利用Python实现12306爬虫--查票
在上一篇文章(http://www.cnblogs.com/fangtaoa/p/8321449.html)中,我们实现了12306爬虫的登录功能,接下来,我们就来实现查票的功能.
其实实现查票的功能很简单,简单概括一下我们在浏览器中完成查票时的主要步骤:
1.从哪一站出发
2.终点站是哪里
3.然后选定乘车日期
既然我们已经知道是这个步骤了,那我们应该怎样通过程序的形式来实现这个步骤呢?
最主要的问题:
1.在程序中我们如何获取站点.不妨想一下,选择的站点是全都保存到一个文件中,还是分开的?
2.乘车日期是不是不能小于当前系统时间而且也不能大于铁路局规定的预售期(一般是30天左右)
好了,到目前为止,我们主要的问题是如何解决上面两个问题!
首先我们要明白一点:车票信息是通过异步加载的方式得到的
我们先看一下查票的URL:
出发日期:2018-02-22, 出发地:深圳,目的地:北京
https://kyfw.12306.cn/otn/leftTicket/queryZ?
leftTicketDTO.train_date=2018-02-22&
leftTicketDTO.from_station=SZQ&
leftTicketDTO.to_station=BJP&
purpose_codes=ADULT
我们重点关注2个字段:
1.from_station=SZQ
2.to_station=BJP
问题来了:我们明明选择了出发地是:深圳,目的地:北京,那么在from_station中为什么是SZQ,to_station中是BJP?
from_station和to_station的值好像不是深圳和北京被加密后的值,而是和他们的汉语拼音首字母有点联系
那我们做一个大胆的猜测:12306网站那边应该是把每个站点都与一个唯一的站点代码建立起了关联!
通过以上分析,我们就有更加明确的目标去进行抓包(抓包这次使用Chrome中的工具)!
我们填好所有必要信息时,点击查询按钮,得到的结果如下:
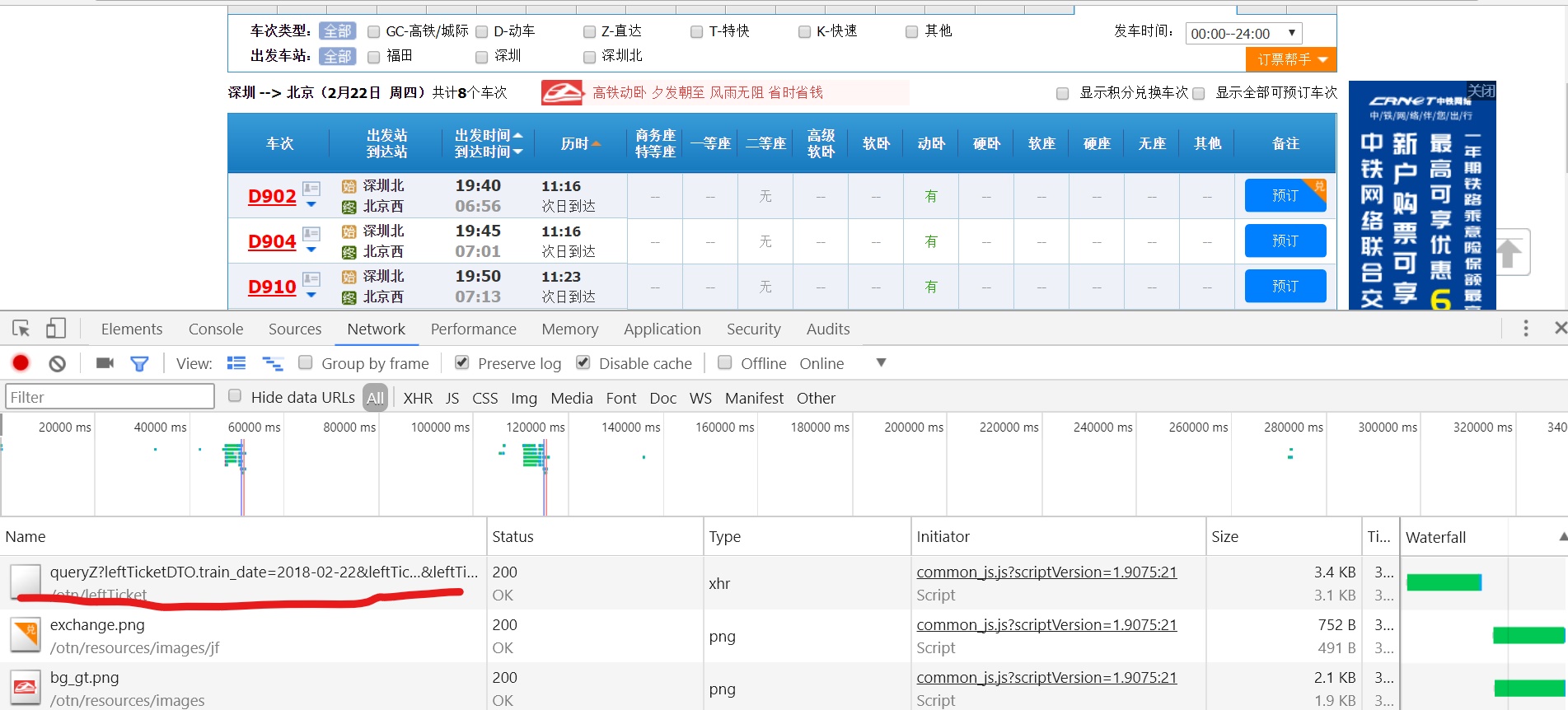
在所有结果中我们只看到了3条信息,最主要的还是第一条,我们看看里面的结果是什么
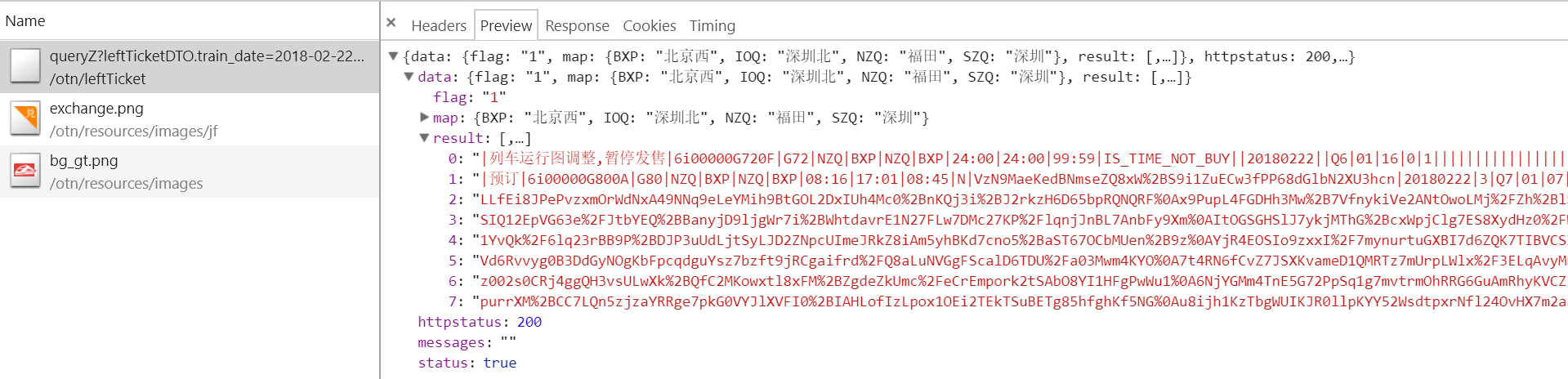
很明显我们得到从深圳到北京的所有车次信息了!
其他两个结果都是图片,不可能是站点啊,找不到站点信息,这可怎么办?


