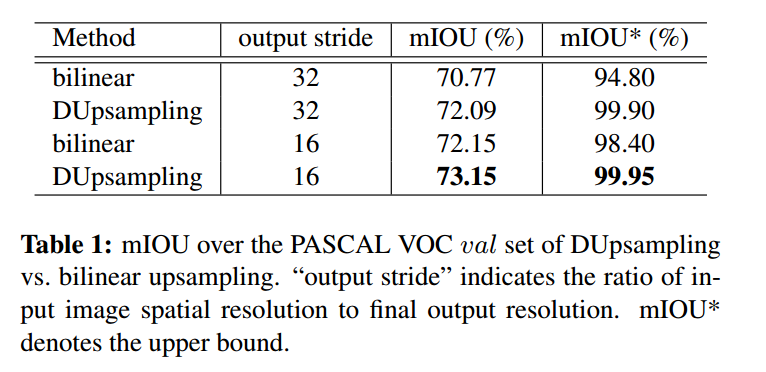
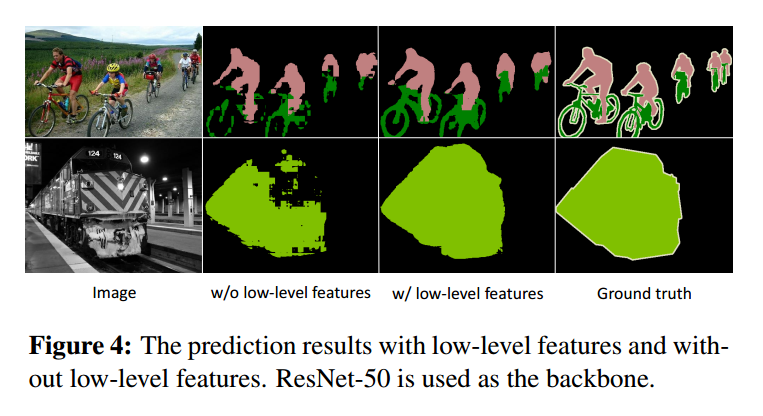
3. Experiment:

==
论文笔记:Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation的更多相关文章
- Decoders Matter for Semantic Segmentation:Data-Dependent Decoding Enables Flexible Feature Aggregation
Decoders Matter for Semantic Segmentation:Data-Dependent Decoding Enables Flexible Feature Aggregati ...
- 论文笔记之:Instance-aware Semantic Segmentation via Multi-task Network Cascades
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai Kaiming He Jian Sun ...
- 论文笔记:Concept Mask: Large-Scale Segmentation from Semantic Concepts
Concept Mask: Large-Scale Segmentation from Semantic Concepts 2018-08-21 11:16:07 Paper:https://arxi ...
- 论文笔记:Dynamic Multimodal Instance Segmentation Guided by Natural Language Queries
Dynamic Multimodal Instance Segmentation Guided by Natural Language Queries 2018-09-18 09:58:50 Pape ...
- 论文笔记:Capsules for Object Segmentation
Capsules for Object Segmentation 2018-04-16 21:49:14 Introduction: ----
- 论文笔记 - GRAD-MATCH: A Gradient Matching Based Data Subset Selection For Efficient Learning
Analysis Coreset 是带有权重的数据子集,目的是在某个方面模拟完整数据的表现(例如损失函数的梯度,既可以是在训练数据上的损失,也可以是在验证数据上的损失): 给出优化目标的定义: $w^ ...
- 论文笔记《Feedforward semantic segmentation with zoom-out features》
[论文信息] <Feedforward semantic segmentation with zoom-out features> CVPR 2015 superpixel-level,f ...
- FCIS:Fully Convolutional Instance-aware Semantic Segmentation
论文:Fully Convolutional Instance-aware Semantic Segmentation 目录 0.简介 1.Position-sensitive Score Map ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
随机推荐
- Tomcat出现端口占用错误
Several ports (8005, 8080, 8009) required by Tomcat v8.5 Server at localhost are already in use. The ...
- VUE-010-通过声明式导航 router-link 传递 params 参数(路由 name 识别,请求链接不显示参数传递)
在前端页面表单列表修改时,经常需要在页面切换的时候,传递需要修改的表单内容,除了通过路由进行表单参数的传递,也可通过声明式导航 router-link 进行页面跳转和参数传递. 首先,配置页面跳转路由 ...
- Copy & XCopy
1):copy不能在有子目录存在的文件中拷贝文件的同时重命名此文件名(注:这里C:为根目录,bat为子目录),而xcopy能,不过会出现提示,当然你可以加参数而不使它提示. C:\>copy c ...
- Spring Cloud微服务架构图
- Java-接口(interface)
1.1接口的定义 java中接口是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为(功能). 接口 ...
- ubuntu16.04 backup and restore
http://blog.csdn.net/qq_35523593/article/details/78545530
- MongoDB在Windows系统下的安装和启动
版本选择MongoDB的版本命名规范如:x.y.z: y为奇数时表示当前版本为开发版,如:2.3.0.2.1.1: y为偶数时表示当前版本为稳定版,如:2.0.1.2.2.0: 目前官网上最新的版本为 ...
- HTML表单简单练习
代码: <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <tit ...
- CentOS 7 安装配置KVM 通过KVM安装CentOS系统
搭建环境 : CentOS 7 [root@KVM ~]# systemctl stop firewalld [root@KVM ~]# systemctl disable firewalld [ro ...
- react16实战总结
实战总结 react实战基础 遇到的一些坑 li里要带key值否则会警告,这个问题在vue中也存在, 考虑到虚拟DOM中diff,所以不要用index作为key值,而要用item. 2.immutab ...