数据结构之哈希(hash)表
最近看PHP数组底层结构,用到了哈希表,所以还是老老实实回去看结构,在这里去总结一下。
1.哈希表的定义
这里先说一下哈希(hash)表的定义:哈希表是一种根据关键码去寻找值的数据映射结构,该结构通过把关键码映射的位置去寻找存放值的地方,说起来可能感觉有点复杂,我想我举个例子你就会明白了,最典型的的例子就是字典,大家估计小学的时候也用过不少新华字典吧,如果我想要获取“按”字详细信息,我肯定会去根据拼音an去查找 拼音索引(当然也可以是偏旁索引),我们首先去查an在字典的位置,查了一下得到“安”,结果如下。这过程就是键码映射,在公式里面,就是通过key去查找f(key)。其中,按就是关键字(key),f()就是字典索引,也就是哈希函数,查到的页码4就是哈希值。
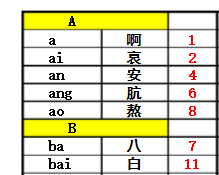
通过字典查询数据
2.哈希冲突
但是问题又来了,我们要查的是“按”,而不是“安,但是他们的拼音都是一样的。也就是通过关键字按和关键字安可以映射到一样的字典页码4的位置,这就是哈希冲突(也叫哈希碰撞),在公式上表达就是key1≠key2,但f(key1)=f(key2)。冲突会给查找带来麻烦,你想想,你本来查找的是“按”,但是却找到“安”字,你又得向后翻一两页,在计算机里面也是一样道理的。
但哈希冲突是无可避免的,为什么这么说呢,因为你如果要完全避开这种情况,你只能每个字典去新开一个页,然后每个字在索引里面都有对应的页码,这就可以避免冲突。但是会导致空间增大(每个字都有一页)。
既然无法避免,就只能尽量减少冲突带来的损失,而一个好的哈希函数需要有以下特点:
1.尽量使关键字对应的记录均匀分配在哈希表里面(比如说某厂商卖30栋房子,均匀划分ABC3个区域,如果你划分A区域1个房子,B区域1个房子,C区域28个房子,有人来查找C区域的某个房子最坏的情况就是要找28次)。
2.关键字极小的变化可以引起哈希值极大的变化。
比较好的哈希函数是time33算法。PHP的数组就是把这个作为哈希函数。
核心的算法就是如下:
unsigned long hash(const char* key){
unsigned long hash=;
for(int i=;i<strlen(key);i++){
hash = hash*+str[i];
}
return hash;
}
3.哈希冲突解决办法
如果遇到冲突,哈希表一般是怎么解决的呢?具体方法有很多,百度也会有一堆,最常用的就是开发定址法和链地址法。
1.开发定址法
如果遇到冲突的时候怎么办呢?就找hash表剩下空余的空间,找到空余的空间然后插入。就像你去商店买东西,发现东西卖光了,怎么办呢?找下一家有东西卖的商家买呗。
由于我没有深入试验过,所以贴上在书上的解释:

2.链地址法
上面所说的开发定址法的原理是遇到冲突的时候查找顺着原来哈希地址查找下一个空闲地址然后插入,但是也有一个问题就是如果空间不足,那他无法处理冲突也无法插入数据,因此需要装填因子(插入数据/空间)<=1。
那有没有一种方法可以解决这种问题呢?链地址法可以,链地址法的原理时如果遇到冲突,他就会在原地址新建一个空间,然后以链表结点的形式插入到该空间。我感觉业界上用的最多的就是链地址法。下面从百度上截取来一张图片,可以很清晰明了反应下面的结构。比如说我有一堆数据{1,12,26,337,353...},而我的哈希算法是H(key)=key mod 16,第一个数据1的哈希值f(1)=1,插入到1结点的后面,第二个数据12的哈希值f(12)=12,插入到12结点,第三个数据26的哈希值f(26)=10,插入到10结点后面,第4个数据337,计算得到哈希值是1,遇到冲突,但是依然只需要找到该1结点的最后链结点插入即可,同理353。
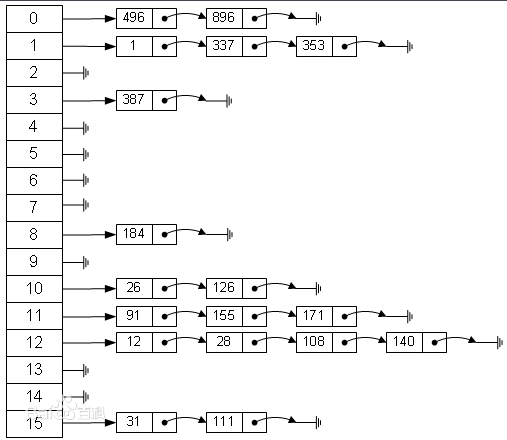
哈希表的拉链法实现
