NLP Attention
一、概述
自动摘要可以从很多角度进行分类,例如单文档摘要/多文档摘要、单语言摘要/跨语言摘要等。从技术上说,普遍可以分为三类:
i. 抽取式摘要(extractive),直接从原文中抽取一些句子组成摘要。本质上就是个排序问题,给每个句子打分,将高分句子摘出来,再做一些去冗余(方法是MMR)等。这种方式应用最广泛,因为比较简单,比如博客园的博客摘要就是前面几句话。经典方法有LexRank和整数线性规划(ILP)。
LexRank是将文档中的每个句子都看作节点,句子之间的相似度看作节点之间的边的权重,构建一个graph;然后再计算每个节点的分数,这个打分的计算方式可以是度中心度(Degree centrality)、PageRank中心度等(论文里说这两种计算方式其实效果没有太大差别,文中用的ROUGE-1作为指标);这个方法的要点在于:不能每两个句子之间都有边,要设定一个阈值,只有相似度大于这个阈值才能有边,阈值太大则丢失太多信息,阈值太小则又引入了太多噪声。论文里说0.1比较合适,我们之前做过的实验结果和这个是一致的。
ii. 压缩式摘要(compressive),有两种方式:一种是pipeline,先抽取出句子,再做句子压缩,或者先做句子压缩,再抽句子。另一种是jointly的方式,抽句子和压缩句子这两个过程是同时进行的。
句子压缩(Sentence compression)的经典方法是ILP:句子中的每个词都对应一个二值变量表示该词是否保留,并且每个词都有一个打分(比如tf-idf),目标函数就是最大化句子中的词的打分;既然是规划那当然要给出限制,最简单的限制比如说至少保留一个词,再比如说当形容词被保留时其修饰的词也要保留(根据parse tree)。
