【机器学习】--鲁棒性调优之L1正则,L2正则
一、前述
鲁棒性调优就是让模型有更好的泛化能力和推广力。
二、具体原理
1、背景

第一个更好,因为当把测试集带入到这个模型里去。如果测试集本来是100,带入的时候变成101,则第二个模型结果偏差很大,而第一个模型偏差不是很大。
2、目的
鲁棒性就是为了让w参数也就是模型变小,但不是很小。所以引出了 L1和L2正则。
L1和L2的使用就是让w参数减小的使用就是让w参数减小。
L1正则,L2正则的出现原因是为了推广模型的泛化能力。相当于一个惩罚系数。

3、具体使用
L1正则:Lasso Regression
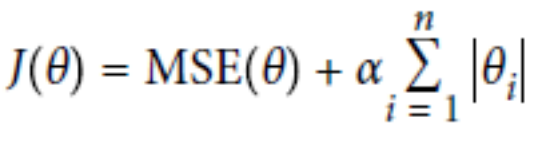
L2正则:Ridge Regression

总结:
经验值 MSE前系数为1 ,L1 , L2正则前面系数一般为0.4~0.5 更看重的是准确性。
L2正则会整体的把w变小。
L1正则会倾向于使得w要么取1,要么取0 ,稀疏矩阵 ,可以达到降维的角度。
ElasticNet函数(把L1正则和L2正则联合一起):

