python requests模拟登陆正方教务管理系统,并爬取成绩
最近模拟带账号登陆,查看了一些他人的博客,发现正方教务已经更新了,所以只能自己探索了。
登陆:
通过抓包,发现需要提交的值
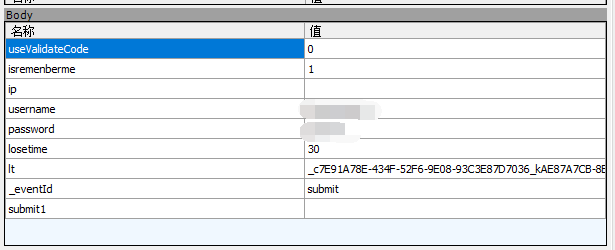
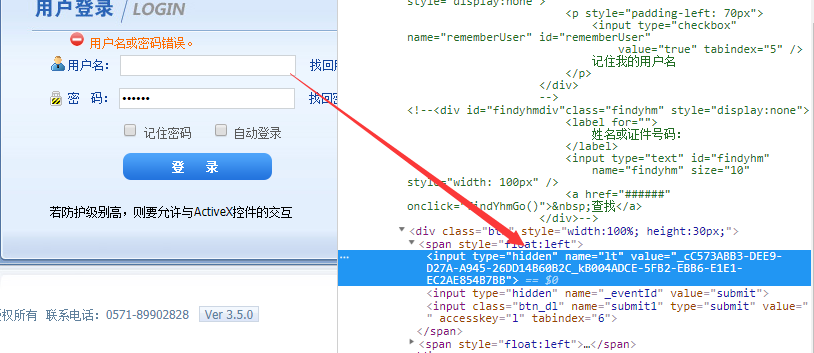
需要值lt,这是个啥,其实他在访问登陆页面时就产生了
session=requests.Session()
response = session.get(login_url, headers=header)
cookies = response.cookies
for c in cookies:
cookie = c.name + '=' + c.value
print('cookie-get:' + cookie)
selector = etree.HTML(response.text)
token = selector.xpath('//input[@name="lt"]/@value')[] # 解析出登陆所需的lt信息
print(token)
得到lt的值,加入到自己创建的表单中
根据上面抓包工具中需要的值,创建所需表单
login_data={
'useValidateCode': '',
'isremenberme': '',
'ip':'',
'username': username,
'password': password,
'losetime': '',
'lt': token,
'_eventId': 'submit',
'submit1':''
}
post请求登陆:
response = session.post(login_url, data=login_data, headers=header) print(response.status_code)
我们成功了,哈哈哈,很开心!

进入了主页面:
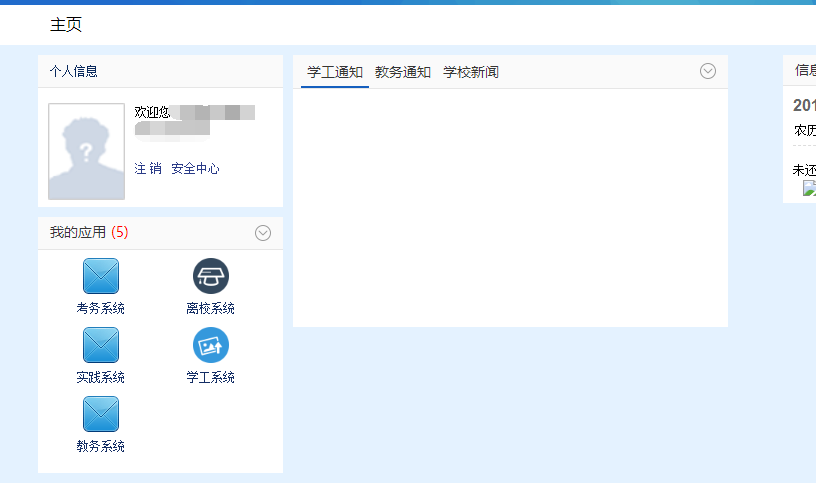
这是我们登进的页面,要爬取成绩,成绩在教务系统中,细心观察
get下链接:http://******/xs_main.aspx?xh=***&type=1
response = session.get(main_url, headers=header)
print(response.cookies)
print(response.status_code)
print(BeautifulSoup(response.text, 'lxml'))
response.status_code返回200,以为成功了?打印一下

额!难受,鬼刀一开,看不见........他竟然返回的是登陆界面?
究竟是什么问题呢,我怀疑是cookie:
因为
print(response.cookies)打印的值是: <RequestsCookieJar[]>
浏览器访问抓包看下
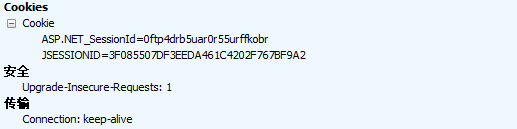
啊嘞嘞,why?
查看其他请求,在Cookie中竟然都没有创建过ASP.NET_SessionID
那怎么办呢?