iii. 理解式摘要(abstractive),也叫产生式摘要,试图理解原文的意思,然后生成摘要,也就是像我们人做摘要那样来完成任务。
二、评价指标
首先可以是人工评价。这里只介绍自动评价。目前来说,自动评价指标采用的是ROUGE,R是recall的意思,换句话说,这个指标基于摘要系统生成的摘要与参考摘要的n元短语重叠度:
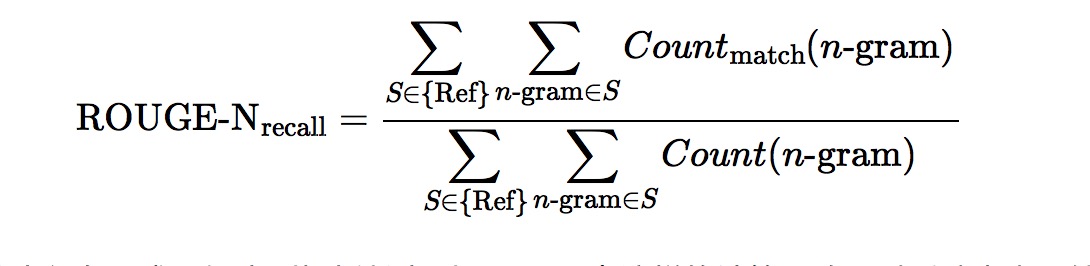
摘要这个任务要求用短序列概括长序列,用召回率这样的计算思路可以反映出人工给出的参考摘要所列出的要点中有多少被包含在了机器生成的摘要中。这个指标用来应付抽取式摘要可能问题不大,但是由于其无法评价所生成摘要的语法和语义,而且倾向于长摘要,所以其实还应该继续探索更合理的指标来评价理解式摘要。此外,当然也可以计算基于precision的ROUGE,而且ROUGE还有ROUGE-L等多种版本;最常使用的是ROUGE-N的N取2的方式(也就是ROUGE-2)。评测工具的链接是这里。
三、使用seq2seq + attention机制,生成理解式摘要
前面简略介绍了一些概念(还差语料没介绍,后面随着说实验时再说吧)。下面就开始介绍我精读的前两篇文章:
[1] A Neural Attention Model for Abstractive Sentence Summarization,2015EMNLP
[2] Abstractive Sentence Summarization with Attentive Recurrent Neural Networks,2016NAACL
