【机器学习】--线性回归中L1正则和L2正则
一、前述
L1正则,L2正则的出现原因是为了推广模型的泛化能力。相当于一个惩罚系数。
二、原理
L1正则:Lasso Regression
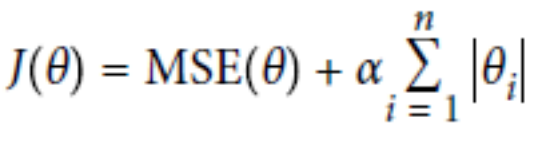
L2正则:Ridge Regression

总结:
经验值 MSE前系数为1 ,L1 , L2正则前面系数一般为0.4~0.5 更看重的是准确性。
L2正则会整体的把w变小。
L1正则会倾向于使得w要么取1,要么取0 ,稀疏矩阵 ,可以达到降维的角度。
ElasticNet函数(把L1正则和L2正则联合一起):

总结:
1.默认情况下选用L2正则。
2.如若认为少数特征有用,可以用L1正则。
3.如若认为少数特征有用,但特征数大于样本数,则选择ElasticNet函数。
代码一:L1正则
# L1正则
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) lasso_reg = Lasso(alpha=0.15)
lasso_reg.fit(X, y)
print(lasso_reg.predict(1.5)) sgd_reg = SGDRegressor(penalty='l1')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
代码二:L2正则
# L2正则
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) #两种方式第一种岭回归
ridge_reg = Ridge(alpha=1, solver='auto')
ridge_reg.fit(X, y)
print(ridge_reg.predict(1.5))#预测1.5的值
#第二种 使用随机梯度下降中L2正则
sgd_reg = SGDRegressor(penalty='l2')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
代码三:Elastic_Net函数
# elastic_net函数
import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
#两种方式实现Elastic_net
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net.fit(X, y)
print(elastic_net.predict(1.5)) sgd_reg = SGDRegressor(penalty='elasticnet')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
【机器学习】--线性回归中L1正则和L2正则的更多相关文章
- 【机器学习】--鲁棒性调优之L1正则,L2正则
一.前述 鲁棒性调优就是让模型有更好的泛化能力和推广力. 二.具体原理 1.背景 第一个更好,因为当把测试集带入到这个模型里去.如果测试集本来是100,带入的时候变成101,则第二个模型结果偏差很大, ...
- 贝叶斯先验解释l1正则和l2正则区别
这里讨论机器学习中L1正则和L2正则的区别. 在线性回归中我们最终的loss function如下: 那么如果我们为w增加一个高斯先验,假设这个先验分布是协方差为 的零均值高斯先验.我们在进行最大似然 ...
- L1正则和L2正则的比较分析详解
原文链接:https://blog.csdn.net/w5688414/article/details/78046960 范数(norm) 数学上,范数是一个向量空间或矩阵上所有向量的长度和大小的求和 ...
- L1正则与L2正则
L1正则是权值的绝对值之和,重点在于可以稀疏化,使得部分权值等于零. L1正则的含义是 ∥w∥≤c,如下图就可以解释为什么会出现权值为零的情况. L1正则在梯度下降的时候不可以直接求导,可以有以下几种 ...
- L1 正则 和 L2 正则的区别
L1,L2正则都可以看成是 条件限制,即 $\Vert w \Vert \leq c$ $\Vert w \Vert^2 \leq c$ 当w为2维向量时,可以看到,它们限定的取值范围如下图: 所以它 ...
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- 大白话5分钟带你走进人工智能-第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归
第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归 上一节中我们讲解了L1和L2正则的概念,知道了L1和L2都会使不重要的维度权重下降得多,重要的维度权重下降得少,引入 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
随机推荐
- idea中自动生成实体类
找到生成实体的路径,找到Database数据表 找到指定的路径即可自动生成entity实体 在创建好的实体类内如此修改 之后的步骤都在脑子里 写给自己看的东西 哪里不会就记录哪里 test类(以前都 ...
- webpack问题列表及解决方案
1.提升webpack打包速度 2.cssloader顺序有先后 3.如何正确引用图片 4.打包后访问不到json文件 5.打包后如何访问项目 6.打包后的文件 7.为什么执行webpack,就可以打 ...
- python爬取房天下数据Demo
import requests from bs4 import BeautifulSoup res = requests.get('http://sh.esf.fang.com/chushou/3_3 ...
- Bad Hair Day [POJ3250] [单调栈 或 二分+RMQ]
题意Farmer John的奶牛在风中凌乱了它们的发型……每只奶牛都有一个身高hi(1 ≤ hi ≤ 1,000,000,000),现在在这里有一排全部面向右方的奶牛,一共有N只(1 ≤ N ≤ 80 ...
- MyBatis(八)联合查询 级联属性封装结果集
(1)接口中编写方法 public Emp getEmpandDept(); (2)编写Mapper文件 <resultMap type="com.eu.bean.Emp" ...
- emoji 表情: MySQL如何支持 emoji 表情
https://www.cnblogs.com/jentary/p/6655471.html 修改数据库字符集: ALTER DATABASE database_name CHARACTER SET ...
- Redis安装及使用
1.我们可以通过在官网下载tar.gz的安装包,或者通过wget的方式下载 进入要下载到的文件夹: wget http://download.redis.io/releases/redis-4.0.1 ...
- python--ModuleFoundError
python 模块导入错误: 1. 首先py文件名不能和导入的模块名相同 (我在学习matplotlib库的时候就把文件名设置成matplotlib 多次运行不成功) 2. 由于我电脑上只有numpy ...
- jsp 表单回显
1.在表单各个字段中添加value属性,如:value="${user.reloginpass }" 2.在表单提交对应的servlet中封装数据到uer中,如:req.setAt ...
- C# WinForm:DataTable中数据复制粘贴操作的实现
1. 需要实现类似于Excel的功能,就是在任意位置选中鼠标起点和终点所连对角线所在的矩形,进行复制粘贴. 2. 要实现这个功能,首先需要获取鼠标起点和终点点击的位置. 3. 所以通过GridView ...