 ┓( ´-` )┏
┓( ´-` )┏
那我们点击刷新按钮来看看会出现什么结果
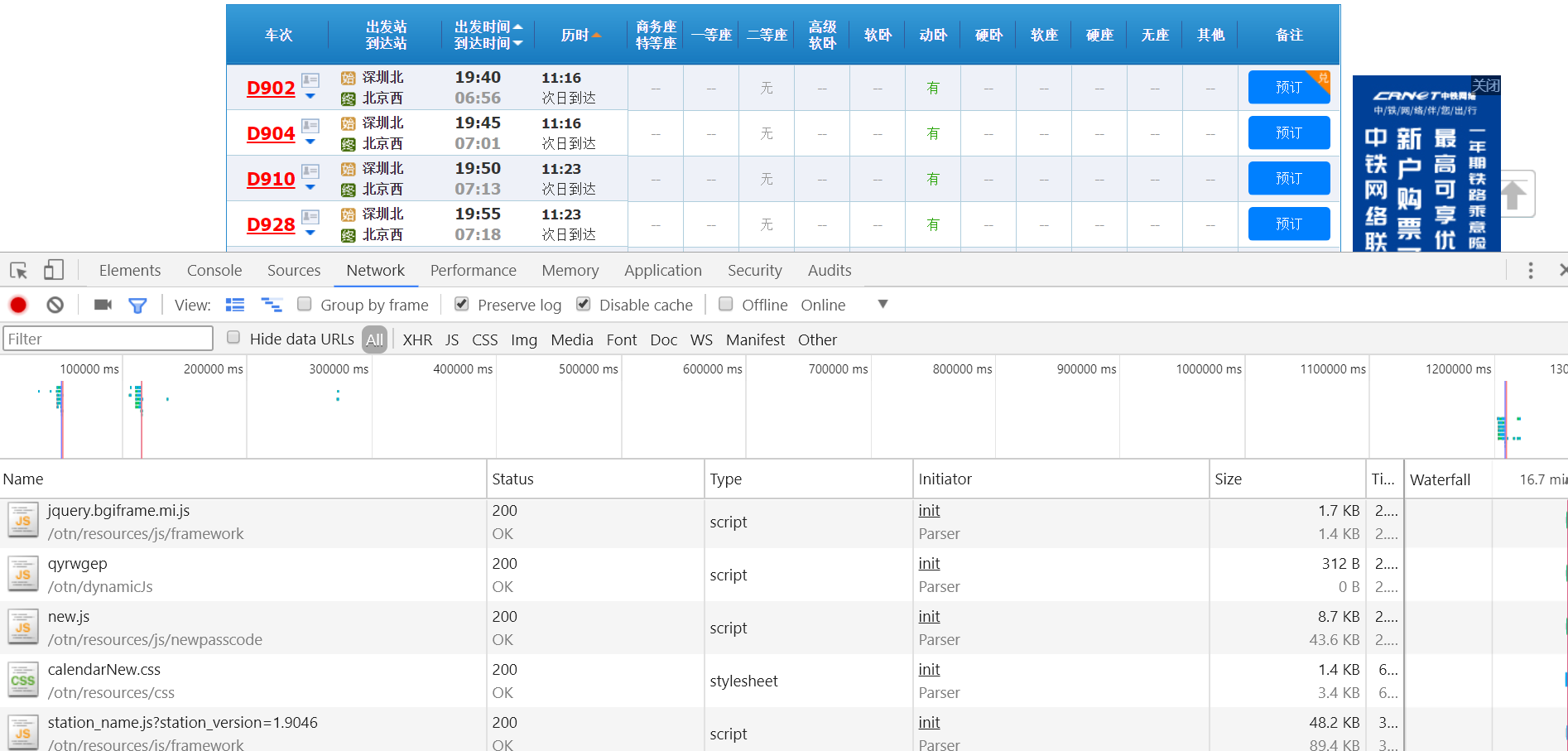
这次好像有好多东西出来了,那我们运气会不会好一点,能找到一些站点信息呢?