第二篇文章是第一篇文章所做工作的延续。它们所试图解决的是句子级别摘要问题:输入新闻的第一句话,试图生成新闻标题。至于为什么是一句话,主要还是因为就目前来看神经网络还不能很好地处理太长的序列。
由于自动摘要和机器翻译都属于“序列到序列”这个类型(输入的是序列,输出也是序列;但必须注意翻译和摘要这两个问题是非常不同的),因此这两篇文章将神经机器翻译中广泛使用的encoder-decoder框架和attention mechanism(注意力机制)引入到自动摘要问题,试图用这样一种fully data-driven的方式,端到端地训练出自动摘要模型。
首先简要介绍一些概念。
1. Sequence to sequence learning 与 encoder-decoder框架
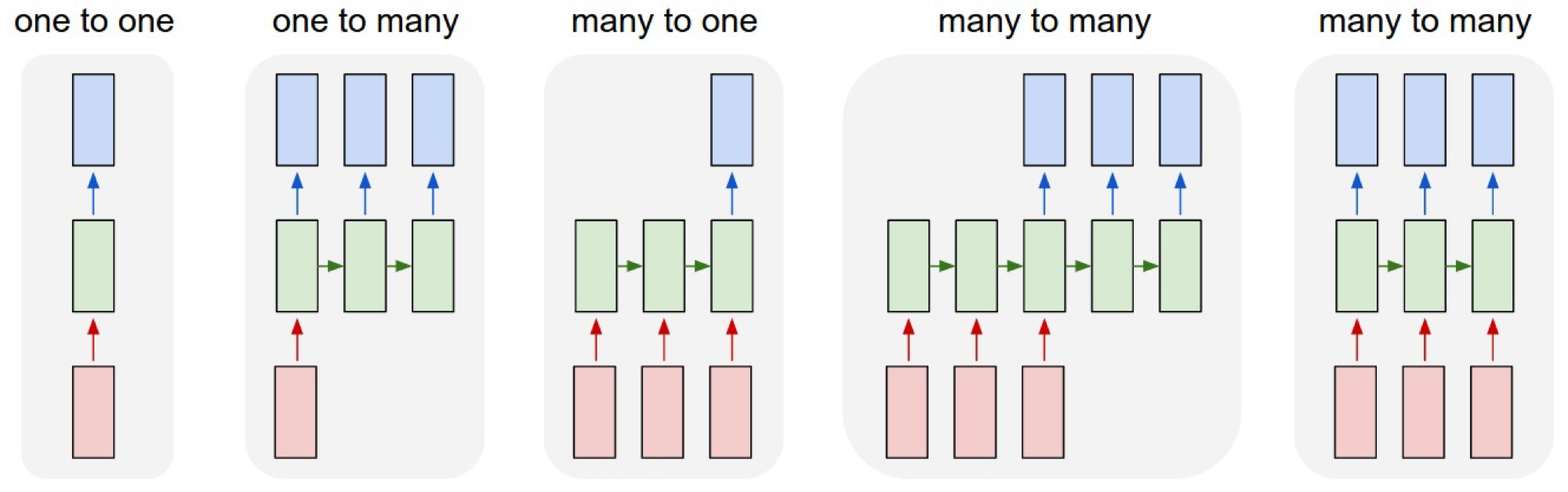
如果只说“序列到序列”的话,那么词性标注(POS)其实也是这样的过程。但是它跟翻译、摘要显著不同的地方在于:在POS问题中,输入和输出是一一对应的,而翻译、摘要的输出序列与输入序列则没有显著的对应关系。所以如下图所示,POS问题可以用最右边的那个RNN结构来建模,每个时刻的输入与输出就是词与词性。相比之下,翻译、摘要这种则可以通过倒数第二张图那样的结构来解决,这个结构可以看作是encoder和decoder都是RNN的encoder-decoder框架。
encoder-decoder框架的工作机制是:先使用encoder,将输入编码到语义空间,得到一个固定维数的向量,这个向量就表示输入的语义;然后再使用decoder,将这个语义向量解码,获得所需要的输出,如果输出是文本的话,那么decoder通常就是语言模型。