下面解析一下如何用C++实现链地址法。
第一步。
肯定是构建哈希表。
首先定义链结点,以结构体Node展示,其中Node有三个属性,一个是key值,一个value值,还有一个是作为链表的指针。还有作为类的哈希表。
#define HASHSIZE 10
typedef unsigned int uint;
typedef struct Node{
const char* key;
const char* value;
Node *next;
}Node; class HashTable{
private:
Node* node[HASHSIZE];
public:
HashTable();
uint hash(const char* key);
Node* lookup(const char* key);
bool install(const char* key,const char* value);
const char* get(const char* key);
void display();
};
然后定义哈希表的构造方法
HashTable::HashTable(){
for (int i = ; i < HASHSIZE; ++i)
{
node[i] = NULL;
}
}
第二步。
定义哈希表的Hash算法,在这里我使用time33算法。
uint HashTable::hash(const char* key){
uint hash=;
for (; *key; ++key)
{
hash=hash*+*key;
}
return hash%HASHSIZE;
}
第三步。
定义一个查找根据key查找结点的方法,首先是用Hash函数计算头地址,然后根据头地址向下一个个去查找结点,如果结点的key和查找的key值相同,则匹配成功。
Node* HashTable::lookup(const char* key){
Node *np;
uint index;
index = hash(key);
for(np=node[index];np;np=np->next){
if(!strcmp(key,np->key))
return np;
}
return NULL;
}
第四步。
定义一个插入结点的方法,首先是查看该key值的结点是否存在,如果存在则更改value值就好,如果不存在,则插入新结点。
bool HashTable::install(const char* key,const char* value){
uint index;
Node *np;
if(!(np=lookup(key))){
index = hash(key);
np = (Node*)malloc(sizeof(Node));
if(!np) return false;
np->key=key;
np->next = node[index];
node[index] = np;
}
np->value=value;
return true;
}
4.关于哈希表的性能
由于哈希表高效的特性,查找或者插入的情况在大多数情况下可以达到O(1),时间主要花在计算hash上,当然也有最坏的情况就是hash值全都映射到同一个地址上,这样哈希表就会退化成链表,查找的时间复杂度变成O(n),但是这种情况比较少,只要不要把hash计算的公式外漏出去并且有人故意攻击(用兴趣的人可以搜一下基于哈希冲突的拒绝服务攻击),一般也不会出现这种情况。
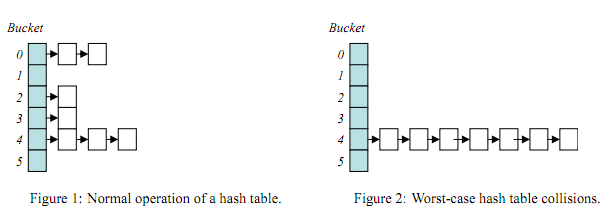
哈希冲突攻击导致退化成链表
数据结构之哈希(hash)表的更多相关文章
- Redis数据结构:字典(hash表)
使用场景: # set person name "tom" # set person name "jerry" 1. 字典结构: 哈希表数据结构 typedef ...