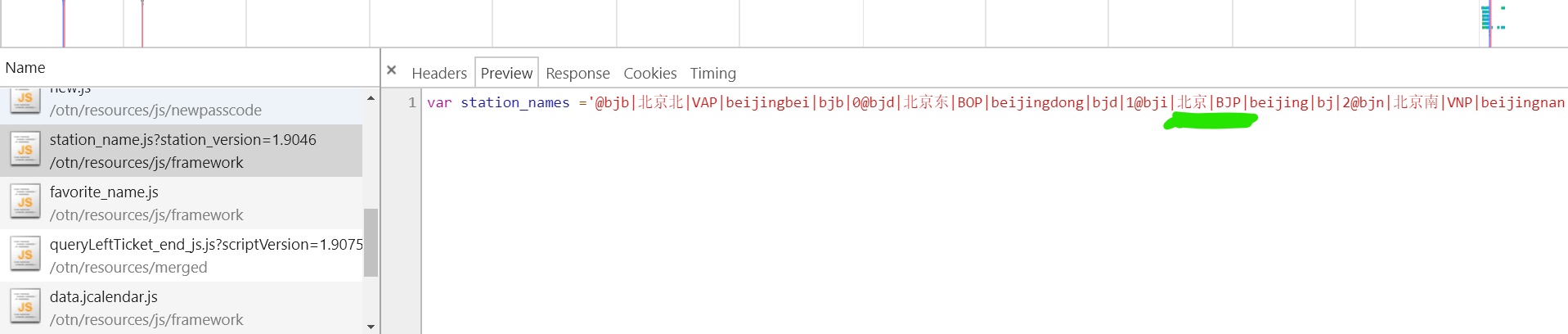
哦,好像我们发现了什么东西!!!!!!
在station_name.js中我们看到了熟悉的字段:BJP,那就让我们的这里面探索探索吧!!!
那么目前为止我们的工作就只剩下代码的事情了
我们只要两个请求就好了:
1.用GET请求把station_name.js中的数据全都获取到,并保存到文件中,我们需要用到,而且最好是以字典的格式保存
2.同样用GET请求去获取查票的URL,看看有出发地到目的地有哪些车次信息.
项目结构:
完整的代码如下:
from login import Login
import os
import json
import time
from collections import deque, OrderedDict class Station:
""" 查询车票信息 """ def __init__(self):
# 使用登录时候的session,这样好一些!
self.session = Login.session
self.headers = Login.headers def station_name_code(self):
"""
功能:获取每个站点的名字和对应的代码,并保存到本地
:return: 无
"""
filename = 'station_name.txt' url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js'
resp = self.session.get(url, headers=self.headers)
if resp.status_code == 200:
print('station_name_code():获取站点信息成功!')
with open(filename, 'w') as f:
for each in resp.text.split('=')[1].split('@'):
if each != "'":
f.write(each)
f.write('\n')
else:
print('station_name_code() error! status_code:{}, url: {}'
.format(resp.status_code, resp.url)) def save_station_code(self, filename):
"""
功能:从站点文件中提取站点与其对应的代码,并保存到文件中
:return:
""" if not os.path.exists(filename):
print('save_station_code():',filename,'不存在,正在下载!')
self.station_name_code() file = 'name_code.json'
name_code_dict = {}
with open(filename, 'r') as f:
for line in f:
# 对读取的行都进行split操作,然后提取站点名和其代码
name = line.split('|')[1] # 站点名字
code = line.split('|')[2] # 每个站点对应的代码
# 每个站点肯定都是唯一的
name_code_dict[name] = code # 把name,code保存到本地文件中,方便以后使用
with open(file, 'w') as f:
# 不以ascii码编码的方式保存
json.dump(name_code_dict, f, ensure_ascii=False) def query_ticket(self):
"""
功能:查票操作
:return: 返回查询到的所有车次信息
""" data = self._query_prompt()
if not data:
print('query_ticket() error: {}'.format(data))
_, from_station, to_station = data.keys()
train_date = data.get('train_date')
from_station_code = data.get(from_station)
to_station_code = data.get(to_station) query_param = 'leftTicketDTO.train_date={}&' \
'leftTicketDTO.from_station={}&' \
'leftTicketDTO.to_station={}&' \
'purpose_codes=ADULT'\
.format(train_date, from_station_code, to_station_code) url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?' full_url = url + query_param
resp = self.session.get(full_url, headers=self.headers)
if resp.status_code == 200 and resp.url == full_url:
print('query_ticket() 成功!然后进行车票清理工作!')