这种机制的优缺点都很明显,优点:非常灵活,并不限制encoder、decoder使用何种神经网络,也不限制输入和输出的模态(例如image caption任务,输入是图像,输出是文本);而且这是一个端到端(end-to-end)的过程,将语义理解和语言生成合在了一起,而不是分开处理。缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。
2. attention mechanism 注意力机制
为了解决上面提到的问题,一种可行的方案是引入attention mechanism。所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。谷歌博客里介绍神经机器翻译系统时所给出的动图形象地展示了attention:
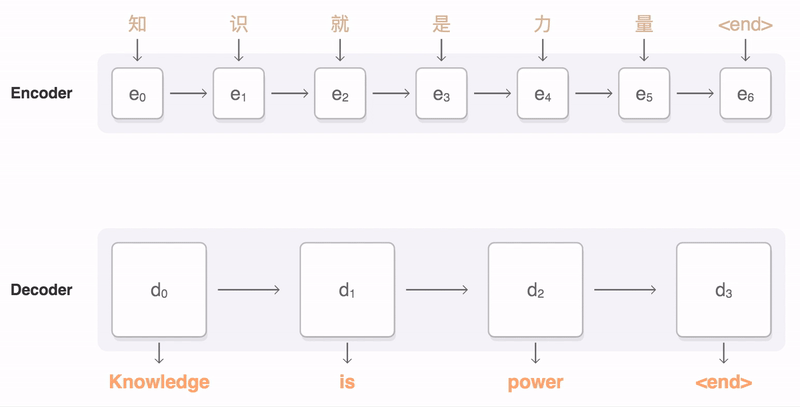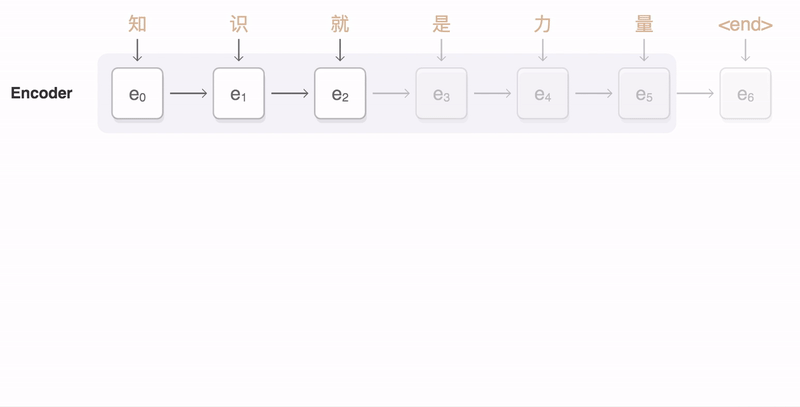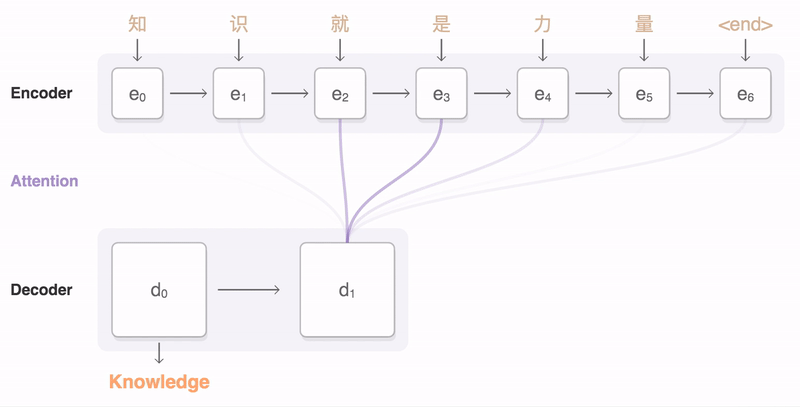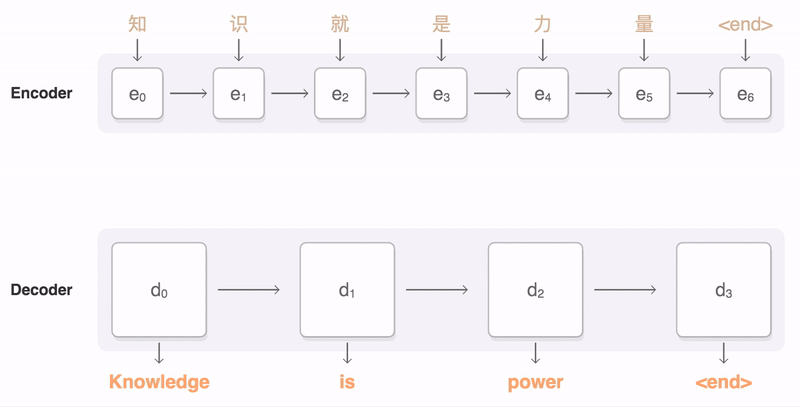
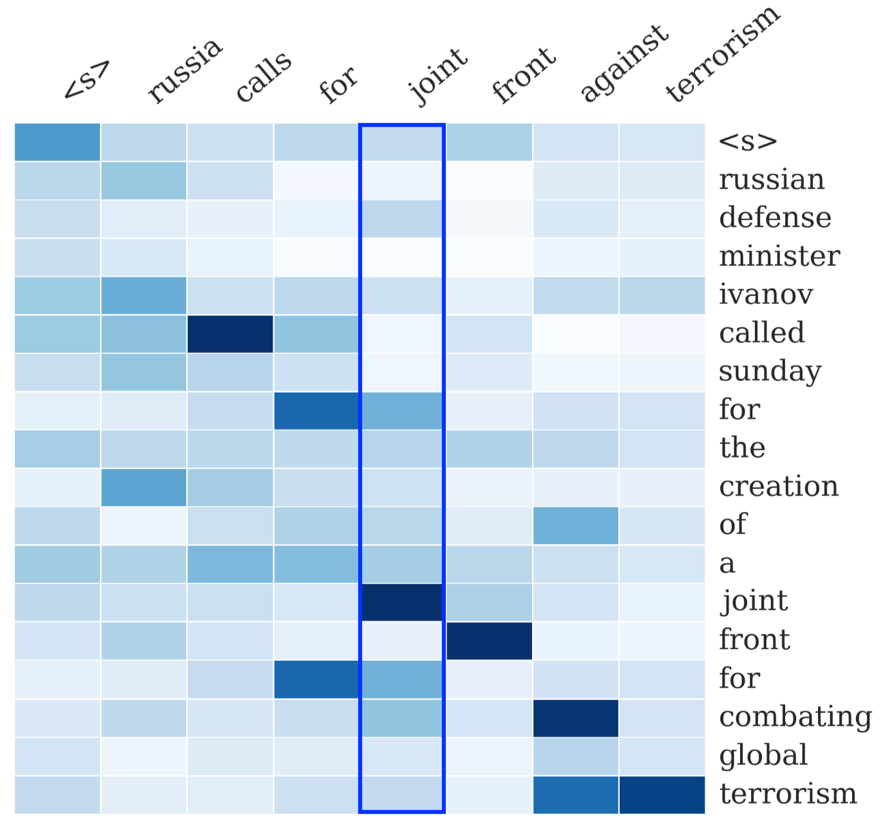
下图中的一张图也展示了这一点:右侧序列是输入序列,上方序列是输出序列。输出序列的每个词都对应一个概率分布,这个概率分布决定了在生成这个词的时候,对于输入序列的各个词的关注程度。如图所示,看蓝色框起来的那一列,就是模型在生成joint这个词时的概率分布,颜色最深的地方对应的是输入的joint,说明模型在生成joint这个词时最为关注的输入词是joint。所谓attention,就是说生成每个词时都为这个词得到这个概率分布,进而可以使生成的词“更好”——用一个词概括,那就是,“对齐”。