- HDU5183 hash 表
做题的时候忘了 数据结构老师说的hash表了, 用二分找,还好过了, hash 表 对这题 更快一些 #include <iostream> #include <algorithm& ...
- 数据结构,哈希表hash设计实验
数据结构实验,hash表 采用链地址法处理hash冲突 代码全部自己写,转载请留本文连接, 附上代码 #include<stdlib.h> #include<stdio.h> ...
- Redis原理再学习04:数据结构-哈希表hash表(dict字典)
哈希函数简介 哈希函数(hash function),又叫散列函数,哈希算法.散列函数把数据"压缩"成摘要,有的也叫"指纹",它使数据量变小且数据格式大小也固定 ...
- java数据结构之hash表
转自:http://www.cnblogs.com/dolphin0520/archive/2012/09/28/2700000.html Hash表也称散列表,也有直接译作哈希表,Hash表是一种特 ...
- php 数据结构 hash表
hash表 定义 hash表定义了一种将字符组成的字符串转换为固定长度(一般是更短长度)的数值或索引值的方法,称为散列法,也叫哈希法.由于通过更短的哈希值比用原始值进行数据库搜索更快,这种方法一般用来 ...
- Hash 表详解(哈希表)
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度.这个映射函数叫做散列 ...
- 哈希表(散列表),Hash表漫谈
1.序 该篇分别讲了散列表的引出.散列函数的设计.处理冲突的方法.并给出一段简单的示例代码. 2.散列表的引出 给定一个关键字集合U={0,1......m-1},总共有不大于m个元素.如果m不是很大 ...
- 哈希表(散列表)—Hash表解决地址冲突 C语言实现
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度.具体的介绍网上有很详 ...
随机推荐
- Windows本地代码仓库使用连接教程
目录 软件安装 修改语言为中文 克隆远程仓库 文件上传教程 软件安装 安装Git(软件下载链接) 根据自己的系统选择对应版本下载安装 安装TortoiseGit(软件下载链接) 1.下载完毕解压文件夹 ...
- python3.5.2库getpass
getpass的功能是:允许隐式的输入字符串 import getpass _username='vigossr' _password='haha' username=input('username: ...
- linq给list集合数据分页
var lastlist= newlist.Skip(pageindex * pagesize).Take(pagesize);
- 我和python的初相识
认识Python是大二的选修 单纯只是想赚学分而已 后来觉得越来越有趣. 一.python简介 简单来说Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言.Python 的设 ...
- Android Architecture Components--项目实战
转载请注明出处,谢谢! 上个月Google Android Architecture Components 1.0稳定版发布,抽工作间隙写了个demo,仅供参考 Github地址:https://gi ...
- C# datatable 重新排序
DataTable table = distributionManageService.Tb_fund_withdrawaGetPageList(pagination, queryJson);//设置 ...
- let和const
ES6新增了let取代var,let主要有以下特点. 1 只在代码块内有效,代码块外不能使用let声明的变量.let很适合声明循环体的变量. 它可以解决一些闭包的问题存在的问题比如: var a = ...
- Servlet 过滤器Filter
特点 1)Filter是依赖于Servlet容器,属于Servlet规范的一部分,在Servlet API中定义了三个接口类:Filter, FilterChain, FilterConfig. 2) ...
- Dora.Interception,为.NET Core度身打造的AOP框架 [2]:以约定的方式定义拦截器
上一篇<更加简练的编程体验>提供了最新版本的Dora.Interception代码的AOP编程体验,接下来我们会这AOP框架的编程模式进行详细介绍,本篇文章着重关注的是拦截器的定义.采用“ ...
- Hadoop 数据去重
数据去重这个实例主要是为了读者掌握并利用并行化思想对数据进行有意义的筛选.统计大数据集上的数据种类个数.从网站日志中计算访问等这些看似庞杂的任务都会涉及数据去重.下面就进入这个实例的MapReduce ...