self._get_train_info(resp.json(), from_station, to_station) else:
print('query_ticket() error! status_code:{}, url:{}\norigin_url:{}'
.format(resp.status_code, resp.url, full_url)) def _get_train_info(self, text, from_station, to_station):
"""
功能:提取出查询到的列车信息
:param text: 包含所有从起点站到终点站的车次信息
:return: 返回所有车次信息
"""
if not text:
print('_query_train_info() error: text为:', text)
# 把json文件转变成字典形式
result = dict(text)
# 判断有无车次的标志
if result.get('data').get('map'):
train_info = result.get('data').get('result')
train_list = deque()
for item in train_info:
split_item = item.split('|')
item_dict= {}
for index, item in enumerate(split_item,0):
print('{}:\t{}'.format(index, item))
if split_item[11] == 'Y': # 已经开始卖票了
item_dict['train_name'] = split_item[3] # 车次名
item_dict['depart_time'] = split_item[8] # 出发时间
item_dict['arrive_time'] = split_item[9] # 到站时间
item_dict['spend_time'] = split_item[10] # 经历时长
item_dict['wz'] = split_item[29] # 无座
item_dict['yz'] = split_item[28] # 硬座
item_dict['yw'] = split_item[26] # 硬卧
item_dict['rw'] = split_item[23] # 软卧
item_dict['td'] = split_item[32] # 特等座
item_dict['yd'] = split_item[31] # 一等座
item_dict['ed'] = split_item[30] # 二等座
item_dict['dw'] = split_item[33] # 动卧
train_list.append(item_dict)
# 无法买票的车次,有可能是已卖光,也有可能是还不开卖
elif split_item[0] == '':
print('_query_train_info():车次{}的票暂时不能购买!'
.format(split_item[3]))
else:
print('_query_train_info():车次{}还未开始卖票,起售时间为:{}'
.format(split_item[3], split_item[1]))
# 调用方法来打印列车结果
self._print_train(train_list, from_station, to_station)
else:
print('_get_train_info() error: 从{}站到{}站有没列车!'
.format(from_station, to_station)) def _print_train(self, train_info, from_station, to_station):
"""
功能:打印查询到的车次信息
:param train_info: 提取出来的车次信息
:return:
""" if not train_info:
print('_print_train() error: train_info是None!')
return print('从{}到{}还有余票的列车有:'.format(from_station, to_station))
for item in train_info:
if 'G' in item['train_name']: # 高铁
self._print_high_train_info(item)
elif 'D' in item['train_name']: # 动车
self._print_dong_train_info(item)
else:
self._print_train_info(item) def _print_high_train_info(self, item):
"""
功能:打印高铁车次信息
:param item: 所有高铁车次
:return:
"""
print('车次:{:4s}\t起始时间:{:4s}\t到站时间:{:4s}\t'
'经历时长:{:4s}\t特等座:{:4s}\t一等座:{:4s}\t二等座:{:4s}'
.format(item['train_name'], item['depart_time'],item['arrive_time'],
item['spend_time'],item['td'], item['yd'], item['ed'])) def _print_dong_train_info(self, item):
"""
功能:打印动车的车票信息
:param item: 所有动车车次
:return:
"""
print('车次:{:4s}\t起始时间:{:4s}\t到站时间:{:4s}\t'
'经历时长:{:4s}\t一等座:{:4s}\t二等座:{:4s}\t软卧:{:4s}\t动卧:{:4s}'
.format(item['train_name'], item['depart_time'], item['arrive_time'],
item['spend_time'],item['yd'],item['ed'], item['rw'], item['dw']))
def _print_train_info(self,item):
"""
功能:打印普通列出的车次信息
:param item: 所有普通车次
:return:
"""
print('车次:{:4s}\t起始时间:{:4s}\t到站时间:{:4s}\t经历时长:{:4s}\t'
'软卧:{:4s}\t硬卧:{:4s}\t硬座:{:4s}\t无座:{:4s}'
.format(item['train_name'], item['depart_time'], item['arrive_time'],
item['spend_time'],item['rw'], item['yw'], item['yz'], item['wz']))
def _query_prompt(self):
"""
功能: 与用户交互,让用户输入:出发日期,起始站和终点站并判断其正确性
:return: 返回正确的日期,起始站和终点站
""" time_flag, train_date = self._check_date()
if not time_flag:
print('_query_prompt() error:', '乘车日期不合理,请检查!!')