3. 实现
下面主要介绍 [2] 。刚才已经说过,文章解决的是句子级别的摘要问题,输入是一个词序列:x=[x1,x2,...,xM]x=[x1,x2,...,xM] ,每个词都是词表中的一个(记词表大小为 V ,低频词将被标为UNK);输出也是一个词序列:y=[y1,y2,...,yN]y=[y1,y2,...,yN] ,要求长度要短于输入,实际含义就是求出在本个句子中最大概率的词。模型的目标就是下式:
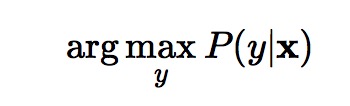
y 是随机变量,每个可能取值都是一个词序列。给定输入序列,生成某个输出序列的概率可以用下式建模:
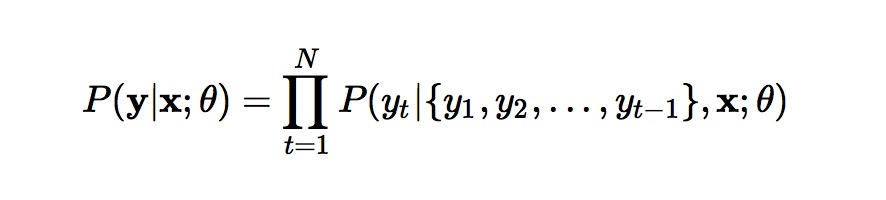

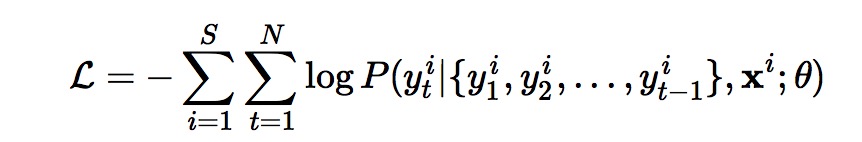
模型训练完成后,给定一个句子来生成摘要:由于每个词都有 V 种可能,如果每个长度为 N 个词的序列都计算一个概率再从中挑出最大的那个的话,代价太大。所以在生成摘要时采用的是beam search的方法:生成第一个词时只保留概率最大的 k 个词,然后生成第二个词时,从 Vk个可能的二元短语里只保留概率最大的 K个;依次类推,每生成一个词时都只保留K个。可以看出这种剪枝操作大大缩小了搜索空间,如果 K=1 ,就相当于是一种贪心的策略。beam search原先是统计机器翻译里缩小短语对译时的搜索空间的一种策略,这里把其中的思路借用了过来。
下面就介绍如何建模条件概率。
(1) decoder:RNN-based