总结:
1.默认情况下选用L2正则。
2.如若认为少数特征有用,可以用L1正则。
3.如若认为少数特征有用,但特征数大于样本数,则选择ElasticNet函数。
4、在保证正确率的情况下加上正则。
5、如果把lamda设置成0,就只看准确率。
6、如果把lamda设置大些,就看中推广能力。
7、L1倾向于使得w要么取1,要么取0 稀疏编码 可以降维
8、L2倾向于使得w整体偏小 岭回归 首选
4、图示
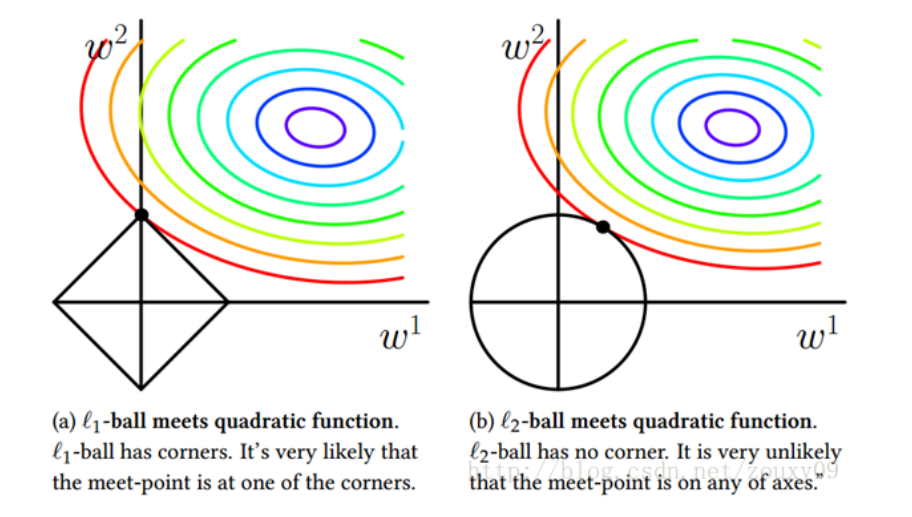
左边是L1正则+基本损失函数
右边是L2正则+基本损失函数
中间部分是圆心,损失函数最小,与正则函数相交,则既要满足基本函数,也要满足L1,L2正则,则损失函数增大了。
w1,w2等等与基本函数相交,则w1,w2都在[0,1]之间。
三、代码演示
代码一:L1正则
# L1正则
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) lasso_reg = Lasso(alpha=0.15)
lasso_reg.fit(X, y)
print(lasso_reg.predict(1.5)) sgd_reg = SGDRegressor(penalty='l1')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
代码二:L2正则
# L2正则
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) #两种方式第一种岭回归
ridge_reg = Ridge(alpha=1, solver='auto')
ridge_reg.fit(X, y)
print(ridge_reg.predict(1.5))#预测1.5的值
#第二种 使用随机梯度下降中L2正则
sgd_reg = SGDRegressor(penalty='l2')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
代码三:Elastic_Net函数
# elastic_net函数
import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
#两种方式实现Elastic_net
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net.fit(X, y)
print(elastic_net.predict(1.5)) sgd_reg = SGDRegressor(penalty='elasticnet')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
【机器学习】--鲁棒性调优之L1正则,L2正则的更多相关文章
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- 大白话5分钟带你走进人工智能-第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归
第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归 上一节中我们讲解了L1和L2正则的概念,知道了L1和L2都会使不重要的维度权重下降得多,重要的维度权重下降得少,引入 ...
- 机器学习:模型泛化(L1、L2 和弹性网络)
一.岭回归和 LASSO 回归的推导过程 1)岭回归和LASSO回归都是解决模型训练过程中的过拟合问题 具体操作:在原始的损失函数后添加正则项,来尽量的减小模型学习到的 θ 的大小,使得模型的泛化能力 ...
- L1与L2正则(转)
概念: L0范数表示向量中非零元素的个数:NP问题,但可以用L1近似代替. L1范数表示向量中每个元素绝对值的和: L1范数的解通常是稀疏性的,倾向于选择:1. 数目较少的一些非常大的值 2. 数目 ...
- 机器学习中规范化项:L1和L2
规范化(Regularization) 机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L ...
- 【笔记】简谈L1正则项L2正则和弹性网络
L1,L2,以及弹性网络 前情提要: 模型泛化与岭回归与LASSO 正则 ridge和lasso的后面添加的式子的格式上其实和MSE,MAE,以及欧拉距离和曼哈顿距离是非常像的 虽然应用场景不同,但是 ...
- L1和L2正则
https://blog.csdn.net/jinping_shi/article/details/52433975
- 【机器学习】--线性回归中L1正则和L2正则
一.前述 L1正则,L2正则的出现原因是为了推广模型的泛化能力.相当于一个惩罚系数. 二.原理 L1正则:Lasso Regression L2正则:Ridge Regression 总结: 经验值 ...
- 机器学习(二十三)— L0、L1、L2正则化区别
1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. 2.问题 1)实现参数的稀疏有什么好处吗? 一个好处是可以简化 ...
随机推荐
- 给xmpphp添加了几个常用的方法
给xmpphp添加给了以下的常用方法: registerNewUser //注册一个新用户 addRosterContact //发送添加好友的请求 acce ...
- C++雾中风景9:emplace_back与可变长模板
C++11的版本在vector容器添加了emplace_back方法,相对于原先的push_back方法能够在一定程度上提升vector容器的表现性能.所以我们从STL源码角度来切入,看看这两种方法有 ...
- 关于MySQL的1064错误
MySQL的1064错误是SQL语句写的有问题时出现的,即SQL的语法错误.笔者常常使用MySQL-python这个库来对MySQL进行操作,代码中报这个错误的一般是cursor.execute(sq ...
- sql server 内存初探
一. 前言 对于sql server 这个产品来说,内存这块是最重要的一个资源, 当我们新建一个会话,相同的sql语句查询第二次查询时间往往会比第一次快,特别是在sql统计或大量查询数据输出时,会有这 ...
- MySQL 开发实践
最近研发的项目对DB依赖比较重,梳理了这段时间使用MySQL遇到的8个比较具有代表性的问题,答案也比较偏自己的开发实践,没有DBA专业和深入,有出入的请使劲拍砖!- MySQL读写性能是多少,有哪些性 ...
- 夏娜的菠萝包 JDFZ1098
Description 问题描述:夏娜很喜欢吃菠萝包,她的经纪人RC每半个月就要为她安排接下来的菠萝包计划.今天是7月份,RC又要去商场进货买菠萝包了.这次RC总共买了N种菠萝包,每种一个.每个菠萝包 ...
- TiDB show processlist命令源码分析
背景 因为丰巢自去年年底开始在推送平台上尝试了TiDB,最近又要将承接丰巢所有交易的支付平台切到TiDB上.我本人一直没有抽出时间对TiDB的源码进行学习,最近准备开始一系列的学习和分享.由于我本人没 ...
- Django:Python3.6.2+Django2.0配置MySQL
持续学习Django中... Django默认使用的数据库是python自带的SQLlite3,但SQLlite并不适用于大型的项目,因此我将数据库换成了MySQL,下面介绍下Django如何配置数据 ...
- hive新建分区表
hive新建分区表语句如下: create table table_name (col1_name string comment '备注1', col2_name string comment '备注 ...
- java游戏开发杂谈 - 线程
线程,让游戏拥有了动态变化的能力. java的图形界面,在启动的时候,就开始了一个线程. 这个线程负责处理:JFrame.JPanel等的绘制.事件处理. 它是由操作系统调用的,在程序启动时开启,程序 ...