return
# 创建有序字典,方便取值
query_data = OrderedDict()
from_station = input('请输入起始站:')
to_station = input('请输入终点站:') station_flag = True
filename = 'name_code.json'
with open(filename, 'r') as f:
data = dict(json.load(f))
stations = data.keys()
if from_station not in stations or to_station not in stations:
station_flag = False
print('query_prompt() error: {}或{}不在站点列表中!!'
.format(from_station, to_station))
# 获取起始站和终点站的代码
from_station_code = data.get(from_station)
to_station_code = data.get(to_station)
query_data['train_date'] = train_date
query_data[from_station] = from_station_code
query_data[to_station] = to_station_code if time_flag and station_flag:
return query_data
else:
print('query_prompt() error! time_flag:{}, station_flag:{}'
.format(time_flag, station_flag)) def _check_date(self):
"""
功能:检测乘车日期的正确性
:return: 返回时间是否为标准的形式的标志
""" # 获取当前时间的时间戳
local_time = time.localtime()
local_date = '{}-{}-{}'.\
format(local_time.tm_year, local_time.tm_mon, local_time.tm_mday)
curr_time_array = time.strptime(local_date, '%Y-%m-%d')
curr_time_stamp = time.mktime(curr_time_array)
# 获取当前时间
curr_time = time.strftime('%Y-%m-%d', time.localtime(curr_time_stamp)) # 计算出预售时长的时间戳
delta_time_stamp = ''
# 算出预售票的截止日期时间戳
dead_time_stamp = int(curr_time_stamp) + int(delta_time_stamp)
dead_time = time.strftime('%Y-%m-%d', time.localtime(dead_time_stamp))
print('合理的乘车日期范围是:({})~({})'.format(curr_time, dead_time)) train_date = input('请输入乘坐日期(year-month-day):')
# 把乘车日期转换成时间戳来比较
# 先生成一个时间数组
time_array = time.strptime(train_date, '%Y-%m-%d')
# 把时间数组转化成时间戳
train_date_stamp = time.mktime(time_array)
# 获取标准的乘车日期
train_date_time = time.strftime('%Y-%m-%d', time.localtime(train_date_stamp))
# 做上面几步主要是把用户输入的时间格式转变成标准的格式
# 如用户输入:2018-2-22,那么形成的查票URL就不是正确的
# 只有是: 2018-02-22,组合的URL才是正确的!
# 通过时间戳来比较时间的正确性
if int(train_date_stamp) >= int(curr_time_stamp) and \
int(train_date_stamp) <= dead_time_stamp:
return True, train_date_time
else:
print('_check_date() error: 乘车日期:{}, 当前系统时间:{}, 预售时长为:{}'
.format(train_date_time, curr_time, dead_time))
return False, None def main():
filename = 'station_name.txt'
station = Station()
station.station_name_code()
station.save_station_code(filename)
station.query_ticket() if __name__ == '__main__':
main()
小结:在查票功能中,其实没有太多复杂的东西,不想前面登录时需要发送多个请求,在这个功能中只要发送两个请求就可以了,主要复杂的地方在于对数据的清理工作!
利用Python实现12306爬虫--查票的更多相关文章
- python之12306自动查票
一.导读 本篇文章所采用的技术仅用于学习.研究,任何其他用途请自行承担后果. 12306自动查票使用到的python库主要是splinter,同时也涉及到查票的城市编码,具体的城市编码请在网络上搜 ...