这里建模条件概率时使用的是RNNLM。与传统的基于n-gram假设的语言模型不同,RNNLM最大的优势就是在 t 时刻生成一个词时可以利用到此前全部的上文信息,而不是只能利用此前 n−1 个时刻的信息。
懒得打字了,直接上图了。。。dd 是隐层神经元个数,Ct 就是当前时刻encoder的输出,decoder在每个时刻进行解码都将编码向量 Ct 作为输入,而不是只在首个时刻引入。一个值得注意的地方是,本文给出的模型在计算Pt 时,并没有显式输入 yt-1,而只在计算隐状态 htht时输入了yt-1 。
由于attention机制的存在,每个时刻生成词时对输入序列各个词的关注程度是不一样的,所以encoder在每个时刻给出的输出 Ct 是不一样的,具体如何计算将在下面马上介绍。
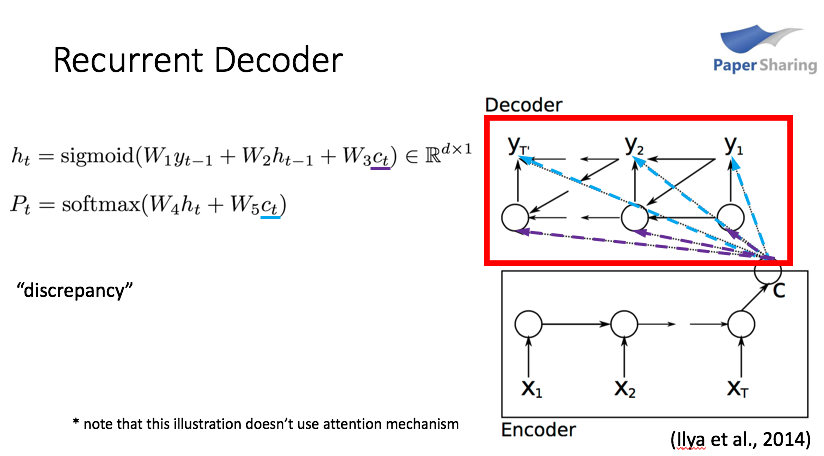
另外,论文中也使用了带LSTM单元的RNN,但是实验部分中介绍道效果并不如最基本的RNN,可能的原因是复杂的模型招致了过拟合。
(note:在 [1] 中,decoder部分用的是2003年Bengio的那个NPLM模型,在以前的博客中介绍过。)
(2) encoder:CNN-based + attention

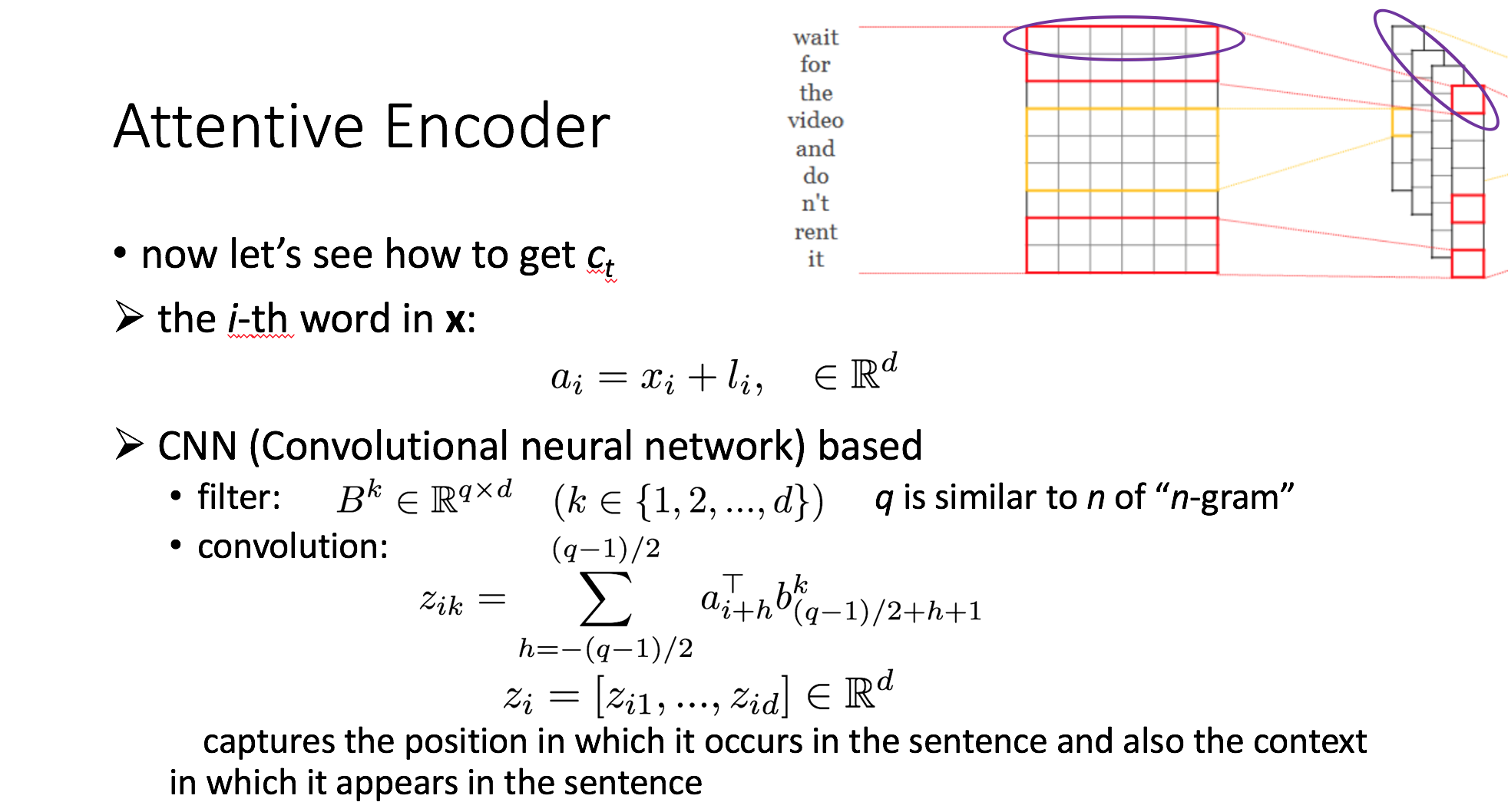


NLP Attention的更多相关文章
- [NLP/Attention]关于attention机制在nlp中的应用总结
原文链接: https://blog.csdn.net/qq_41058526/article/details/80578932 attention 总结 参考:注意力机制(Attention Mec ...