那我自己写一个吧:
requests.utils.add_dict_to_cookiejar(session.cookies,{"ASP.NET_SessionId":"0ftp4drb5uar0r55urffkobr"})
哎呀,成功了。开心,不过似乎ASP.NET_SessionId有时效性。
不管了,也不知道为啥Session.Cookies得不到所需要的Cookie,先不管了,各位大佬,发现问题的话,或者有啥好的解决办法麻烦告诉下!拜谢
代码地址:https://github.com/JackyWjx/HNCU下的HNCU.py
****************************************第二次更新********************************************************************************************************************************* 这个做法有问题呀:所以:我又来了。。。
经过学习cookie,意识到自己以前的一些错误,特来改正:
上篇对于ASP.NET_SessionId值不知道如何解决,只能自己添加
解决原理:既然ASP.NET_SessionId是一个cookie值,那么有一个请求的作用就是服务器设置ASP.NET_SessionId给浏览器,那么我们就直接拿到这个请求不就迎刃而解了
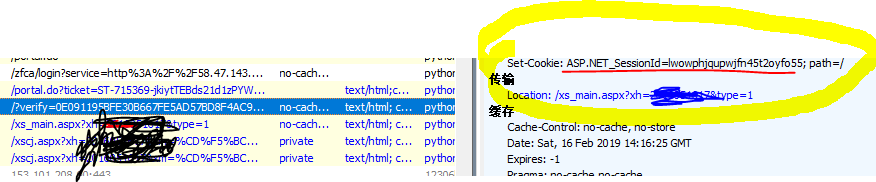
请求就知道了,那么请求这个请求就解决了,有由于我们的项目使用的requests那么也不需要设置啥了
代码地址:
https://github.com/JackyWjx/HNCU 下的HNCU-neW.py
python requests模拟登陆正方教务管理系统,并爬取成绩的更多相关文章
- python+requests模拟登陆 学校选课系统
最近学校让我们选课,每天都有不同的课需要选....然后突发奇想试试用python爬学校选课系统的课程信息 先把自己的浏览器缓存清空,然后在登陆界面按f12 如图: 可以看到登陆时候是需要验证码的,验证 ...
- python requests 模拟登陆网站,抓取数据
抓取页面数据的时候,有时候我们需要登陆才可以获取页面资源,那么我们需要登陆以后才可以跳转到对应的资源页面,那么我们需要通过模拟登陆,登陆成功以后再次去抓取对应的数据. 首先我们需要通过手动方式来登陆一 ...
- 【小白学爬虫连载(10)】–如何用Python实现模拟登陆网站
Python如何实现模拟登陆爬取Python实现模拟登陆的方式简单来说有三种:一.采用post请求提交表单的方式实现.二.利用浏览器登陆网站记录登陆成功后的cookies,采用get的请求方式,传入c ...
- python爬虫模拟登陆
python爬虫模拟登陆 学习了:https://www.cnblogs.com/chenxiaohan/p/7654667.html 用的这个 学习了:https://www.cnblogs.co ...
- Python脚本模拟登陆DVWA
目录 requests模拟登陆 Selenium自动化测试登陆 环境:python3.7 windows requests模拟登陆 我们登陆DVWA的时候,看似只有一步:访问网站,输入用户名和密码,登 ...
- Python requests模拟登录
Python requests模拟登录 #!/usr/bin/env python # encoding: UTF-8 import json import requests # 跟urllib,ur ...
- Python实现模拟登陆
大家经常会用Python进行数据挖掘的说,但是有些网站是需要登陆才能看到内容的,那怎么用Python实现模拟登陆呢?其实网路上关于这方面的描述很多,不过前些日子遇到了一个需要cookie才能登陆的网站 ...
- Requests模拟登陆
requests模拟登陆知乎网站 实例 # -*- coding: utf-8 -*- __author__ = 'CQ' import requests try: import cookielib ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
随机推荐
- 高斯消元与行列式求值 part1
两道模板题,思路与算法却是相当经典. 先说最开始做的行列式求值,题目大致为给一个10*10的行列式,求其值 具体思路(一开始看到题我的思路): 1.暴算,把每种可能组合试一遍,求逆序数,做相应加减运算 ...
- Spring Boot学习总结四
利用阿里的druid来管理数据库连接池,在此数据上针对多数据源的情况,做下讲解.首先加上该包 <dependency> <groupId>com.alibaba</gro ...
- ORA-00923: FROM keyword not found where expected(单双引号)
1.前提 在学习oracel的过程中遇到的一个关于单双引号的问题 备注一下 2.学习过程中创建表语句是这样的 create table DEPT_DML --部门表( DEPT_NO NUMBER(8 ...
- 记录下扣jio的2018年
踩着18年的尾巴,写下这篇总结,既给18年画上句号,也展望19年,制定下计划. 自17年底正式接手团队项目管理工作以来,虽然前面一年都干了大部分工作,但正式走到这个位置上来,还是有一部分的期待.接手之 ...
- STL初始化initializer_list
#include <iostream> #include <stdio.h> #include <stdlib.h> #include <string.h&g ...
- html中设置锚点定位
1.使用id定位: (这样的定位可以针对任何标签来定位. ) <a name="1F" href="#1F">锚点1</a> <d ...
- wpf编写一个简单的PDF转换的程序
wpf 调用Spire.Pdf将PDF文件转换为其他文件模式 首先在Nuget里下载该第三方包Spire.Pdf. 然后可以编写程序 //这里我调用的是解析成流模式,这是因为我要使用ProgressB ...
- CSS3总结一:border(边框)
Border-CSS1的属性 Border-CSS1:border Border-CSS1:border-style Border-CSS1:border-width Border-CSS1:bord ...
- iptables 防火墙日常
. 检查机目标机器 httpd 服务/etc/init.d/httpd status ========================================================= ...
- 域 搭建OU 组织单元
以这个界面开始操作: 在 baidu.com 右键---新建----组织单位----北京分公司 在 baidu.com 右键---新建----组织单位----北京分公司 在北京分公司 和南京分公司下面 ...