- Python实现12306自动查票程序
这是在网上扒拉过来的,原文链接: http://blog.csdn.net/An_Feng_z/article/details/78631290 目前时间2018/01/04 文中各种接口均为可用,亲 ...
- 利用Python攻破12306的最后一道防线
各位同学大家好,我是强子,好久没跟大家带来最新的技术文章了,最近有好几个同学问我12306自动抢票能否实现,我就趁这两天有时间用Python做了个12306自动抢票的项目,在这里我来带着大家一起来看看 ...
- 利用Python编写网络爬虫下载文章
#coding: utf-8 #title..href... str0='blabla<a title="<论电影的七个元素>——关于我对电影的一些看法以及<后会无期 ...
- Python实例--12306的抢票功能
基础知识学习 目标: 通过python程序实现自动登录下单功能 知识点: Selenium + 云打码 + Python 学习链接: 1. Python学习--Selenium模块 2. Python ...
- 利用python实现新浪微博爬虫
第一个模块,模拟登陆sina微博,创建weiboLogin.py文件,输入以下代码: #! /usr/bin/env python # -*- coding: utf-8 -*- import sys ...
- vue+node+mongoDB火车票H5(七)-- nodejs 爬12306查票接口
菜鸟一枚,业余一直想做个火车票查票的H5,前端页面什么的已经写好了,node+mongoDB 也写了一个车站的接口,但 接下来的爬12306获取车次信息数据一直卡住,网上的爬12306的大部分是pyt ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
随机推荐
- 哈夫曼编码(Huffman coding)的那些事,(编码技术介绍和程序实现)
前言 哈夫曼编码(Huffman coding)是一种可变长的前缀码.哈夫曼编码使用的算法是David A. Huffman还是在MIT的学生时提出的,并且在1952年发表了名为<A Metho ...
- Android开发之旅2:HelloWorld项目的目录结构
引言 前面Android开发之旅:环境搭建及HelloWorld,我们介绍了如何搭建Android开发环境及简单地建立一个HelloWorld项目,本篇将通过HelloWorld项目来介绍Androi ...
- mysql 查询每秒写入数据库的记录数
SELECT * from t_user ORDER BY create_time desc SELECT create_time, COUNT(create_time) as num from t ...
- cf444E. DZY Loves Planting(并查集)
题意 题目链接 Sol 神仙题啊Orzzzzzz 考场上的时候直接把树扔了对着式子想,想1h都没得到啥有用的结论. 然后cf正解居然是网络流??出给NOIP模拟赛T1???¥%--&((--% ...
- task16 表格增减笔记
trim()方法会创建一个字符串副本,删除前置及后缀所有空格,然后返回结果(中间的空格符无法消除) match()方法可在字符串内检索指定的值,找到一个或多个正则表达式的匹配 正则表达式 匹配中文:[ ...
- Aspose.cells常用用法1
代码: var execl_path = @"G:\zhyue\backup\项目修改-工作日常\2018-11-12 区域楼盘中心点和放大比例计算\a.xlsx"; Workbo ...
- OpenGL学习--开发环境
1. VS2017 Professional安装 1.1. 下载 mu_visual_studio_professional_2017_x86_x64_10049787.exe 1.2. 双击开始安装 ...
- socat 的神奇使用方式
目的是实现科* 学 * 上*网,现在记录一下流程 先在服务器上安装(比如美国,香港,台湾,马来的云主机)squid,easy_rsa, centos 下可以用yum直接安装 $ yum install ...
- 树莓派raspberry Pi2 介绍
Compared to the Raspberry Pi 1 it has: A 900MHz quad-core ARM Cortex-A7 CPU 1GB RAM Like the (Pi 1) ...
- linux/OSX中“DD”命令制作ISO镜像操作系统安装U盘
linux或者OS X系统中,使用“dd”命令可以直接在终端命令行模式下,制作ISO镜像的系统安装盘. 一.linux系统以centOS7为例. sudo dd if=镜像路径 of=USB设备路径 ...