- (zhuan) Attention in Long Short-Term Memory Recurrent Neural Networks
Attention in Long Short-Term Memory Recurrent Neural Networks by Jason Brownlee on June 30, 2017 in ...
- Deep Learning基础--理解LSTM/RNN中的Attention机制
导读 目前采用编码器-解码器 (Encode-Decode) 结构的模型非常热门,是因为它在许多领域较其他的传统模型方法都取得了更好的结果.这种结构的模型通常将输入序列编码成一个固定长度的向量表示,对 ...
- 理解LSTM/RNN中的Attention机制
转自:http://www.jeyzhang.com/understand-attention-in-rnn.html,感谢分享! 导读 目前采用编码器-解码器 (Encode-Decode) 结构的 ...
- attention机制的实现
本文转自,http://www.jeyzhang.com/understand-attention-in-rnn.html,感谢分享! LSTM 中实现attention:https://distil ...
- 13.深度学习(词嵌入)与自然语言处理--HanLP实现
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 13. 深度学习与自然语言处理 13.1 传统方法的局限 前面已经讲过了隐马尔可夫 ...
- 初识Attention机制(NLP领域)
Attention 机制. 参考:https://blog.csdn.net/xiewenbo/article/details/79382785 要是关注深度学习在自然语言处理方面的研究进展,我相信你 ...
- 注意力机制(Attention Mechanism)应用——自然语言处理(NLP)
近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了最近神经网络研究的一个热点,下面是一些基于attention机制的神经网络在 ...
- NLP学习(5)----attention/ self-attention/ seq2seq/ transformer
目录: 1. 前提 2. attention (1)为什么使用attention (2)attention的定义以及四种相似度计算方式 (3)attention类型(scaled dot-produc ...
随机推荐
- MyEclipse2014中Java类右键Run as没有JUnit Test
Java初学,想试试连接本地数据库,按照百度经验中的方法,在最后执行测试的卡住了,为啥?因为MyEclipse中右键Run as没有JUnit Test选项! 6.1.测试数据库mysql是在项目中连 ...
- Eclipse的使用技巧
Eclipse有强大的编辑功能, 工欲善其事,必先利其器, 掌握Eclipse快捷键,可以大大提高工作效率. 小坦克我花了一整天时间, 精选了一些常用的快捷键操作,并且精心录制了动画, 让你一看就会. ...
- hdu 4268 贪心+set lower_bound用法
http://acm.hdu.edu.cn/showproblem.php?pid=4268 A想用手里的牌尽量多地覆盖掉B手中的牌.. 牌有h和w 问A手中的牌最多能覆盖B多少张牌 iterator ...
- visual studio 2015 rc &cordova -hello world
初始环境,用来看看书,电影,上上网的win8,所以一切从头开始. 1,首先还是装visual studio 2015 rc吧,目前只放出在线安装,所以要很长很长时间.不过有新闻说很快要实现中国网友至 ...
- Angular6 学习笔记——指令
angular6.x系列的学习笔记记录,仍在不断完善中,学习地址: https://www.angular.cn/guide/template-syntax http://www.ngfans.net ...
- .net core An assembly specified in the application dependencied mainfest<****.json>was not found解决办法
最近在开发项目中,遇到了一个问题.在本机开发中部署到本机iis上或者本机控制台都没有问题,运行正常.当发布部署到服务器(windowsServer)中的时候一直运行不起来,用控制台也运行不起来,直接报 ...
- 解决vs2015引用时没有Report Viewer的问题
1.选择“工具”>“Nuget包管理器”>“程序包管理器控制台” 执行命令:Install-Package Microsoft.ReportingServices.ReportViewer ...
- php CI框架log写入
1.首先,打开application下的config.php文件,将log配置打开如下 /* |---------------------------------------------------- ...
- 【转】Lucene工作原理——反向索引
原文链接: http://my.oschina.net/wangfree/blog/77045 倒排索引 倒排索引(反向索引) 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项 ...
- Day 27 类的进阶-反射
11. __new__ 和 __metaclass__ 阅读以下代码: 1 2 3 4 5 6 class Foo(object): def __init__(self): pass obj = Fo ...